mirror of
https://gitgud.io/reanon/nonono.git
synced 2026-05-10 23:40:12 -07:00
lmao (glm+qwen newest addition)
This commit is contained in:
@@ -0,0 +1,34 @@
|
||||
*.7z filter=lfs diff=lfs merge=lfs -text
|
||||
*.arrow filter=lfs diff=lfs merge=lfs -text
|
||||
*.bin filter=lfs diff=lfs merge=lfs -text
|
||||
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
||||
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
||||
*.ftz filter=lfs diff=lfs merge=lfs -text
|
||||
*.gz filter=lfs diff=lfs merge=lfs -text
|
||||
*.h5 filter=lfs diff=lfs merge=lfs -text
|
||||
*.joblib filter=lfs diff=lfs merge=lfs -text
|
||||
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
||||
*.model filter=lfs diff=lfs merge=lfs -text
|
||||
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
||||
*.npy filter=lfs diff=lfs merge=lfs -text
|
||||
*.npz filter=lfs diff=lfs merge=lfs -text
|
||||
*.onnx filter=lfs diff=lfs merge=lfs -text
|
||||
*.ot filter=lfs diff=lfs merge=lfs -text
|
||||
*.parquet filter=lfs diff=lfs merge=lfs -text
|
||||
*.pb filter=lfs diff=lfs merge=lfs -text
|
||||
*.pickle filter=lfs diff=lfs merge=lfs -text
|
||||
*.pkl filter=lfs diff=lfs merge=lfs -text
|
||||
*.pt filter=lfs diff=lfs merge=lfs -text
|
||||
*.pth filter=lfs diff=lfs merge=lfs -text
|
||||
*.rar filter=lfs diff=lfs merge=lfs -text
|
||||
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
||||
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
||||
*.tflite filter=lfs diff=lfs merge=lfs -text
|
||||
*.tgz filter=lfs diff=lfs merge=lfs -text
|
||||
*.wasm filter=lfs diff=lfs merge=lfs -text
|
||||
*.xz filter=lfs diff=lfs merge=lfs -text
|
||||
*.zip filter=lfs diff=lfs merge=lfs -text
|
||||
*.zst filter=lfs diff=lfs merge=lfs -text
|
||||
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
||||
+11
@@ -0,0 +1,11 @@
|
||||
.aider*
|
||||
.env*
|
||||
!.env.vault
|
||||
.venv
|
||||
.vscode
|
||||
.idea
|
||||
build
|
||||
greeting.md
|
||||
node_modules
|
||||
.windsurfrules
|
||||
http-client.private.env.json
|
||||
@@ -0,0 +1,4 @@
|
||||
#!/usr/bin/env sh
|
||||
. "$(dirname -- "$0")/_/husky.sh"
|
||||
|
||||
npm run type-check
|
||||
+13
@@ -0,0 +1,13 @@
|
||||
{
|
||||
"plugins": ["prettier-plugin-ejs"],
|
||||
"overrides": [
|
||||
{
|
||||
"files": "*.ejs",
|
||||
"options": {
|
||||
"printWidth": 120,
|
||||
"bracketSameLine": true
|
||||
}
|
||||
}
|
||||
],
|
||||
"trailingComma": "es5"
|
||||
}
|
||||
@@ -0,0 +1,72 @@
|
||||
# OAI Reverse Proxy - just a shitty fork
|
||||
Reverse proxy server for various LLM APIs.
|
||||
|
||||
### Table of Contents
|
||||
<!-- TOC -->
|
||||
* [OAI Reverse Proxy](#oai-reverse-proxy)
|
||||
* [Table of Contents](#table-of-contents)
|
||||
* [What is this?](#what-is-this)
|
||||
* [Features](#features)
|
||||
* [Usage Instructions](#usage-instructions)
|
||||
* [Personal Use (single-user)](#personal-use-single-user)
|
||||
* [Updating](#updating)
|
||||
* [Local Development](#local-development)
|
||||
* [Self-hosting](#self-hosting)
|
||||
* [Building](#building)
|
||||
* [Forking](#forking)
|
||||
<!-- TOC -->
|
||||
|
||||
## What is this?
|
||||
This project allows you to run a reverse proxy server for various LLM APIs.
|
||||
|
||||
## Features
|
||||
- [x] Support for multiple APIs
|
||||
- [x] [OpenAI](https://openai.com/)
|
||||
- [x] [Anthropic](https://www.anthropic.com/)
|
||||
- [x] [AWS Bedrock](https://aws.amazon.com/bedrock/) (Claude4 is fucked, dont care)
|
||||
- [x] [Vertex AI (GCP)](https://cloud.google.com/vertex-ai/)
|
||||
- [x] [Google MakerSuite/Gemini API](https://ai.google.dev/)
|
||||
- [x] [Azure OpenAI](https://azure.microsoft.com/en-us/products/ai-services/openai-service)
|
||||
- [x] Translation from OpenAI-formatted prompts to any other API, including streaming responses
|
||||
- [x] Multiple API keys with rotation and rate limit handling
|
||||
- [x] Basic user management
|
||||
- [x] Simple role-based permissions
|
||||
- [x] Per-model token quotas
|
||||
- [x] Temporary user accounts
|
||||
- [x] Event audit logging
|
||||
- [x] Optional full logging of prompts and completions
|
||||
- [x] Abuse detection and prevention
|
||||
- [x] IP address and user token model invocation rate limits
|
||||
- [x] IP blacklists
|
||||
- [x] Proof-of-work challenge for access by anonymous users
|
||||
|
||||
## Usage Instructions
|
||||
If you'd like to run your own instance of this server, you'll need to deploy it somewhere and configure it with your API keys. A few easy options are provided below, though you can also deploy it to any other service you'd like if you know what you're doing and the service supports Node.js.
|
||||
|
||||
### Personal Use (single-user)
|
||||
If you just want to run the proxy server to use yourself without hosting it for others:
|
||||
1. Install [Node.js](https://nodejs.org/en/download/) >= 18.0.0
|
||||
2. Clone this repository
|
||||
3. Create a `.env` file in the root of the project and add your API keys. See the [.env.example](./.env.example) file for an example.
|
||||
4. Install dependencies with `npm install`
|
||||
5. Run `npm run build`
|
||||
6. Run `npm start`
|
||||
|
||||
#### Updating
|
||||
You must re-run `npm install` and `npm run build` whenever you pull new changes from the repository.
|
||||
|
||||
#### Local Development
|
||||
Use `npm run start:dev` to run the proxy in development mode with watch mode enabled. Use `npm run type-check` to run the type checker across the project.
|
||||
|
||||
### Self-hosting
|
||||
[See here for instructions on how to self-host the application on your own VPS or local machine and expose it to the internet for others to use.](./docs/self-hosting.md)
|
||||
|
||||
**Ensure you set the `TRUSTED_PROXIES` environment variable according to your deployment.** Refer to [.env.example](./.env.example) and [config.ts](./src/config.ts) for more information.
|
||||
|
||||
## Building
|
||||
To build the project, run `npm run build`. This will compile the TypeScript code to JavaScript and output it to the `build` directory. You should run this whenever you pull new changes from the repository.
|
||||
|
||||
Note that if you are trying to build the server on a very memory-constrained (<= 1GB) VPS, you may need to run the build with `NODE_OPTIONS=--max_old_space_size=2048 npm run build` to avoid running out of memory during the build process, assuming you have swap enabled. The application itself should run fine on a 512MB VPS for most reasonable traffic levels.
|
||||
|
||||
## Forking
|
||||
If you are forking the repository on GitGud, you may wish to disable GitLab CI/CD or you will be spammed with emails about failed builds due not having any CI runners. You can do this by going to *Settings > General > Visibility, project features, permissions* and then disabling the "CI/CD" feature.
|
||||
@@ -0,0 +1,21 @@
|
||||
stages:
|
||||
- build
|
||||
|
||||
build_image:
|
||||
stage: build
|
||||
image:
|
||||
name: gcr.io/kaniko-project/executor:debug
|
||||
entrypoint: [""]
|
||||
script:
|
||||
- |
|
||||
if [ "$CI_COMMIT_REF_NAME" = "main" ]; then
|
||||
TAG="latest"
|
||||
else
|
||||
TAG=$CI_COMMIT_REF_NAME
|
||||
fi
|
||||
- echo "Building image with tag $TAG"
|
||||
- BASE64_AUTH=$(echo -n "$DOCKER_HUB_USERNAME:$DOCKER_HUB_ACCESS_TOKEN" | base64)
|
||||
- echo "{\"auths\":{\"https://index.docker.io/v1/\":{\"auth\":\"$BASE64_AUTH\"}}}" > /kaniko/.docker/config.json
|
||||
- /kaniko/executor --context $CI_PROJECT_DIR --dockerfile $CI_PROJECT_DIR/docker/ci/Dockerfile --destination docker.io/khanonci/oai-reverse-proxy:$TAG --build-arg CI_COMMIT_REF_NAME=$CI_COMMIT_REF_NAME --build-arg CI_COMMIT_SHA=$CI_COMMIT_SHA --build-arg CI_PROJECT_PATH=$CI_PROJECT_PATH
|
||||
only:
|
||||
- main
|
||||
@@ -0,0 +1,22 @@
|
||||
FROM node:18-bullseye-slim
|
||||
|
||||
WORKDIR /app
|
||||
COPY . .
|
||||
|
||||
RUN npm ci
|
||||
RUN npm run build
|
||||
RUN npm prune --production
|
||||
|
||||
EXPOSE 7860
|
||||
ENV PORT=7860
|
||||
ENV NODE_ENV=production
|
||||
|
||||
ARG CI_COMMIT_REF_NAME
|
||||
ARG CI_COMMIT_SHA
|
||||
ARG CI_PROJECT_PATH
|
||||
|
||||
ENV GITGUD_BRANCH=$CI_COMMIT_REF_NAME
|
||||
ENV GITGUD_COMMIT=$CI_COMMIT_SHA
|
||||
ENV GITGUD_PROJECT=$CI_PROJECT_PATH
|
||||
|
||||
CMD [ "npm", "start" ]
|
||||
@@ -0,0 +1,17 @@
|
||||
# Before running this, create a .env and greeting.md file.
|
||||
# Refer to .env.example for the required environment variables.
|
||||
# User-generated content is stored in the data directory.
|
||||
# When self-hosting, it's recommended to run this behind a reverse proxy like
|
||||
# nginx or Caddy to handle SSL/TLS and rate limiting. Refer to
|
||||
# docs/self-hosting.md for more information and an example nginx config.
|
||||
version: '3.8'
|
||||
services:
|
||||
oai-reverse-proxy:
|
||||
image: khanonci/oai-reverse-proxy:latest
|
||||
ports:
|
||||
- "127.0.0.1:7860:7860"
|
||||
env_file:
|
||||
- ./.env
|
||||
volumes:
|
||||
- ./greeting.md:/app/greeting.md
|
||||
- ./data:/app/data
|
||||
@@ -0,0 +1,15 @@
|
||||
FROM node:18-bullseye-slim
|
||||
RUN apt-get update && \
|
||||
apt-get install -y git
|
||||
RUN git clone https://gitgud.io/khanon/oai-reverse-proxy.git /app
|
||||
WORKDIR /app
|
||||
RUN chown -R 1000:1000 /app
|
||||
USER 1000
|
||||
RUN npm install
|
||||
COPY Dockerfile greeting.md* .env* ./
|
||||
RUN npm run build
|
||||
EXPOSE 7860
|
||||
ENV NODE_ENV=production
|
||||
# Huggigface free VMs have 16GB of RAM so we can be greedy
|
||||
ENV NODE_OPTIONS="--max-old-space-size=12882"
|
||||
CMD [ "npm", "start" ]
|
||||
@@ -0,0 +1,26 @@
|
||||
# syntax = docker/dockerfile:1.2
|
||||
|
||||
FROM node:18-bullseye-slim
|
||||
RUN apt-get update && \
|
||||
apt-get install -y curl
|
||||
|
||||
# Unlike Huggingface, Render can only deploy straight from a git repo and
|
||||
# doesn't allow you to create or modify arbitrary files via the web UI.
|
||||
# To use a greeting file, set `GREETING_URL` to a URL that points to a raw
|
||||
# text file containing your greeting, such as a GitHub Gist.
|
||||
|
||||
# You may need to clear the build cache if you change the greeting, otherwise
|
||||
# Render will use the cached layer from the previous build.
|
||||
|
||||
WORKDIR /app
|
||||
ARG GREETING_URL
|
||||
RUN if [ -n "$GREETING_URL" ]; then \
|
||||
curl -sL "$GREETING_URL" > greeting.md; \
|
||||
fi
|
||||
COPY . .
|
||||
RUN npm install
|
||||
RUN npm run build
|
||||
RUN --mount=type=secret,id=_env,dst=/etc/secrets/.env cat /etc/secrets/.env >> .env
|
||||
EXPOSE 10000
|
||||
ENV NODE_ENV=production
|
||||
CMD [ "npm", "start" ]
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.2 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 153 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 22 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 36 KiB |
@@ -0,0 +1,245 @@
|
||||
|
||||
openapi: 3.0.0
|
||||
info:
|
||||
version: 1.0.0
|
||||
title: User Management API
|
||||
paths:
|
||||
/admin/users:
|
||||
get:
|
||||
summary: List all users
|
||||
operationId: getUsers
|
||||
responses:
|
||||
"200":
|
||||
description: A list of users
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
users:
|
||||
type: array
|
||||
items:
|
||||
$ref: "#/components/schemas/User"
|
||||
count:
|
||||
type: integer
|
||||
format: int32
|
||||
post:
|
||||
summary: Create a new user
|
||||
operationId: createUser
|
||||
requestBody:
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
oneOf:
|
||||
- type: object
|
||||
properties:
|
||||
type:
|
||||
type: string
|
||||
enum: ["normal", "special"]
|
||||
- type: object
|
||||
properties:
|
||||
type:
|
||||
type: string
|
||||
enum: ["temporary"]
|
||||
expiresAt:
|
||||
type: integer
|
||||
format: int64
|
||||
tokenLimits:
|
||||
$ref: "#/components/schemas/TokenCount"
|
||||
responses:
|
||||
"200":
|
||||
description: The created user's token
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
token:
|
||||
type: string
|
||||
put:
|
||||
summary: Bulk upsert users
|
||||
operationId: bulkUpsertUsers
|
||||
requestBody:
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
users:
|
||||
type: array
|
||||
items:
|
||||
$ref: "#/components/schemas/User"
|
||||
responses:
|
||||
"200":
|
||||
description: The upserted users
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
upserted_users:
|
||||
type: array
|
||||
items:
|
||||
$ref: "#/components/schemas/User"
|
||||
count:
|
||||
type: integer
|
||||
format: int32
|
||||
"400":
|
||||
description: Bad request
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
|
||||
/admin/users/{token}:
|
||||
get:
|
||||
summary: Get a user by token
|
||||
operationId: getUser
|
||||
parameters:
|
||||
- name: token
|
||||
in: path
|
||||
required: true
|
||||
schema:
|
||||
type: string
|
||||
responses:
|
||||
"200":
|
||||
description: A user
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: "#/components/schemas/User"
|
||||
"404":
|
||||
description: Not found
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
put:
|
||||
summary: Update a user by token
|
||||
operationId: upsertUser
|
||||
parameters:
|
||||
- name: token
|
||||
in: path
|
||||
required: true
|
||||
schema:
|
||||
type: string
|
||||
requestBody:
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: "#/components/schemas/User"
|
||||
responses:
|
||||
"200":
|
||||
description: The updated user
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: "#/components/schemas/User"
|
||||
"400":
|
||||
description: Bad request
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
delete:
|
||||
summary: Disables the user with the given token
|
||||
description: Optionally accepts a `disabledReason` query parameter. Returns the disabled user.
|
||||
parameters:
|
||||
- in: path
|
||||
name: token
|
||||
required: true
|
||||
schema:
|
||||
type: string
|
||||
description: The token of the user to disable
|
||||
- in: query
|
||||
name: disabledReason
|
||||
required: false
|
||||
schema:
|
||||
type: string
|
||||
description: The reason for disabling the user
|
||||
responses:
|
||||
'200':
|
||||
description: The disabled user
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
$ref: '#/components/schemas/User'
|
||||
'400':
|
||||
description: Bad request
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
'404':
|
||||
description: Not found
|
||||
content:
|
||||
application/json:
|
||||
schema:
|
||||
type: object
|
||||
properties:
|
||||
error:
|
||||
type: string
|
||||
components:
|
||||
schemas:
|
||||
TokenCount:
|
||||
type: object
|
||||
properties:
|
||||
turbo:
|
||||
type: integer
|
||||
format: int32
|
||||
gpt4:
|
||||
type: integer
|
||||
format: int32
|
||||
"gpt4-32k":
|
||||
type: integer
|
||||
format: int32
|
||||
claude:
|
||||
type: integer
|
||||
format: int32
|
||||
User:
|
||||
type: object
|
||||
properties:
|
||||
token:
|
||||
type: string
|
||||
ip:
|
||||
type: array
|
||||
items:
|
||||
type: string
|
||||
nickname:
|
||||
type: string
|
||||
type:
|
||||
type: string
|
||||
enum: ["normal", "special"]
|
||||
promptCount:
|
||||
type: integer
|
||||
format: int32
|
||||
tokenLimits:
|
||||
$ref: "#/components/schemas/TokenCount"
|
||||
tokenCounts:
|
||||
$ref: "#/components/schemas/TokenCount"
|
||||
createdAt:
|
||||
type: integer
|
||||
format: int64
|
||||
lastUsedAt:
|
||||
type: integer
|
||||
format: int64
|
||||
disabledAt:
|
||||
type: integer
|
||||
format: int64
|
||||
disabledReason:
|
||||
type: string
|
||||
expiresAt:
|
||||
type: integer
|
||||
format: int64
|
||||
@@ -0,0 +1,58 @@
|
||||
# Configuring the proxy for AWS Bedrock
|
||||
|
||||
The proxy supports AWS Bedrock models via the `/proxy/aws/claude` endpoint. There are a few extra steps necessary to use AWS Bedrock compared to the other supported APIs.
|
||||
|
||||
- [Setting keys](#setting-keys)
|
||||
- [Attaching policies](#attaching-policies)
|
||||
- [Provisioning models](#provisioning-models)
|
||||
- [Note regarding logging](#note-regarding-logging)
|
||||
|
||||
## Setting keys
|
||||
|
||||
Use the `AWS_CREDENTIALS` environment variable to set the AWS API keys.
|
||||
|
||||
Like other APIs, you can provide multiple keys separated by commas. Each AWS key, however, is a set of credentials including the access key, secret key, and region. These are separated by a colon (`:`).
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
AWS_CREDENTIALS=AKIA000000000000000:somesecretkey:us-east-1,AKIA111111111111111:anothersecretkey:us-west-2
|
||||
```
|
||||
|
||||
## Attaching policies
|
||||
|
||||
Unless your credentials belong to the root account, the principal will need to be granted the following permissions:
|
||||
|
||||
- `bedrock:InvokeModel`
|
||||
- `bedrock:InvokeModelWithResponseStream`
|
||||
- `bedrock:GetModelInvocationLoggingConfiguration`
|
||||
- The proxy needs this to determine whether prompt/response logging is enabled. By default, the proxy won't use credentials unless it can conclusively determine that logging is disabled, for privacy reasons.
|
||||
|
||||
Use the IAM console or the AWS CLI to attach these policies to the principal associated with the credentials.
|
||||
|
||||
## Provisioning models
|
||||
|
||||
AWS does not automatically provide accounts with access to every model. You will need to provision the models you want to use, in the regions you want to use them in. You can do this from the AWS console.
|
||||
|
||||
⚠️ **Models are region-specific.** Currently AWS only offers Claude in a small number of regions. Switch to the AWS region you want to use, then go to the models page and request access to **Anthropic / Claude**.
|
||||
|
||||

|
||||
|
||||
Access is generally granted more or less instantly. Once your account has access, you can enable the model by checking the box next to it.
|
||||
|
||||
You can also request Claude Instant, but support for this isn't fully implemented yet.
|
||||
|
||||
### Supported model IDs
|
||||
Users can send these model IDs to the proxy to invoke the corresponding models.
|
||||
- **Claude**
|
||||
- `anthropic.claude-v1` (~18k context, claude 1.3 -- EOL 2024-02-28)
|
||||
- `anthropic.claude-v2` (~100k context, claude 2.0)
|
||||
- `anthropic.claude-v2:1` (~200k context, claude 2.1)
|
||||
- **Claude Instant**
|
||||
- `anthropic.claude-instant-v1` (~100k context, claude instant 1.2)
|
||||
|
||||
## Note regarding logging
|
||||
|
||||
By default, the proxy will refuse to use keys if it finds that logging is enabled, or if it doesn't have permission to check logging status.
|
||||
|
||||
If you can't attach the `bedrock:GetModelInvocationLoggingConfiguration` policy to the principal, you can set the `ALLOW_AWS_LOGGING` environment variable to `true` to force the proxy to use the keys anyway. A warning will appear on the info page when this is enabled.
|
||||
@@ -0,0 +1,30 @@
|
||||
# Configuring the proxy for Azure
|
||||
|
||||
The proxy supports Azure OpenAI Service via the `/proxy/azure/openai` endpoint. The process of setting it up is slightly different from regular OpenAI.
|
||||
|
||||
- [Setting keys](#setting-keys)
|
||||
- [Model assignment](#model-assignment)
|
||||
|
||||
## Setting keys
|
||||
|
||||
Use the `AZURE_CREDENTIALS` environment variable to set the Azure API keys.
|
||||
|
||||
Like other APIs, you can provide multiple keys separated by commas. Each Azure key, however, is a set of values including the Resource Name, Deployment ID, and API key. These are separated by a colon (`:`).
|
||||
|
||||
For example:
|
||||
```
|
||||
AZURE_CREDENTIALS=contoso-ml:gpt4-8k:0123456789abcdef0123456789abcdef,northwind-corp:testdeployment:0123456789abcdef0123456789abcdef
|
||||
```
|
||||
|
||||
## Model assignment
|
||||
Note that each Azure deployment is assigned a model when you create it in the Azure OpenAI Service portal. If you want to use a different model, you'll need to create a new deployment, and therefore a new key to be added to the AZURE_CREDENTIALS environment variable. Each credential only grants access to one model.
|
||||
|
||||
### Supported model IDs
|
||||
Users can send normal OpenAI model IDs to the proxy to invoke the corresponding models. For the most part they work the same with Azure. GPT-3.5 Turbo has an ID of "gpt-35-turbo" because Azure doesn't allow periods in model names, but the proxy should automatically convert this to the correct ID.
|
||||
|
||||
As noted above, you can only use model IDs for which a deployment has been created and added to the proxy.
|
||||
|
||||
## On content filtering
|
||||
Be aware that all Azure OpenAI Service deployments have content filtering enabled by default at a Medium level. Prompts or responses which are deemed to be inappropriate will be rejected by the API. This is a feature of the Azure OpenAI Service and not the proxy.
|
||||
|
||||
You can disable this from deployment's settings within Azure, but you would need to request an exemption from Microsoft for your organization first. See [this page](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/content-filters) for more information.
|
||||
@@ -0,0 +1,71 @@
|
||||
# Configuring the proxy for DALL-E
|
||||
|
||||
The proxy supports DALL-E 2 and DALL-E 3 image generation via the `/proxy/openai-images` endpoint. By default it is disabled as it is somewhat expensive and potentially more open to abuse than text generation.
|
||||
|
||||
- [Updating your Dockerfile](#updating-your-dockerfile)
|
||||
- [Enabling DALL-E](#enabling-dall-e)
|
||||
- [Setting quotas](#setting-quotas)
|
||||
- [Rate limiting](#rate-limiting)
|
||||
|
||||
## Updating your Dockerfile
|
||||
If you are using a previous version of the Dockerfile supplied with the proxy, it doesn't have the necessary permissions to let the proxy save temporary files.
|
||||
|
||||
You can replace the entire thing with the new Dockerfile at [./docker/huggingface/Dockerfile](../docker/huggingface/Dockerfile) (or the equivalent for Render deployments).
|
||||
|
||||
You can also modify your existing Dockerfile; just add the following lines after the `WORKDIR` line:
|
||||
|
||||
```Dockerfile
|
||||
# Existing
|
||||
RUN git clone https://gitgud.io/khanon/oai-reverse-proxy.git /app
|
||||
WORKDIR /app
|
||||
|
||||
# Take ownership of the app directory and switch to the non-root user
|
||||
RUN chown -R 1000:1000 /app
|
||||
USER 1000
|
||||
|
||||
# Existing
|
||||
RUN npm install
|
||||
```
|
||||
|
||||
## Enabling DALL-E
|
||||
Add `dall-e` to the `ALLOWED_MODEL_FAMILIES` environment variable to enable DALL-E. For example:
|
||||
|
||||
```
|
||||
# GPT3.5 Turbo, GPT-4, GPT-4 Turbo, and DALL-E
|
||||
ALLOWED_MODEL_FAMILIES=turbo,gpt-4,gpt-4turbo,dall-e
|
||||
|
||||
# All models as of this writing
|
||||
ALLOWED_MODEL_FAMILIES=turbo,gpt4,gpt4-32k,gpt4-turbo,claude,gemini-pro,aws-claude,dall-e
|
||||
```
|
||||
|
||||
Refer to [.env.example](../.env.example) for a full list of supported model families. You can add `dall-e` to that list to enable all models.
|
||||
|
||||
## Setting quotas
|
||||
DALL-E doesn't bill by token like text generation models. Instead there is a fixed cost per image generated, depending on the model, image size, and selected quality.
|
||||
|
||||
The proxy still uses tokens to set quotas for users. The cost for each generated image will be converted to "tokens" at a rate of 100000 tokens per US$1.00. This works out to a similar cost-per-token as GPT-4 Turbo, so you can use similar token quotas for both.
|
||||
|
||||
Use `TOKEN_QUOTA_DALL_E` to set the default quota for image generation. Otherwise it works the same as token quotas for other models.
|
||||
|
||||
```
|
||||
# ~50 standard DALL-E images per refresh period, or US$2.00
|
||||
TOKEN_QUOTA_DALL_E=200000
|
||||
```
|
||||
|
||||
Refer to [https://openai.com/pricing](https://openai.com/pricing) for the latest pricing information. As of this writing, the cheapest DALL-E 3 image costs $0.04 per generation, which works out to 4000 tokens. Higher resolution and quality settings can cost up to $0.12 per image, or 12000 tokens.
|
||||
|
||||
## Rate limiting
|
||||
The old `MODEL_RATE_LIMIT` setting has been split into `TEXT_MODEL_RATE_LIMIT` and `IMAGE_MODEL_RATE_LIMIT`. Whatever value you previously set for `MODEL_RATE_LIMIT` will be used for text models.
|
||||
|
||||
If you don't specify a `IMAGE_MODEL_RATE_LIMIT`, it defaults to half of the `TEXT_MODEL_RATE_LIMIT`, to a minimum of 1 image per minute.
|
||||
|
||||
```
|
||||
# 4 text generations per minute, 2 images per minute
|
||||
TEXT_MODEL_RATE_LIMIT=4
|
||||
IMAGE_MODEL_RATE_LIMIT=2
|
||||
```
|
||||
|
||||
If a prompt is filtered by OpenAI's content filter, it won't count towards the rate limit.
|
||||
|
||||
## Hiding recent images
|
||||
By default, the proxy shows the last 12 recently generated images by users. You can hide this section by setting `SHOW_RECENT_IMAGES` to `false`.
|
||||
@@ -0,0 +1,104 @@
|
||||
# Deploy to Huggingface Space
|
||||
|
||||
**⚠️ This method is no longer recommended. Please use the [self-hosting instructions](./self-hosting.md) instead.**
|
||||
|
||||
This repository can be deployed to a [Huggingface Space](https://huggingface.co/spaces). This is a free service that allows you to run a simple server in the cloud. You can use it to safely share your OpenAI API key with a friend.
|
||||
|
||||
### 1. Get an API key
|
||||
- Go to [OpenAI](https://openai.com/) and sign up for an account. You can use a free trial key for this as long as you provide SMS verification.
|
||||
- Claude is not publicly available yet, but if you have access to it via the [Anthropic](https://www.anthropic.com/) closed beta, you can also use that key with the proxy.
|
||||
|
||||
### 2. Create an empty Huggingface Space
|
||||
- Go to [Huggingface](https://huggingface.co/) and sign up for an account.
|
||||
- Once logged in, [create a new Space](https://huggingface.co/new-space).
|
||||
- Provide a name for your Space and select "Docker" as the SDK. Select "Blank" for the template.
|
||||
- Click "Create Space" and wait for the Space to be created.
|
||||
|
||||

|
||||
|
||||
### 3. Create an empty Dockerfile
|
||||
- Once your Space is created, you'll see an option to "Create the Dockerfile in your browser". Click that link.
|
||||
|
||||

|
||||
- Paste the following into the text editor and click "Save".
|
||||
```dockerfile
|
||||
FROM node:18-bullseye-slim
|
||||
RUN apt-get update && \
|
||||
apt-get install -y git
|
||||
RUN git clone https://gitgud.io/khanon/oai-reverse-proxy.git /app
|
||||
WORKDIR /app
|
||||
RUN chown -R 1000:1000 /app
|
||||
USER 1000
|
||||
RUN npm install
|
||||
COPY Dockerfile greeting.md* .env* ./
|
||||
RUN npm run build
|
||||
EXPOSE 7860
|
||||
ENV NODE_ENV=production
|
||||
ENV NODE_OPTIONS="--max-old-space-size=12882"
|
||||
CMD [ "npm", "start" ]
|
||||
```
|
||||
- Click "Commit new file to `main`" to save the Dockerfile.
|
||||
|
||||

|
||||
|
||||
### 4. Set your API key as a secret
|
||||
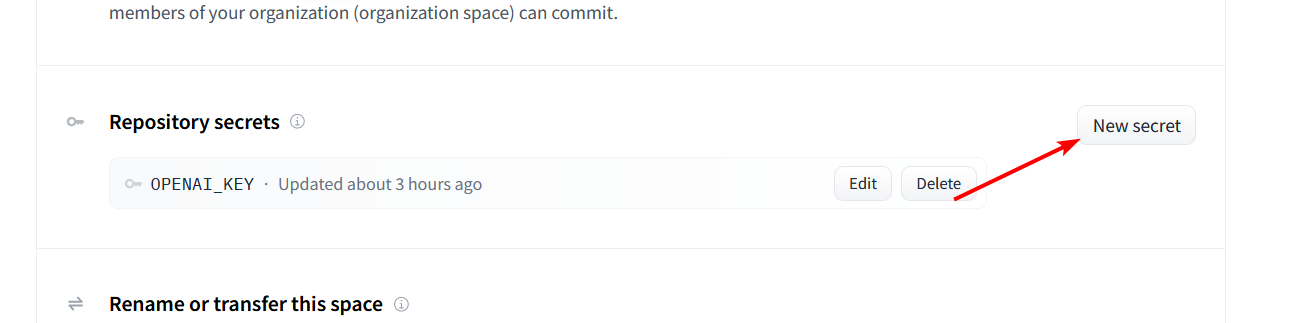
- Click the Settings button in the top right corner of your repository.
|
||||
- Scroll down to the `Repository Secrets` section and click `New Secret`.
|
||||
|
||||
|
||||
|
||||
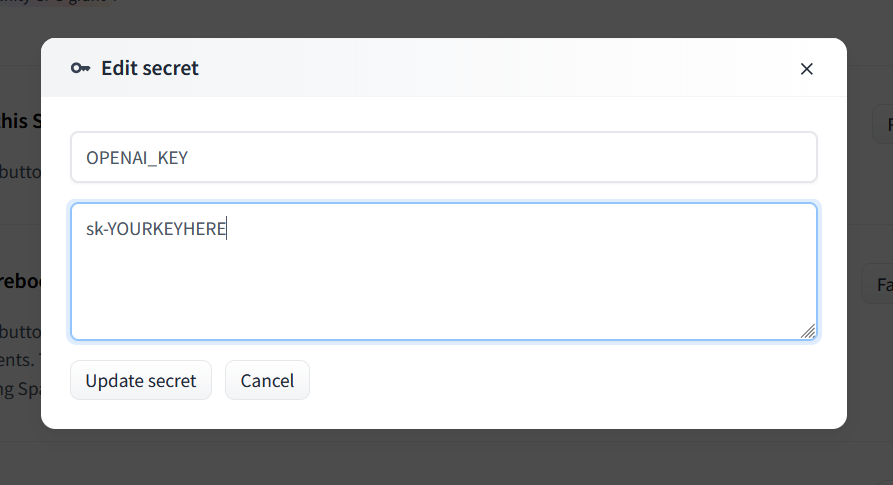
- Enter `OPENAI_KEY` as the name and your OpenAI API key as the value.
|
||||
- For Claude, set `ANTHROPIC_KEY` instead.
|
||||
- You can use both types of keys at the same time if you want.
|
||||
|
||||
|
||||
|
||||
### 5. Deploy the server
|
||||
- Your server should automatically deploy when you add the secret, but if not you can select `Factory Reboot` from that same Settings menu.
|
||||
|
||||
### 6. Share the link
|
||||
- The Service Info section below should show the URL for your server. You can share this with anyone to safely give them access to your API key.
|
||||
- Your friend doesn't need any API key of their own, they just need your link.
|
||||
|
||||
# Optional
|
||||
|
||||
## Updating the server
|
||||
|
||||
To update your server, go to the Settings menu and select `Factory Reboot`. This will pull the latest version of the code from GitHub and restart the server.
|
||||
|
||||
Note that if you just perform a regular Restart, the server will be restarted with the same code that was running before.
|
||||
|
||||
## Adding a greeting message
|
||||
|
||||
You can create a Markdown file called `greeting.md` to display a message on the Server Info page. This is a good place to put instructions for how to use the server.
|
||||
|
||||
## Customizing the server
|
||||
|
||||
The server will be started with some default configuration, but you can override it by adding a `.env` file to your Space. You can use Huggingface's web editor to create a new `.env` file alongside your Dockerfile. Huggingface will restart your server automatically when you save the file.
|
||||
|
||||
Here are some example settings:
|
||||
```shell
|
||||
# Requests per minute per IP address
|
||||
MODEL_RATE_LIMIT=4
|
||||
# Max tokens to request from OpenAI
|
||||
MAX_OUTPUT_TOKENS_OPENAI=256
|
||||
# Max tokens to request from Anthropic (Claude)
|
||||
MAX_OUTPUT_TOKENS_ANTHROPIC=512
|
||||
# Block prompts containing disallowed characters
|
||||
REJECT_DISALLOWED=false
|
||||
REJECT_MESSAGE="This content violates /aicg/'s acceptable use policy."
|
||||
```
|
||||
|
||||
See `.env.example` for a full list of available settings, or check `config.ts` for details on what each setting does.
|
||||
|
||||
## Restricting access to the server
|
||||
|
||||
If you want to restrict access to the server, you can set a `PROXY_KEY` secret. This key will need to be passed in the Authentication header of every request to the server, just like an OpenAI API key. Set the `GATEKEEPER` mode to `proxy_key`, and then set the `PROXY_KEY` variable to whatever password you want.
|
||||
|
||||
Add this using the same method as the OPENAI_KEY secret above. Don't add this to your `.env` file because that file is public and anyone can see it.
|
||||
|
||||
Example:
|
||||
```
|
||||
GATEKEEPER=proxy_key
|
||||
PROXY_KEY=your_secret_password
|
||||
```
|
||||
@@ -0,0 +1,56 @@
|
||||
# Deploy to Render.com
|
||||
|
||||
**⚠️ This method is no longer supported or recommended and may not work. Please use the [self-hosting instructions](./self-hosting.md) instead.**
|
||||
|
||||
Render.com offers a free tier that includes 750 hours of compute time per month. This is enough to run a single proxy instance 24/7. Instances shut down after 15 minutes without traffic but start up again automatically when a request is received. You can use something like https://app.checklyhq.com/ to ping your proxy every 15 minutes to keep it alive.
|
||||
|
||||
### 1. Create account
|
||||
- [Sign up for Render.com](https://render.com/) to create an account and access the dashboard.
|
||||
|
||||
### 2. Create a service using a Blueprint
|
||||
Render allows you to deploy and auutomatically configure a repository containing a [render.yaml](../render.yaml) file using its Blueprints feature. This is the easiest way to get started.
|
||||
|
||||
- Click the **Blueprints** tab at the top of the dashboard.
|
||||
- Click **New Blueprint Instance**.
|
||||
- Under **Public Git repository**, enter `https://gitlab.com/khanon/oai-proxy`.
|
||||
- Note that this is not the GitGud repository, but a mirror on GitLab.
|
||||
- Click **Continue**.
|
||||
- Under **Blueprint Name**, enter a name.
|
||||
- Under **Branch**, enter `main`.
|
||||
- Click **Apply**.
|
||||
|
||||
The service will be created according to the instructions in the `render.yaml` file. Don't wait for it to complete as it will fail due to missing environment variables. Instead, proceed to the next step.
|
||||
|
||||
### 3. Set environment variables
|
||||
- Return to the **Dashboard** tab.
|
||||
- Click the name of the service you just created, which may show as "Deploy failed".
|
||||
- Click the **Environment** tab.
|
||||
- Click **Add Secret File**.
|
||||
- Under **Filename**, enter `.env`.
|
||||
- Under **Contents**, enter all of your environment variables, one per line, in the format `NAME=value`.
|
||||
- For example, `OPENAI_KEY=sk-abc123`.
|
||||
- Click **Save Changes**.
|
||||
|
||||
**IMPORTANT:** Set `TRUSTED_PROXIES=3`, otherwise users' IP addresses will not be recorded correctly (the server will see the IP address of Render's load balancer instead of the user's real IP address).
|
||||
|
||||
The service will automatically rebuild and deploy with the new environment variables. This will take a few minutes. The link to your deployed proxy will appear at the top of the page.
|
||||
|
||||
If you want to change the URL, go to the **Settings** tab of your Web Service and click the **Edit** button next to **Name**. You can also set a custom domain, though I haven't tried this yet.
|
||||
|
||||
# Optional
|
||||
|
||||
## Updating the server
|
||||
|
||||
To update your server, go to the page for your Web Service and click **Manual Deploy** > **Deploy latest commit**. This will pull the latest version of the code and redeploy the server.
|
||||
|
||||
_If you have trouble with this, you can also try selecting **Clear build cache & deploy** instead from the same menu._
|
||||
|
||||
## Adding a greeting message
|
||||
|
||||
To show a greeting message on the Server Info page, set the `GREETING_URL` environment variable within Render to the URL of a Markdown file. This URL should point to a raw text file, not an HTML page. You can use a public GitHub Gist or GitLab Snippet for this. For example: `GREETING_URL=https://gitlab.com/-/snippets/2542011/raw/main/greeting.md`. You can change the title of the page by setting the `SERVER_TITLE` environment variable.
|
||||
|
||||
Don't set `GREETING_URL` in the `.env` secret file you created earlier; it must be set in Render's environment variables section for it to work correctly.
|
||||
|
||||
## Customizing the server
|
||||
|
||||
You can customize the server by editing the `.env` configuration you created earlier. Refer to [.env.example](../.env.example) for a list of all available configuration options. Further information can be found in the [config.ts](../src/config.ts) file.
|
||||
@@ -0,0 +1,35 @@
|
||||
# Configuring the proxy for Vertex AI (GCP)
|
||||
|
||||
The proxy supports GCP models via the `/proxy/gcp/claude` endpoint. There are a few extra steps necessary to use GCP compared to the other supported APIs.
|
||||
|
||||
- [Setting keys](#setting-keys)
|
||||
- [Setup Vertex AI](#setup-vertex-ai)
|
||||
- [Supported model IDs](#supported-model-ids)
|
||||
|
||||
## Setting keys
|
||||
|
||||
Use the `GCP_CREDENTIALS` environment variable to set the GCP API keys.
|
||||
|
||||
Like other APIs, you can provide multiple keys separated by commas. Each GCP key, however, is a set of credentials including the project id, client email, region and private key. These are separated by a colon (`:`).
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
GCP_CREDENTIALS=my-first-project:xxx@yyy.com:us-east5:-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----,my-first-project2:xxx2@yyy.com:us-east5:-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----
|
||||
```
|
||||
|
||||
## Setup Vertex AI
|
||||
1. Go to [https://cloud.google.com/vertex-ai](https://cloud.google.com/vertex-ai) and sign up for a GCP account. ($150 free credits without credit card or $300 free credits with credit card, credits expire in 90 days)
|
||||
2. Go to [https://console.cloud.google.com/marketplace/product/google/aiplatform.googleapis.com](https://console.cloud.google.com/marketplace/product/google/aiplatform.googleapis.com) to enable Vertex AI API.
|
||||
3. Go to [https://console.cloud.google.com/vertex-ai](https://console.cloud.google.com/vertex-ai) and navigate to Model Garden to apply for access to the Claude models.
|
||||
4. Create a [Service Account](https://console.cloud.google.com/projectselector/iam-admin/serviceaccounts/create?walkthrough_id=iam--create-service-account#step_index=1) , and make sure to grant the role of "Vertex AI User" or "Vertex AI Administrator".
|
||||
5. On the service account page you just created, create a new key and select "JSON". The JSON file will be downloaded automatically.
|
||||
6. The required credential is in the JSON file you just downloaded.
|
||||
|
||||
## Supported model IDs
|
||||
Users can send these model IDs to the proxy to invoke the corresponding models.
|
||||
- **Claude**
|
||||
- `claude-3-haiku@20240307`
|
||||
- `claude-3-sonnet@20240229`
|
||||
- `claude-3-opus@20240229`
|
||||
- `claude-3-5-sonnet@20240620`
|
||||
@@ -0,0 +1,61 @@
|
||||
# Warning
|
||||
**I strongly suggest against using this feature with a Google account that you care about.** Depending on the content of the prompts people submit, Google may flag the spreadsheet as containing inappropriate content. This seems to prevent you from sharing that spreadsheet _or any others on the account. This happened with my throwaway account during testing; the existing shared spreadsheet continues to work but even completely new spreadsheets are flagged and cannot be shared.
|
||||
|
||||
I'll be looking into alternative storage backends but you should not use this implementation with a Google account you care about, or even one remotely connected to your main accounts (as Google has a history of linking accounts together via IPs/browser fingerprinting). Use a VPN and completely isolated VM to be safe.
|
||||
|
||||
# Configuring Google Sheets Prompt Logging
|
||||
This proxy can log incoming prompts and model responses to Google Sheets. Some configuration on the Google side is required to enable this feature. The APIs used are free, but you will need a Google account and a Google Cloud Platform project.
|
||||
|
||||
NOTE: Concurrency is not supported. Don't connect two instances of the server to the same spreadsheet or bad things will happen.
|
||||
|
||||
## Prerequisites
|
||||
- A Google account
|
||||
- **USE A THROWAWAY ACCOUNT!**
|
||||
- A Google Cloud Platform project
|
||||
|
||||
### 0. Create a Google Cloud Platform Project
|
||||
_A Google Cloud Platform project is required to enable programmatic access to Google Sheets. If you already have a project, skip to the next step. You can also see the [Google Cloud Platform documentation](https://developers.google.com/workspace/guides/create-project) for more information._
|
||||
|
||||
- Go to the Google Cloud Platform Console and [create a new project](https://console.cloud.google.com/projectcreate).
|
||||
|
||||
### 1. Enable the Google Sheets API
|
||||
_The Google Sheets API must be enabled for your project. You can also see the [Google Sheets API documentation](https://developers.google.com/sheets/api/quickstart/nodejs) for more information._
|
||||
|
||||
- Go to the [Google Sheets API page](https://console.cloud.google.com/apis/library/sheets.googleapis.com) and click **Enable**, then fill in the form to enable the Google Sheets API for your project.
|
||||
<!-- TODO: Add screenshot of Enable page and describe filling out the form -->
|
||||
|
||||
### 2. Create a Service Account
|
||||
_A service account is required to authenticate the proxy to Google Sheets._
|
||||
|
||||
- Once the Google Sheets API is enabled, click the **Credentials** tab on the Google Sheets API page.
|
||||
- Click **Create credentials** and select **Service account**.
|
||||
- Provide a name for the service account and click **Done** (the second and third steps can be skipped).
|
||||
|
||||
### 3. Download the Service Account Key
|
||||
_Once your account is created, you'll need to download the key file and include it in the proxy's secrets configuration._
|
||||
|
||||
- Click the Service Account you just created in the list of service accounts for the API.
|
||||
- Click the **Keys** tab and click **Add key**, then select **Create new key**.
|
||||
- Select **JSON** as the key type and click **Create**.
|
||||
|
||||
The JSON file will be downloaded to your computer.
|
||||
|
||||
### 4. Set the Service Account key as a Secret
|
||||
_The JSON key file must be set as a secret in the proxy's configuration. Because files cannot be included in the secrets configuration, you'll need to base64 encode the file's contents and paste the encoded string as the value of the `GOOGLE_SHEETS_KEY` secret._
|
||||
|
||||
- Open the JSON key file in a text editor and copy the contents.
|
||||
- Visit the [base64 encode/decode tool](https://www.base64encode.org/) and paste the contents into the box, then click **Encode**.
|
||||
- Copy the encoded string and paste it as the value of the `GOOGLE_SHEETS_KEY` secret in the deployment's secrets configuration.
|
||||
- **WARNING:** Don't reveal this string publically. The `.env` file is NOT private -- unless you're running the proxy locally, you should not use it to store secrets!
|
||||
|
||||
### 5. Create a new spreadsheet and share it with the service account
|
||||
_The service account must be given permission to access the logging spreadsheet. Each service account has a unique email address, which can be found in the JSON key file; share the spreadsheet with that email address just as you would share it with another user._
|
||||
|
||||
- Open the JSON key file in a text editor and copy the value of the `client_email` field.
|
||||
- Open the spreadsheet you want to log to, or create a new one, and click **File > Share**.
|
||||
- Paste the service account's email address into the **Add people or groups** field. Ensure the service account has **Editor** permissions, then click **Done**.
|
||||
|
||||
### 6. Set the spreadsheet ID as a Secret
|
||||
_The spreadsheet ID must be set as a secret in the proxy's configuration. The spreadsheet ID can be found in the URL of the spreadsheet. For example, the spreadsheet ID for `https://docs.google.com/spreadsheets/d/1X2Y3Z/edit#gid=0` is `1X2Y3Z`. The ID isn't necessarily a sensitive value if you intend for the spreadsheet to be public, but it's still recommended to set it as a secret._
|
||||
|
||||
- Copy the spreadsheet ID and paste it as the value of the `GOOGLE_SHEETS_SPREADSHEET_ID` secret in the deployment's secrets configuration.
|
||||
@@ -0,0 +1,135 @@
|
||||
# Proof-of-work Verification
|
||||
|
||||
You can require users to complete a proof-of-work before they can access the
|
||||
proxy. This can increase the cost of denial of service attacks and slow down
|
||||
automated abuse.
|
||||
|
||||
When configured, users access the challenge UI and request a token. The server
|
||||
sends a challenge to the client, which asks the user's browser to find a
|
||||
solution to the challenge that meets a certain constraint (the difficulty
|
||||
level). Once the user has found a solution, they can submit it to the server
|
||||
and get a user token valid for a period you specify.
|
||||
|
||||
The proof-of-work challenge uses the argon2id hash function.
|
||||
|
||||
## Configuration
|
||||
|
||||
To enable proof-of-work verification, set the following environment variables:
|
||||
|
||||
```
|
||||
GATEKEEPER=user_token
|
||||
CAPTCHA_MODE=proof_of_work
|
||||
# Validity of the token in hours
|
||||
POW_TOKEN_HOURS=24
|
||||
# Max number of IPs that can use a user_token issued via proof-of-work
|
||||
POW_TOKEN_MAX_IPS=2
|
||||
# The difficulty level of the proof-of-work challenge. You can use one of the
|
||||
# predefined levels specified below, or you can specify a custom number of
|
||||
# expected hash iterations.
|
||||
POW_DIFFICULTY_LEVEL=low
|
||||
# The time limit for solving the challenge, in minutes
|
||||
POW_CHALLENGE_TIMEOUT=30
|
||||
```
|
||||
|
||||
## Difficulty Levels
|
||||
|
||||
The difficulty level controls how long, on average, it will take for a user to
|
||||
solve the proof-of-work challenge. Due to randomness, the actual time can very
|
||||
significantly; lucky users may solve the challenge in a fraction of the average
|
||||
time, while unlucky users may take much longer.
|
||||
|
||||
The difficulty level doesn't affect the speed of the hash function itself, only
|
||||
the number of hashes that will need to be computed. Therefore, the time required
|
||||
to complete the challenge scales linearly with the difficulty level's iteration
|
||||
count.
|
||||
|
||||
You can adjust the difficulty level while the proxy is running from the admin
|
||||
interface.
|
||||
|
||||
Be aware that there is a time limit for solving the challenge, by default set to
|
||||
30 minutes. Above 'high' difficulty, you will probably need to increase the time
|
||||
limit or it will be very hard for users with slow devices to find a solution
|
||||
within the time limit.
|
||||
|
||||
### Low
|
||||
|
||||
- Average of 200 iterations required
|
||||
- Default setting.
|
||||
|
||||
### Medium
|
||||
|
||||
- Average of 900 iterations required
|
||||
|
||||
### High
|
||||
|
||||
- Average of 1900 iterations required
|
||||
|
||||
### Extreme
|
||||
|
||||
- Average of 4000 iterations required
|
||||
- Not recommended unless you are expecting very high levels of abuse
|
||||
- May require increasing `POW_CHALLENGE_TIMEOUT`
|
||||
|
||||
### Custom
|
||||
|
||||
Setting `POW_DIFFICULTY_LEVEL` to an integer will use that number of iterations
|
||||
as the difficulty level.
|
||||
|
||||
## Other challenge settings
|
||||
|
||||
- `POW_CHALLENGE_TIMEOUT`: The time limit for solving the challenge, in minutes.
|
||||
Default is 30.
|
||||
- `POW_TOKEN_HOURS`: The period of time for which a user token issued via proof-
|
||||
of-work can be used. Default is 24 hours. Starts when the challenge is solved.
|
||||
- `POW_TOKEN_MAX_IPS`: The maximum number of unique IPs that can use a single
|
||||
user token issued via proof-of-work. Default is 2.
|
||||
- `POW_TOKEN_PURGE_HOURS`: The period of time after which an expired user token
|
||||
issued via proof-of-work will be removed from the database. Until it is
|
||||
purged, users can refresh expired tokens by completing a half-difficulty
|
||||
challenge. Default is 48 hours.
|
||||
- `POW_MAX_TOKENS_PER_IP`: The maximum number of active user tokens that can
|
||||
be associated with a single IP address. After this limit is reached, the
|
||||
oldest token will be forcibly expired when a new token is issued. Set to 0
|
||||
to disable this feature. Default is 0.
|
||||
|
||||
## Custom argon2id parameters
|
||||
|
||||
You can set custom argon2id parameters for the proof-of-work challenge.
|
||||
Generally, you should not need to change these unless you have a specific
|
||||
reason to do so.
|
||||
|
||||
The listed values are the defaults.
|
||||
|
||||
```
|
||||
ARGON2_TIME_COST=8
|
||||
ARGON2_MEMORY_KB=65536
|
||||
ARGON2_PARALLELISM=1
|
||||
ARGON2_HASH_LENGTH=32
|
||||
```
|
||||
|
||||
Increasing parallelism will not do much except increase memory consumption for
|
||||
both the client and server, because browser proof-of-work implementations are
|
||||
single-threaded. It's better to increase the time cost if you want to increase
|
||||
the difficulty.
|
||||
|
||||
Increasing memory too much may cause memory exhaustion on some mobile devices,
|
||||
particularly on iOS due to the way Safari handles WebAssembly memory allocation.
|
||||
|
||||
## Tested hash rates
|
||||
|
||||
These were measured with the default argon2id parameters listed above. These
|
||||
tests were not at all scientific so take them with a grain of salt.
|
||||
|
||||
Safari does not like large WASM memory usage, so concurrency is limited to 4 to
|
||||
avoid overallocating memory on mobile WebKit browsers. Thermal throttling can
|
||||
also significantly reduce hash rates on mobile devices.
|
||||
|
||||
- Intel Core i9-13900K (Chrome): 33-35 H/s
|
||||
- Intel Core i9-13900K (Firefox): 29-32 H/s
|
||||
- Intel Core i9-13900K (Chrome, in VM limited to 4 cores): 12.2 - 13.0 H/s
|
||||
- iPad Pro (M2) (Safari, 6 workers): 8.0 - 10 H/s
|
||||
- Thermal throttles early. 8 cores is normal concurrency, but unstable.
|
||||
- iPhone 15 Pro Max (Safari): 4.0 - 4.6 H/s
|
||||
- Samsung Galaxy S10e (Chrome): 3.6 - 3.8 H/s
|
||||
- This is a 2019 phone almost matching an iPhone five years newer because of
|
||||
bad Safari performance.
|
||||
@@ -0,0 +1,150 @@
|
||||
# Quick self-hosting guide
|
||||
|
||||
Temporary guide for self-hosting. This will be improved in the future to provide more robust instructions and options. Provided commands are for Ubuntu.
|
||||
|
||||
This uses prebuilt Docker images for convenience. If you want to make adjustments to the code you can instead clone the repo and follow the Local Development guide in the [README](../README.md).
|
||||
|
||||
## Table of Contents
|
||||
- [Requirements](#requirements)
|
||||
- [Running the application](#running-the-application)
|
||||
- [Setting up a reverse proxy](#setting-up-a-reverse-proxy)
|
||||
- [trycloudflare](#trycloudflare)
|
||||
- [nginx](#nginx)
|
||||
- [Example basic nginx configuration (no SSL)](#example-basic-nginx-configuration-no-ssl)
|
||||
- [Example with Cloudflare SSL](#example-with-cloudflare-ssl)
|
||||
- [Updating/Restarting the application](#updatingrestarting-the-application)
|
||||
|
||||
## Requirements
|
||||
|
||||
- Docker
|
||||
- Docker Compose
|
||||
- A VPS with at least 512MB of RAM (1GB recommended)
|
||||
- A domain name
|
||||
|
||||
If you don't have a VPS and domain name you can use TryCloudflare to set up a temporary URL that you can share with others. See [trycloudflare](#trycloudflare) for more information.
|
||||
|
||||
## Running the application
|
||||
|
||||
- Install Docker and Docker Compose
|
||||
- Create a new directory for the application
|
||||
- This will contain your .env file, greeting file, and any user-generated files
|
||||
- Execute the following commands:
|
||||
- ```
|
||||
touch .env
|
||||
touch greeting.md
|
||||
echo "OPENAI_KEY=your-openai-key" >> .env
|
||||
curl https://gitgud.io/khanon/oai-reverse-proxy/-/raw/main/docker/docker-compose-selfhost.yml -o docker-compose.yml
|
||||
```
|
||||
- You can set further environment variables and keys in the `.env` file. See [.env.example](../.env.example) for a list of available options.
|
||||
- You can set a custom greeting in `greeting.md`. This will be displayed on the homepage.
|
||||
- Run `docker compose up -d`
|
||||
|
||||
You can check logs with `docker compose logs -n 100 -f`.
|
||||
|
||||
The provided docker-compose file listens on port 7860 but binds to localhost only. You should use a reverse proxy to expose the application to the internet as described in the next section.
|
||||
|
||||
## Setting up a reverse proxy
|
||||
|
||||
Rather than exposing the application directly to the internet, it is recommended to set up a reverse proxy. This will allow you to use HTTPS and add additional security measures.
|
||||
|
||||
### trycloudflare
|
||||
|
||||
This will give you a temporary (72 hours) URL that you can use to let others connect to your instance securely, without having to set up a reverse proxy. If you are running the server on your home network, this is probably the best option.
|
||||
- Install `cloudflared` following the instructions at [try.cloudflare.com](https://try.cloudflare.com/).
|
||||
- Run `cloudflared tunnel --url http://localhost:7860`
|
||||
- You will be given a temporary URL that you can share with others.
|
||||
|
||||
If you have a VPS, you should use a proper reverse proxy like nginx instead for a more permanent solution which will allow you to use your own domain name, handle SSL, and add additional security/anti-abuse measures.
|
||||
|
||||
### nginx
|
||||
|
||||
First, install nginx.
|
||||
- `sudo apt update && sudo apt install nginx`
|
||||
|
||||
#### Example basic nginx configuration (no SSL)
|
||||
|
||||
- `sudo nano /etc/nginx/sites-available/oai.conf`
|
||||
- ```
|
||||
server {
|
||||
listen 80;
|
||||
server_name example.com;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:7860;
|
||||
}
|
||||
}
|
||||
```
|
||||
- Replace `example.com` with your domain name.
|
||||
- Ctrl+X to exit, Y to save, Enter to confirm.
|
||||
- `sudo ln -s /etc/nginx/sites-available/oai.conf /etc/nginx/sites-enabled`
|
||||
- `sudo nginx -t`
|
||||
- This will check the configuration file for errors.
|
||||
- `sudo systemctl restart nginx`
|
||||
- This will restart nginx and apply the new configuration.
|
||||
|
||||
#### Example with Cloudflare SSL
|
||||
|
||||
This allows you to use a self-signed certificate on the server, and have Cloudflare handle client SSL. You need to have a Cloudflare account and have your domain set up with Cloudflare already, pointing to your server's IP address.
|
||||
|
||||
- Set Cloudflare to use Full SSL mode. Since we are using a self-signed certificate, don't use Full (strict) mode.
|
||||
- Create a self-signed certificate:
|
||||
- `openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/nginx-selfsigned.key -out /etc/ssl/certs/nginx-selfsigned.crt`
|
||||
- `sudo nano /etc/nginx/sites-available/oai.conf`
|
||||
- ```
|
||||
server {
|
||||
listen 443 ssl;
|
||||
server_name yourdomain.com www.yourdomain.com;
|
||||
|
||||
ssl_certificate /etc/ssl/certs/nginx-selfsigned.crt;
|
||||
ssl_certificate_key /etc/ssl/private/nginx-selfsigned.key;
|
||||
|
||||
# Only allow inbound traffic from Cloudflare
|
||||
allow 173.245.48.0/20;
|
||||
allow 103.21.244.0/22;
|
||||
allow 103.22.200.0/22;
|
||||
allow 103.31.4.0/22;
|
||||
allow 141.101.64.0/18;
|
||||
allow 108.162.192.0/18;
|
||||
allow 190.93.240.0/20;
|
||||
allow 188.114.96.0/20;
|
||||
allow 197.234.240.0/22;
|
||||
allow 198.41.128.0/17;
|
||||
allow 162.158.0.0/15;
|
||||
allow 104.16.0.0/13;
|
||||
allow 104.24.0.0/14;
|
||||
allow 172.64.0.0/13;
|
||||
allow 131.0.72.0/22;
|
||||
deny all;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:7860;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection 'upgrade';
|
||||
proxy_set_header Host $host;
|
||||
proxy_cache_bypass $http_upgrade;
|
||||
}
|
||||
|
||||
ssl_protocols TLSv1.2 TLSv1.3;
|
||||
ssl_ciphers 'ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256';
|
||||
ssl_prefer_server_ciphers on;
|
||||
ssl_session_cache shared:SSL:10m;
|
||||
}
|
||||
```
|
||||
- Replace `yourdomain.com` with your domain name.
|
||||
- Ctrl+X to exit, Y to save, Enter to confirm.
|
||||
- `sudo ln -s /etc/nginx/sites-available/oai.conf /etc/nginx/sites-enabled`
|
||||
|
||||
## Updating/Restarting the application
|
||||
|
||||
After making an .env change, you need to restart the application for it to take effect.
|
||||
|
||||
- `docker compose down`
|
||||
- `docker compose up -d`
|
||||
|
||||
To update the application to the latest version:
|
||||
|
||||
- `docker compose pull`
|
||||
- `docker compose down`
|
||||
- `docker compose up -d`
|
||||
- `docker image prune -f`
|
||||
@@ -0,0 +1,85 @@
|
||||
# User Management
|
||||
|
||||
The proxy supports several different user management strategies. You can choose the one that best fits your needs by setting the `GATEKEEPER` environment variable.
|
||||
|
||||
Several of these features require you to set secrets in your environment. If using Huggingface Spaces to deploy, do not set these in your `.env` file because that file is public and anyone can see it.
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [No user management](#no-user-management-gatekeepernone)
|
||||
- [Single-password authentication](#single-password-authentication-gatekeeperproxy_key)
|
||||
- [Per-user authentication](#per-user-authentication-gatekeeperuser_token)
|
||||
- [Memory](#memory)
|
||||
- [Firebase Realtime Database](#firebase-realtime-database)
|
||||
- [Firebase setup instructions](#firebase-setup-instructions)
|
||||
- [SQLite Database](#sqlite-database)
|
||||
- [Whitelisting admin IP addresses](#whitelisting-admin-ip-addresses)
|
||||
|
||||
## No user management (`GATEKEEPER=none`)
|
||||
|
||||
This is the default mode. The proxy will not require any authentication to access the server and offers basic IP-based rate limiting and anti-abuse features.
|
||||
|
||||
## Single-password authentication (`GATEKEEPER=proxy_key`)
|
||||
|
||||
This mode allows you to set a password that must be passed in the `Authentication` header of every request to the server as a bearer token. This is useful if you want to restrict access to the server, but don't want to create a separate account for every user.
|
||||
|
||||
To set the password, create a `PROXY_KEY` secret in your environment.
|
||||
|
||||
## Per-user authentication (`GATEKEEPER=user_token`)
|
||||
|
||||
This mode allows you to provision separate Bearer tokens for each user. You can manage users via the /admin/users via REST or through the admin interface at `/admin`.
|
||||
|
||||
To begin, set `ADMIN_KEY` to a secret value. This will be used to authenticate requests to the REST API or to log in to the UI.
|
||||
|
||||
[You can find an OpenAPI specification for the /admin/users REST API here.](openapi-admin-users.yaml)
|
||||
|
||||
By default, the proxy will store user data in memory. Naturally, this means that user data will be lost when the proxy is restarted, though you can use the user import/export feature to save and restore user data manually or via a script. However, the proxy also supports persisting user data to an external data store with some additional configuration.
|
||||
|
||||
Below are the supported data stores and their configuration options.
|
||||
|
||||
### Memory
|
||||
|
||||
This is the default data store (`GATEKEEPER_STORE=memory`) User data will be stored in memory and will be lost when the server is restarted. You are responsible for exporting and re-importing user data after a restart.
|
||||
|
||||
### Firebase Realtime Database
|
||||
|
||||
To use Firebase Realtime Database to persist user data, set the following environment variables:
|
||||
|
||||
- `GATEKEEPER_STORE`: Set this to `firebase_rtdb`
|
||||
- **Secret** `FIREBASE_RTDB_URL`: The URL of your Firebase Realtime Database, e.g. `https://my-project-default-rtdb.firebaseio.com`
|
||||
- **Secret** `FIREBASE_KEY`: A base-64 encoded service account key for your Firebase project. Refer to the instructions below for how to create this key.
|
||||
|
||||
**Firebase setup instructions**
|
||||
|
||||
1. Go to the [Firebase console](https://console.firebase.google.com/) and click "Add project", then follow the prompts to create a new project.
|
||||
2. From the **Project Overview** page, click **All products** in the left sidebar, then click **Realtime Database**.
|
||||
3. Click **Create database** and choose **Start in test mode**. Click **Enable**.
|
||||
- Test mode is fine for this use case as it still requires authentication to access the database. You may wish to set up more restrictive rules if you plan to use the database for other purposes.
|
||||
- The reference URL for the database will be displayed on the page. You will need this later.
|
||||
4. Click the gear icon next to **Project Overview** in the left sidebar, then click **Project settings**.
|
||||
5. Click the **Service accounts** tab, then click **Generate new private key**.
|
||||
6. The downloaded file contains your key. Encode it as base64 and set it as the `FIREBASE_KEY` secret in your environment.
|
||||
7. Set `FIREBASE_RTDB_URL` to the reference URL of your Firebase Realtime Database, e.g. `https://my-project-default-rtdb.firebaseio.com`.
|
||||
8. Set `GATEKEEPER_STORE` to `firebase_rtdb` in your environment if you haven't already.
|
||||
|
||||
The proxy server will attempt to connect to your Firebase Realtime Database at startup and will throw an error if it cannot connect. If you see this error, check that your `FIREBASE_RTDB_URL` and `FIREBASE_KEY` secrets are set correctly.
|
||||
|
||||
### SQLite Database
|
||||
|
||||
To use a local SQLite database file to persist user data, set the following environment variables:
|
||||
|
||||
- `GATEKEEPER_STORE`: Set this to `sqlite`.
|
||||
- `SQLITE_USER_STORE_PATH` (Optional): Specifies the path to the SQLite database file.
|
||||
- If not set, it defaults to `data/user-store.sqlite` within the project directory.
|
||||
- Ensure that the directory where the SQLite file will be created (e.g., the `data/` directory) is writable by the application process.
|
||||
|
||||
Using SQLite provides a simple way to persist user data locally without relying on external services. User data will be saved to the specified file and will be available across server restarts.
|
||||
|
||||
## Whitelisting admin IP addresses
|
||||
You can add your own IP ranges to the `ADMIN_WHITELIST` environment variable for additional security.
|
||||
|
||||
You can provide a comma-separated list containing individual IPv4 or IPv6 addresses, or CIDR ranges.
|
||||
|
||||
To whitelist an entire IP range, use CIDR notation. For example, `192.168.0.1/24` would whitelist all addresses from `192.168.0.0` to `192.168.0.255`.
|
||||
|
||||
To disable the whitelist, set `ADMIN_WHITELIST=0.0.0.0/0,::0`, which will allow access from any IPv4 or IPv6 address. This is the default behavior.
|
||||
@@ -0,0 +1,36 @@
|
||||
# User Quotas
|
||||
|
||||
When using `user_token` authentication, you can set (model) token quotas for user. These quotas are enforced by the proxy server and are separate from the quotas enforced by OpenAI.
|
||||
|
||||
You can set the default quota via environment variables. Quotas are enforced on a per-model basis, and count both prompt tokens and completion tokens. By default, all quotas are disabled.
|
||||
|
||||
Set the following environment variables to set the default quotas:
|
||||
- `TOKEN_QUOTA_TURBO`
|
||||
- `TOKEN_QUOTA_GPT4`
|
||||
- `TOKEN_QUOTA_CLAUDE`
|
||||
|
||||
Quotas only apply to `normal`-type users; `special`-type users are exempt from quotas. You can change users' types via the REST API.
|
||||
|
||||
**Note that changes to these environment variables will only apply to newly created users.** To modify existing users' quotas, use the REST API or the admin UI.
|
||||
|
||||
## Automatically refreshing quotas
|
||||
|
||||
You can use the `QUOTA_REFRESH_PERIOD` environment variable to automatically refresh users' quotas periodically. This is useful if you want to give users a certain number of tokens per day, for example. The entire quota will be refreshed at the start of the specified period, and any tokens a user has not used will not be carried over.
|
||||
|
||||
Quotas for all models and users will be refreshed. If you haven't set `TOKEN_QUOTA_*` for a particular model, quotas for that model will not be refreshed (so any manually set quotas will not be overwritten).
|
||||
|
||||
Set the `QUOTA_REFRESH_PERIOD` environment variable to one of the following values:
|
||||
- `daily` (at midnight)
|
||||
- `hourly`
|
||||
- leave unset to disable automatic refreshing
|
||||
|
||||
You can also use a cron expression, for example:
|
||||
- Every 45 seconds: `"*/45 * * * * *"`
|
||||
- Every 30 minutes: `"*/30 * * * *"`
|
||||
- Every 6 hours: `"0 */6 * * *"`
|
||||
- Every 3 days: `"0 0 */3 * *"`
|
||||
- Daily, but at mid-day: `"0 12 * * *"`
|
||||
|
||||
Make sure to enclose the cron expression in quotation marks.
|
||||
|
||||
All times are in the server's local time zone. Refer to [crontab.guru](https://crontab.guru/) for more examples.
|
||||
@@ -0,0 +1,9 @@
|
||||
{
|
||||
"dev": {
|
||||
"proxy-host": "http://localhost:7860",
|
||||
"oai-key-1": "override in http-client.private.env.json",
|
||||
"proxy-key": "override in http-client.private.env.json",
|
||||
"azu-resource-name": "override in http-client.private.env.json",
|
||||
"azu-deployment-id": "override in http-client.private.env.json"
|
||||
}
|
||||
}
|
||||
Generated
+7261
File diff suppressed because it is too large
Load Diff
@@ -0,0 +1,96 @@
|
||||
{
|
||||
"name": "oai-reverse-proxy",
|
||||
"version": "1.0.0",
|
||||
"description": "Reverse proxy for the OpenAI API",
|
||||
"scripts": {
|
||||
"build": "tsc && copyfiles -u 1 src/**/*.ejs build",
|
||||
"database:migrate": "ts-node scripts/migrate.ts",
|
||||
"postinstall": "patch-package",
|
||||
"prepare": "husky install",
|
||||
"start": "node --trace-deprecation --trace-warnings build/server.js",
|
||||
"start:dev": "nodemon --watch src --exec ts-node --transpile-only src/server.ts",
|
||||
"start:debug": "ts-node --inspect --transpile-only src/server.ts",
|
||||
"start:watch": "nodemon --require source-map-support/register build/server.js",
|
||||
"type-check": "tsc --noEmit"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=18.0.0"
|
||||
},
|
||||
"author": "",
|
||||
"license": "MIT",
|
||||
"dependencies": {
|
||||
"@anthropic-ai/tokenizer": "^0.0.4",
|
||||
"@aws-crypto/sha256-js": "^5.2.0",
|
||||
"@huggingface/jinja": "^0.3.0",
|
||||
"@node-rs/argon2": "^1.8.3",
|
||||
"@smithy/eventstream-codec": "^2.1.3",
|
||||
"@smithy/eventstream-serde-node": "^2.1.3",
|
||||
"@smithy/protocol-http": "^3.2.1",
|
||||
"@smithy/signature-v4": "^2.1.3",
|
||||
"@smithy/util-utf8": "^2.1.1",
|
||||
"axios": "^1.7.4",
|
||||
"better-sqlite3": "^10.0.0",
|
||||
"check-disk-space": "^3.4.0",
|
||||
"cookie-parser": "^1.4.6",
|
||||
"copyfiles": "^2.4.1",
|
||||
"cors": "^2.8.5",
|
||||
"csrf-csrf": "^2.3.0",
|
||||
"dotenv": "^16.3.1",
|
||||
"ejs": "^3.1.10",
|
||||
"express": "^4.19.3",
|
||||
"express-session": "^1.17.3",
|
||||
"firebase-admin": "^12.5.0",
|
||||
"glob": "^10.3.12",
|
||||
"googleapis": "^122.0.0",
|
||||
"http-proxy": "1.18.1",
|
||||
"http-proxy-middleware": "^3.0.2",
|
||||
"ipaddr.js": "^2.1.0",
|
||||
"memorystore": "^1.6.7",
|
||||
"multer": "^1.4.5-lts.1",
|
||||
"node-schedule": "^2.1.1",
|
||||
"patch-package": "^8.0.0",
|
||||
"pino": "^8.11.0",
|
||||
"pino-http": "^8.3.3",
|
||||
"proxy-agent": "^6.4.0",
|
||||
"sanitize-html": "^2.13.0",
|
||||
"sharp": "^0.34.2",
|
||||
"showdown": "^2.1.0",
|
||||
"source-map-support": "^0.5.21",
|
||||
"stream-json": "^1.8.0",
|
||||
"tiktoken": "^1.0.10",
|
||||
"tinyws": "^0.1.0",
|
||||
"uuid": "^9.0.0",
|
||||
"zlib": "^1.0.5",
|
||||
"zod": "^3.22.3",
|
||||
"zod-error": "^1.5.0"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@smithy/types": "^3.3.0",
|
||||
"@types/better-sqlite3": "^7.6.10",
|
||||
"@types/cookie-parser": "^1.4.3",
|
||||
"@types/cors": "^2.8.13",
|
||||
"@types/express": "^4.17.17",
|
||||
"@types/express-session": "^1.17.7",
|
||||
"@types/multer": "^1.4.7",
|
||||
"@types/node-schedule": "^2.1.0",
|
||||
"@types/sanitize-html": "^2.9.0",
|
||||
"@types/showdown": "^2.0.0",
|
||||
"@types/stream-json": "^1.7.7",
|
||||
"@types/uuid": "^9.0.1",
|
||||
"concurrently": "^8.0.1",
|
||||
"esbuild": "^0.25.5",
|
||||
"esbuild-register": "^3.4.2",
|
||||
"husky": "^8.0.3",
|
||||
"nodemon": "^3.0.1",
|
||||
"pino-pretty": "^10.2.3",
|
||||
"prettier": "^3.0.3",
|
||||
"prettier-plugin-ejs": "^1.0.3",
|
||||
"ts-node": "^10.9.1",
|
||||
"typescript": "^5.4.2"
|
||||
},
|
||||
"overrides": {
|
||||
"node-fetch@2.x": {
|
||||
"whatwg-url": "14.x"
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,23 @@
|
||||
# Patches
|
||||
Contains monkey patches for certain packages, applied using `patch-package`.
|
||||
|
||||
## `http-proxy+1.18.1.patch`
|
||||
Modifies the `http-proxy` package to work around an incompatibility with
|
||||
body-parser and SOCKS5 proxies due to some esoteric stream handling behavior
|
||||
when `socks-proxy-agent` is used instead of a generic http.Agent.
|
||||
|
||||
Modification involves adjusting the `buffer` property on ProxyServer's `options`
|
||||
object to be a function that returns a stream instead of a stream itself. This
|
||||
allows us to give it a function which produces a new Readable from the already-
|
||||
parsed request body.
|
||||
|
||||
With the old implementation we would need to create an entirely new ProxyServer
|
||||
instance for each request, which is not ideal under heavy load.
|
||||
|
||||
`http-proxy` hasn't been updated in six years so it's unlikely that this patch
|
||||
will be broken by future updates, but it's stil pinned to 1.18.1 for now.
|
||||
|
||||
### See also
|
||||
https://github.com/chimurai/http-proxy-middleware/issues/40
|
||||
https://github.com/chimurai/http-proxy-middleware/issues/299
|
||||
https://github.com/http-party/node-http-proxy/pull/1027
|
||||
@@ -0,0 +1,13 @@
|
||||
diff --git a/node_modules/http-proxy/lib/http-proxy/passes/web-incoming.js b/node_modules/http-proxy/lib/http-proxy/passes/web-incoming.js
|
||||
index 7ae7355..c825c27 100644
|
||||
--- a/node_modules/http-proxy/lib/http-proxy/passes/web-incoming.js
|
||||
+++ b/node_modules/http-proxy/lib/http-proxy/passes/web-incoming.js
|
||||
@@ -167,7 +167,7 @@ module.exports = {
|
||||
}
|
||||
}
|
||||
|
||||
- (options.buffer || req).pipe(proxyReq);
|
||||
+ (options.buffer(req) || req).pipe(proxyReq);
|
||||
|
||||
proxyReq.on('response', function(proxyRes) {
|
||||
if(server) { server.emit('proxyRes', proxyRes, req, res); }
|
||||
@@ -0,0 +1,349 @@
|
||||
/*! normalize.css v8.0.1 | MIT License | github.com/necolas/normalize.css */
|
||||
|
||||
/* Document
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* 1. Correct the line height in all browsers.
|
||||
* 2. Prevent adjustments of font size after orientation changes in iOS.
|
||||
*/
|
||||
|
||||
html {
|
||||
line-height: 1.15; /* 1 */
|
||||
-webkit-text-size-adjust: 100%; /* 2 */
|
||||
}
|
||||
|
||||
/* Sections
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* Remove the margin in all browsers.
|
||||
*/
|
||||
|
||||
body {
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
/**
|
||||
* Render the `main` element consistently in IE.
|
||||
*/
|
||||
|
||||
main {
|
||||
display: block;
|
||||
}
|
||||
|
||||
/**
|
||||
* Correct the font size and margin on `h1` elements within `section` and
|
||||
* `article` contexts in Chrome, Firefox, and Safari.
|
||||
*/
|
||||
|
||||
h1 {
|
||||
font-size: 2em;
|
||||
margin: 0.67em 0;
|
||||
}
|
||||
|
||||
/* Grouping content
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* 1. Add the correct box sizing in Firefox.
|
||||
* 2. Show the overflow in Edge and IE.
|
||||
*/
|
||||
|
||||
hr {
|
||||
box-sizing: content-box; /* 1 */
|
||||
height: 0; /* 1 */
|
||||
overflow: visible; /* 2 */
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Correct the inheritance and scaling of font size in all browsers.
|
||||
* 2. Correct the odd `em` font sizing in all browsers.
|
||||
*/
|
||||
|
||||
pre {
|
||||
font-family: monospace, monospace; /* 1 */
|
||||
font-size: 1em; /* 2 */
|
||||
}
|
||||
|
||||
/* Text-level semantics
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* Remove the gray background on active links in IE 10.
|
||||
*/
|
||||
|
||||
a {
|
||||
background-color: transparent;
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Remove the bottom border in Chrome 57-
|
||||
* 2. Add the correct text decoration in Chrome, Edge, IE, Opera, and Safari.
|
||||
*/
|
||||
|
||||
abbr[title] {
|
||||
border-bottom: none; /* 1 */
|
||||
text-decoration: underline; /* 2 */
|
||||
text-decoration: underline dotted; /* 2 */
|
||||
}
|
||||
|
||||
/**
|
||||
* Add the correct font weight in Chrome, Edge, and Safari.
|
||||
*/
|
||||
|
||||
b,
|
||||
strong {
|
||||
font-weight: bolder;
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Correct the inheritance and scaling of font size in all browsers.
|
||||
* 2. Correct the odd `em` font sizing in all browsers.
|
||||
*/
|
||||
|
||||
code,
|
||||
kbd,
|
||||
samp {
|
||||
font-family: monospace, monospace; /* 1 */
|
||||
font-size: 1em; /* 2 */
|
||||
}
|
||||
|
||||
/**
|
||||
* Add the correct font size in all browsers.
|
||||
*/
|
||||
|
||||
small {
|
||||
font-size: 80%;
|
||||
}
|
||||
|
||||
/**
|
||||
* Prevent `sub` and `sup` elements from affecting the line height in
|
||||
* all browsers.
|
||||
*/
|
||||
|
||||
sub,
|
||||
sup {
|
||||
font-size: 75%;
|
||||
line-height: 0;
|
||||
position: relative;
|
||||
vertical-align: baseline;
|
||||
}
|
||||
|
||||
sub {
|
||||
bottom: -0.25em;
|
||||
}
|
||||
|
||||
sup {
|
||||
top: -0.5em;
|
||||
}
|
||||
|
||||
/* Embedded content
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* Remove the border on images inside links in IE 10.
|
||||
*/
|
||||
|
||||
img {
|
||||
border-style: none;
|
||||
}
|
||||
|
||||
/* Forms
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* 1. Change the font styles in all browsers.
|
||||
* 2. Remove the margin in Firefox and Safari.
|
||||
*/
|
||||
|
||||
button,
|
||||
input,
|
||||
optgroup,
|
||||
select,
|
||||
textarea {
|
||||
font-family: inherit; /* 1 */
|
||||
font-size: 100%; /* 1 */
|
||||
line-height: 1.15; /* 1 */
|
||||
margin: 0; /* 2 */
|
||||
}
|
||||
|
||||
/**
|
||||
* Show the overflow in IE.
|
||||
* 1. Show the overflow in Edge.
|
||||
*/
|
||||
|
||||
button,
|
||||
input { /* 1 */
|
||||
overflow: visible;
|
||||
}
|
||||
|
||||
/**
|
||||
* Remove the inheritance of text transform in Edge, Firefox, and IE.
|
||||
* 1. Remove the inheritance of text transform in Firefox.
|
||||
*/
|
||||
|
||||
button,
|
||||
select { /* 1 */
|
||||
text-transform: none;
|
||||
}
|
||||
|
||||
/**
|
||||
* Correct the inability to style clickable types in iOS and Safari.
|
||||
*/
|
||||
|
||||
button,
|
||||
[type="button"],
|
||||
[type="reset"],
|
||||
[type="submit"] {
|
||||
-webkit-appearance: button;
|
||||
}
|
||||
|
||||
/**
|
||||
* Remove the inner border and padding in Firefox.
|
||||
*/
|
||||
|
||||
button::-moz-focus-inner,
|
||||
[type="button"]::-moz-focus-inner,
|
||||
[type="reset"]::-moz-focus-inner,
|
||||
[type="submit"]::-moz-focus-inner {
|
||||
border-style: none;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
/**
|
||||
* Restore the focus styles unset by the previous rule.
|
||||
*/
|
||||
|
||||
button:-moz-focusring,
|
||||
[type="button"]:-moz-focusring,
|
||||
[type="reset"]:-moz-focusring,
|
||||
[type="submit"]:-moz-focusring {
|
||||
outline: 1px dotted ButtonText;
|
||||
}
|
||||
|
||||
/**
|
||||
* Correct the padding in Firefox.
|
||||
*/
|
||||
|
||||
fieldset {
|
||||
padding: 0.35em 0.75em 0.625em;
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Correct the text wrapping in Edge and IE.
|
||||
* 2. Correct the color inheritance from `fieldset` elements in IE.
|
||||
* 3. Remove the padding so developers are not caught out when they zero out
|
||||
* `fieldset` elements in all browsers.
|
||||
*/
|
||||
|
||||
legend {
|
||||
box-sizing: border-box; /* 1 */
|
||||
color: inherit; /* 2 */
|
||||
display: table; /* 1 */
|
||||
max-width: 100%; /* 1 */
|
||||
padding: 0; /* 3 */
|
||||
white-space: normal; /* 1 */
|
||||
}
|
||||
|
||||
/**
|
||||
* Add the correct vertical alignment in Chrome, Firefox, and Opera.
|
||||
*/
|
||||
|
||||
progress {
|
||||
vertical-align: baseline;
|
||||
}
|
||||
|
||||
/**
|
||||
* Remove the default vertical scrollbar in IE 10+.
|
||||
*/
|
||||
|
||||
textarea {
|
||||
overflow: auto;
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Add the correct box sizing in IE 10.
|
||||
* 2. Remove the padding in IE 10.
|
||||
*/
|
||||
|
||||
[type="checkbox"],
|
||||
[type="radio"] {
|
||||
box-sizing: border-box; /* 1 */
|
||||
padding: 0; /* 2 */
|
||||
}
|
||||
|
||||
/**
|
||||
* Correct the cursor style of increment and decrement buttons in Chrome.
|
||||
*/
|
||||
|
||||
[type="number"]::-webkit-inner-spin-button,
|
||||
[type="number"]::-webkit-outer-spin-button {
|
||||
height: auto;
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Correct the odd appearance in Chrome and Safari.
|
||||
* 2. Correct the outline style in Safari.
|
||||
*/
|
||||
|
||||
[type="search"] {
|
||||
-webkit-appearance: textfield; /* 1 */
|
||||
outline-offset: -2px; /* 2 */
|
||||
}
|
||||
|
||||
/**
|
||||
* Remove the inner padding in Chrome and Safari on macOS.
|
||||
*/
|
||||
|
||||
[type="search"]::-webkit-search-decoration {
|
||||
-webkit-appearance: none;
|
||||
}
|
||||
|
||||
/**
|
||||
* 1. Correct the inability to style clickable types in iOS and Safari.
|
||||
* 2. Change font properties to `inherit` in Safari.
|
||||
*/
|
||||
|
||||
::-webkit-file-upload-button {
|
||||
-webkit-appearance: button; /* 1 */
|
||||
font: inherit; /* 2 */
|
||||
}
|
||||
|
||||
/* Interactive
|
||||
========================================================================== */
|
||||
|
||||
/*
|
||||
* Add the correct display in Edge, IE 10+, and Firefox.
|
||||
*/
|
||||
|
||||
details {
|
||||
display: block;
|
||||
}
|
||||
|
||||
/*
|
||||
* Add the correct display in all browsers.
|
||||
*/
|
||||
|
||||
summary {
|
||||
display: list-item;
|
||||
}
|
||||
|
||||
/* Misc
|
||||
========================================================================== */
|
||||
|
||||
/**
|
||||
* Add the correct display in IE 10+.
|
||||
*/
|
||||
|
||||
template {
|
||||
display: none;
|
||||
}
|
||||
|
||||
/**
|
||||
* Add the correct display in IE 10.
|
||||
*/
|
||||
|
||||
[hidden] {
|
||||
display: none;
|
||||
}
|
||||
@@ -0,0 +1,231 @@
|
||||
/* modified https://github.com/oxalorg/sakura */
|
||||
html {
|
||||
font-size: 62.5%;
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto,
|
||||
"Helvetica Neue", Arial, "Noto Sans", sans-serif;
|
||||
}
|
||||
body {
|
||||
font-size: 1.8rem;
|
||||
line-height: 1.618;
|
||||
max-width: 38em;
|
||||
margin: auto;
|
||||
color: #c9c9c9;
|
||||
background-color: #222222;
|
||||
padding: 13px;
|
||||
}
|
||||
@media (max-width: 684px) {
|
||||
body {
|
||||
font-size: 1.53rem;
|
||||
}
|
||||
}
|
||||
@media (max-width: 382px) {
|
||||
body {
|
||||
font-size: 1.35rem;
|
||||
}
|
||||
}
|
||||
h1,
|
||||
h2,
|
||||
h3,
|
||||
h4,
|
||||
h5,
|
||||
h6 {
|
||||
line-height: 1.1;
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto,
|
||||
"Helvetica Neue", Arial, "Noto Sans", sans-serif;
|
||||
font-weight: 700;
|
||||
margin-top: 3rem;
|
||||
margin-bottom: 1.5rem;
|
||||
overflow-wrap: break-word;
|
||||
word-wrap: break-word;
|
||||
-ms-word-break: break-all;
|
||||
word-break: break-word;
|
||||
}
|
||||
h1 {
|
||||
font-size: 2.35em;
|
||||
}
|
||||
h2 {
|
||||
font-size: 2em;
|
||||
}
|
||||
h3 {
|
||||
font-size: 1.75em;
|
||||
}
|
||||
h4 {
|
||||
font-size: 1.5em;
|
||||
}
|
||||
h5 {
|
||||
font-size: 1.25em;
|
||||
}
|
||||
h6 {
|
||||
font-size: 1em;
|
||||
}
|
||||
p {
|
||||
margin-top: 0px;
|
||||
margin-bottom: 2.5rem;
|
||||
}
|
||||
small,
|
||||
sub,
|
||||
sup {
|
||||
font-size: 75%;
|
||||
}
|
||||
hr {
|
||||
border-color: #ffffff;
|
||||
}
|
||||
a {
|
||||
text-decoration: none;
|
||||
color: #ffffff;
|
||||
}
|
||||
a:visited {
|
||||
color: #e6e6e6;
|
||||
}
|
||||
a:hover {
|
||||
color: #c9c9c9;
|
||||
text-decoration: underline;
|
||||
}
|
||||
ul {
|
||||
padding-left: 1.4em;
|
||||
margin-top: 0px;
|
||||
margin-bottom: 2.5rem;
|
||||
}
|
||||
li {
|
||||
margin-bottom: 0.4em;
|
||||
}
|
||||
blockquote {
|
||||
margin-left: 0px;
|
||||
margin-right: 0px;
|
||||
padding-left: 1em;
|
||||
padding-top: 0.8em;
|
||||
padding-bottom: 0.8em;
|
||||
padding-right: 0.8em;
|
||||
border-left: 5px solid #ffffff;
|
||||
margin-bottom: 2.5rem;
|
||||
background-color: #4a4a4a;
|
||||
}
|
||||
blockquote p {
|
||||
margin-bottom: 0;
|
||||
}
|
||||
img,
|
||||
video {
|
||||
height: auto;
|
||||
max-width: 100%;
|
||||
margin-top: 0px;
|
||||
margin-bottom: 2.5rem;
|
||||
}
|
||||
pre {
|
||||
background-color: #4a4a4a;
|
||||
display: block;
|
||||
padding: 1em;
|
||||
overflow-x: auto;
|
||||
margin-top: 0px;
|
||||
margin-bottom: 2.5rem;
|
||||
font-size: 0.9em;
|
||||
}
|
||||
code,
|
||||
kbd,
|
||||
samp {
|
||||
font-size: 0.9em;
|
||||
padding: 0 0.5em;
|
||||
background-color: #4a4a4a;
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
pre > code {
|
||||
padding: 0;
|
||||
background-color: transparent;
|
||||
white-space: pre;
|
||||
font-size: 1em;
|
||||
}
|
||||
table {
|
||||
text-align: justify;
|
||||
width: 100%;
|
||||
border-collapse: collapse;
|
||||
margin-bottom: 2rem;
|
||||
}
|
||||
td,
|
||||
th {
|
||||
padding: 0.5em;
|
||||
border-bottom: 1px solid #4a4a4a;
|
||||
}
|
||||
input,
|
||||
textarea {
|
||||
border: 1px solid #c9c9c9;
|
||||
}
|
||||
input:focus,
|
||||
textarea:focus {
|
||||
border: 1px solid #ffffff;
|
||||
}
|
||||
textarea {
|
||||
width: 100%;
|
||||
}
|
||||
.button,
|
||||
button,
|
||||
input[type="submit"],
|
||||
input[type="reset"],
|
||||
input[type="button"],
|
||||
input[type="file"]::file-selector-button {
|
||||
display: inline-block;
|
||||
padding: 5px 10px;
|
||||
text-align: center;
|
||||
text-decoration: none;
|
||||
white-space: nowrap;
|
||||
background-color: #ffffff;
|
||||
color: #222222;
|
||||
border-radius: 1px;
|
||||
border: 1px solid #ffffff;
|
||||
cursor: pointer;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
.button[disabled],
|
||||
button[disabled],
|
||||
input[type="submit"][disabled],
|
||||
input[type="reset"][disabled],
|
||||
input[type="button"][disabled],
|
||||
input[type="file"][disabled] {
|
||||
cursor: default;
|
||||
opacity: 0.5;
|
||||
}
|
||||
.button:hover,
|
||||
button:hover,
|
||||
input[type="submit"]:hover,
|
||||
input[type="reset"]:hover,
|
||||
input[type="button"]:hover,
|
||||
input[type="file"]::file-selector-button:hover {
|
||||
background-color: #c9c9c9;
|
||||
color: #222222;
|
||||
outline: 0;
|
||||
}
|
||||
.button:focus-visible,
|
||||
button:focus-visible,
|
||||
input[type="submit"]:focus-visible,
|
||||
input[type="reset"]:focus-visible,
|
||||
input[type="button"]:focus-visible,
|
||||
input[type="file"]::file-selector-button:focus-visible {
|
||||
outline-style: solid;
|
||||
outline-width: 2px;
|
||||
}
|
||||
textarea,
|
||||
select,
|
||||
input {
|
||||
color: #c9c9c9;
|
||||
padding: 6px 10px;
|
||||
margin-bottom: 10px;
|
||||
background-color: #4a4a4a;
|
||||
border: 1px solid #4a4a4a;
|
||||
border-radius: 4px;
|
||||
box-shadow: none;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
textarea:focus,
|
||||
select:focus,
|
||||
input:focus {
|
||||
border: 1px solid #ffffff;
|
||||
outline: 0;
|
||||
}
|
||||
input[type="checkbox"]:focus {
|
||||
outline: 1px dotted #ffffff;
|
||||
}
|
||||
label,
|
||||
legend,
|
||||
fieldset {
|
||||
display: block;
|
||||
margin-bottom: 0.5rem;
|
||||
font-weight: 600;
|
||||
}
|
||||
@@ -0,0 +1,237 @@
|
||||
/* modified https://github.com/oxalorg/sakura */
|
||||
:root {
|
||||
--accent-color: #4a4a4a;
|
||||
--accent-color-hover: #5a5a5a;
|
||||
--link-color: #58739c;
|
||||
--link-visted-color: #6f5e6f;
|
||||
}
|
||||
html {
|
||||
font-size: 62.5%;
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto,
|
||||
"Helvetica Neue", Arial, "Noto Sans", sans-serif;
|
||||
}
|
||||
body {
|
||||
font-size: 1.8rem;
|
||||
line-height: 1.618;
|
||||
max-width: 38em;
|
||||
margin: auto;
|
||||
color: #4a4a4a;
|
||||
background-color: #f9f9f9;
|
||||
padding: 13px;
|
||||
}
|
||||
@media (max-width: 684px) {
|
||||
body {
|
||||
font-size: 1.53rem;
|
||||
}
|
||||
}
|
||||
@media (max-width: 382px) {
|
||||
body {
|
||||
font-size: 1.35rem;
|
||||
}
|
||||
}
|
||||
h1,
|
||||
h2,
|
||||
h3,
|
||||
h4,
|
||||
h5,
|
||||
h6 {
|
||||
line-height: 1.1;
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto,
|
||||
"Helvetica Neue", Arial, "Noto Sans", sans-serif;
|
||||
font-weight: 700;
|
||||
margin-top: 3rem;
|
||||
margin-bottom: 1.5rem;
|
||||
overflow-wrap: break-word;
|
||||
word-wrap: break-word;
|
||||
-ms-word-break: break-all;
|
||||
word-break: break-word;
|
||||
}
|
||||
h1 {
|
||||
font-size: 2.35em;
|
||||
}
|
||||
h2 {
|
||||
font-size: 2em;
|
||||
}
|
||||
h3 {
|
||||
font-size: 1.75em;
|
||||
}
|
||||
h4 {
|
||||
font-size: 1.5em;
|
||||
}
|
||||
h5 {
|
||||
font-size: 1.25em;
|
||||
}
|
||||
h6 {
|
||||
font-size: 1em;
|
||||
}
|
||||
p {
|
||||
margin-top: 0;
|
||||
margin-bottom: 2.5rem;
|
||||
}
|
||||
small,
|
||||
sub,
|
||||
sup {
|
||||
font-size: 75%;
|
||||
}
|
||||
hr {
|
||||
border-color: var(--accent-color);
|
||||
}
|
||||
a {
|
||||
text-decoration: none;
|
||||
color: var(--link-color);
|
||||
}
|
||||
a:visited {
|
||||
color: var(--link-visted-color);
|
||||
}
|
||||
a:hover {
|
||||
color: var(--accent-color-hover);
|
||||
text-decoration: underline;
|
||||
}
|
||||
ul {
|
||||
padding-left: 1.4em;
|
||||
margin-top: 0;
|
||||
margin-bottom: 2.5rem;
|
||||
}
|
||||
li {
|
||||
margin-bottom: 0.4em;
|
||||
}
|
||||
blockquote {
|
||||
margin-left: 0;
|
||||
margin-right: 0;
|
||||
padding-left: 1em;
|
||||
padding-top: 0.8em;
|
||||
padding-bottom: 0.8em;
|
||||
padding-right: 0.8em;
|
||||
border-left: 5px solid var(--accent-color);
|
||||
margin-bottom: 2.5rem;
|
||||
background-color: #f1f1f1;
|
||||
}
|
||||
blockquote p {
|
||||
margin-bottom: 0;
|
||||
}
|
||||
img,
|
||||
video {
|
||||
height: auto;
|
||||
max-width: 100%;
|
||||
margin-top: 0;
|
||||
margin-bottom: 2.5rem;
|
||||
}
|
||||
pre {
|
||||
background-color: #f1f1f1;
|
||||
display: block;
|
||||
padding: 1em;
|
||||
overflow-x: auto;
|
||||
margin-top: 0;
|
||||
margin-bottom: 2.5rem;
|
||||
font-size: 0.9em;
|
||||
}
|
||||
code,
|
||||
kbd,
|
||||
samp {
|
||||
font-size: 0.9em;
|
||||
padding: 0 0.5em;
|
||||
background-color: #f1f1f1;
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
pre > code {
|
||||
padding: 0;
|
||||
background-color: transparent;
|
||||
white-space: pre;
|
||||
font-size: 1em;
|
||||
}
|
||||
table {
|
||||
text-align: justify;
|
||||
width: 100%;
|
||||
border-collapse: collapse;
|
||||
margin-bottom: 2rem;
|
||||
}
|
||||
td,
|
||||
th {
|
||||
padding: 0.5em;
|
||||
border-bottom: 1px solid #f1f1f1;
|
||||
}
|
||||
input,
|
||||
textarea {
|
||||
border: 1px solid #4a4a4a;
|
||||
}
|
||||
input:focus,
|
||||
textarea:focus {
|
||||
border: 1px solid var(--accent-color);
|
||||
}
|
||||
textarea {
|
||||
width: 100%;
|
||||
}
|
||||
.button,
|
||||
button,
|
||||
input[type="submit"],
|
||||
input[type="reset"],
|
||||
input[type="button"],
|
||||
input[type="file"]::file-selector-button {
|
||||
display: inline-block;
|
||||
padding: 5px 10px;
|
||||
text-align: center;
|
||||
text-decoration: none;
|
||||
white-space: nowrap;
|
||||
background-color: var(--accent-color);
|
||||
color: #f9f9f9;
|
||||
border-radius: 2px;
|
||||
border: 1px solid var(--accent-color);
|
||||
cursor: pointer;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
.button[disabled],
|
||||
button[disabled],
|
||||
input[type="submit"][disabled],
|
||||
input[type="reset"][disabled],
|
||||
input[type="button"][disabled],
|
||||
input[type="file"][disabled] {
|
||||
cursor: default;
|
||||
opacity: 0.5;
|
||||
}
|
||||
.button:hover,
|
||||
button:hover,
|
||||
input[type="submit"]:hover,
|
||||
input[type="reset"]:hover,
|
||||
input[type="button"]:hover,
|
||||
input[type="file"]::file-selector-button:hover {
|
||||
background-color: var(--accent-color-hover);
|
||||
color: #f9f9f9;
|
||||
outline: 0;
|
||||
}
|
||||
.button:focus-visible,
|
||||
button:focus-visible,
|
||||
input[type="submit"]:focus-visible,
|
||||
input[type="reset"]:focus-visible,
|
||||
input[type="button"]:focus-visible,
|
||||
input[type="file"]::file-selector-button:focus-visible {
|
||||
outline-style: solid;
|
||||
outline-width: 2px;
|
||||
}
|
||||
textarea,
|
||||
select,
|
||||
input {
|
||||
color: #4a4a4a;
|
||||
padding: 6px 10px;
|
||||
margin-bottom: 10px;
|
||||
background-color: #f1f1f1;
|
||||
border: 1px solid #f1f1f1;
|
||||
border-radius: 4px;
|
||||
box-shadow: none;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
textarea:focus,
|
||||
select:focus,
|
||||
input:focus {
|
||||
border: 1px solid var(--accent-color);
|
||||
outline: 0;
|
||||
}
|
||||
input[type="checkbox"]:focus {
|
||||
outline: 1px dotted var(--accent-color);
|
||||
}
|
||||
label,
|
||||
legend,
|
||||
fieldset {
|
||||
display: block;
|
||||
margin-bottom: 0.5rem;
|
||||
font-weight: 600;
|
||||
}
|
||||
@@ -0,0 +1,120 @@
|
||||
importScripts(
|
||||
"https://cdn.jsdelivr.net/npm/hash-wasm@4.11.0/dist/argon2.umd.min.js"
|
||||
);
|
||||
|
||||
let active = false;
|
||||
let nonce = 0;
|
||||
let signature = "";
|
||||
let lastNotify = 0;
|
||||
let hashesSinceLastNotify = 0;
|
||||
let params = {
|
||||
salt: null,
|
||||
hashLength: 0,
|
||||
iterations: 0,
|
||||
memorySize: 0,
|
||||
parallelism: 0,
|
||||
targetValue: BigInt(0),
|
||||
safariFix: false,
|
||||
};
|
||||
|
||||
self.onmessage = async (event) => {
|
||||
const { data } = event;
|
||||
switch (data.type) {
|
||||
case "stop":
|
||||
active = false;
|
||||
self.postMessage({ type: "paused", hashes: hashesSinceLastNotify });
|
||||
return;
|
||||
case "start":
|
||||
active = true;
|
||||
signature = data.signature;
|
||||
nonce = data.nonce;
|
||||
|
||||
const c = data.challenge;
|
||||
const salt = new Uint8Array(c.s.length / 2);
|
||||
for (let i = 0; i < c.s.length; i += 2) {
|
||||
salt[i / 2] = parseInt(c.s.slice(i, i + 2), 16);
|
||||
}
|
||||
|
||||
params = {
|
||||
salt: salt,
|
||||
hashLength: c.hl,
|
||||
iterations: c.t,
|
||||
memorySize: c.m,
|
||||
parallelism: c.p,
|
||||
targetValue: BigInt(c.d.slice(0, -1)),
|
||||
safariFix: data.isMobileWebkit,
|
||||
};
|
||||
|
||||
console.log("Started", params);
|
||||
self.postMessage({ type: "started" });
|
||||
setTimeout(solve, 0);
|
||||
break;
|
||||
}
|
||||
};
|
||||
|
||||
const doHash = async (password) => {
|
||||
const { salt, hashLength, iterations, memorySize, parallelism } = params;
|
||||
return await self.hashwasm.argon2id({
|
||||
password,
|
||||
salt,
|
||||
hashLength,
|
||||
iterations,
|
||||
memorySize,
|
||||
parallelism,
|
||||
});
|
||||
};
|
||||
|
||||
const checkHash = (hash) => {
|
||||
const { targetValue } = params;
|
||||
const hashValue = BigInt(`0x${hash}`);
|
||||
return hashValue <= targetValue;
|
||||
};
|
||||
|
||||
const solve = async () => {
|
||||
if (!active) {
|
||||
console.log("Stopped solver", nonce);
|
||||
return;
|
||||
}
|
||||
|
||||
// Safari WASM doesn't like multiple calls in one worker
|
||||
const batchSize = 1;
|
||||
const batch = [];
|
||||
for (let i = 0; i < batchSize; i++) {
|
||||
batch.push(nonce++);
|
||||
}
|
||||
|
||||
try {
|
||||
const results = await Promise.all(
|
||||
batch.map(async (nonce) => {
|
||||
const hash = await doHash(String(nonce));
|
||||
return { hash, nonce };
|
||||
})
|
||||
);
|
||||
hashesSinceLastNotify += batchSize;
|
||||
|
||||
const solution = results.find(({ hash }) => checkHash(hash));
|
||||
if (solution) {
|
||||
console.log("Solution found", solution, params.salt);
|
||||
self.postMessage({ type: "solved", nonce: solution.nonce });
|
||||
active = false;
|
||||
} else {
|
||||
if (Date.now() - lastNotify >= 500) {
|
||||
console.log("Last nonce", nonce, "Hashes", hashesSinceLastNotify);
|
||||
self.postMessage({ type: "progress", hashes: hashesSinceLastNotify });
|
||||
lastNotify = Date.now();
|
||||
hashesSinceLastNotify = 0;
|
||||
}
|
||||
setTimeout(solve, 10);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error("Error", error);
|
||||
const stack = error.stack;
|
||||
const debug = {
|
||||
stack,
|
||||
lastNonce: nonce,
|
||||
targetValue: params.targetValue,
|
||||
};
|
||||
self.postMessage({ type: "error", error: error.message, debug });
|
||||
active = false;
|
||||
}
|
||||
};
|
||||
+10
@@ -0,0 +1,10 @@
|
||||
services:
|
||||
- type: web
|
||||
name: oai-proxy
|
||||
env: docker
|
||||
repo: https://gitlab.com/khanon/oai-proxy.git
|
||||
region: oregon
|
||||
plan: free
|
||||
branch: main
|
||||
healthCheckPath: /health
|
||||
dockerfilePath: ./docker/render/Dockerfile
|
||||
@@ -0,0 +1,39 @@
|
||||
import Database from "better-sqlite3";
|
||||
import { DATABASE_VERSION, migrateDatabase } from "../src/shared/database";
|
||||
import { logger } from "../src/logger";
|
||||
import { config } from "../src/config";
|
||||
|
||||
const log = logger.child({ module: "scripts/migrate" });
|
||||
|
||||
async function runMigration() {
|
||||
let targetVersion = Number(process.argv[2]) || undefined;
|
||||
|
||||
if (!targetVersion) {
|
||||
log.info("Enter target version or leave empty to use the latest version.");
|
||||
process.stdin.resume();
|
||||
process.stdin.setEncoding("utf8");
|
||||
const input = await new Promise<string>((resolve) => {
|
||||
process.stdin.on("data", (text) => {
|
||||
resolve((String(text) || "").trim());
|
||||
});
|
||||
});
|
||||
process.stdin.pause();
|
||||
targetVersion = Number(input);
|
||||
if (!targetVersion) {
|
||||
targetVersion = DATABASE_VERSION;
|
||||
}
|
||||
}
|
||||
|
||||
const db = new Database(config.sqliteDataPath, {
|
||||
verbose: (msg, ...args) => log.debug({ args }, String(msg)),
|
||||
});
|
||||
|
||||
const currentVersion = db.pragma("user_version", { simple: true });
|
||||
log.info({ currentVersion, targetVersion }, "Running migrations.");
|
||||
migrateDatabase(targetVersion, db);
|
||||
}
|
||||
|
||||
runMigration().catch((error) => {
|
||||
log.error(error, "Migration failed.");
|
||||
process.exit(1);
|
||||
});
|
||||
@@ -0,0 +1,309 @@
|
||||
# OAI Reverse Proxy
|
||||
|
||||
###
|
||||
# @name OpenAI -- Chat Completions
|
||||
POST https://api.openai.com/v1/chat/completions
|
||||
Authorization: Bearer {{oai-key-1}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"max_tokens": 30,
|
||||
"stream": false,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "This is a test prompt."
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name OpenAI -- Text Completions
|
||||
POST https://api.openai.com/v1/completions
|
||||
Authorization: Bearer {{oai-key-1}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-3.5-turbo-instruct",
|
||||
"max_tokens": 30,
|
||||
"stream": false,
|
||||
"prompt": "This is a test prompt where"
|
||||
}
|
||||
|
||||
###
|
||||
# @name OpenAI -- Create Embedding
|
||||
POST https://api.openai.com/v1/embeddings
|
||||
Authorization: Bearer {{oai-key-1}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "text-embedding-ada-002",
|
||||
"input": "This is a test embedding input."
|
||||
}
|
||||
|
||||
###
|
||||
# @name OpenAI -- Get Organizations
|
||||
GET https://api.openai.com/v1/organizations
|
||||
Authorization: Bearer {{oai-key-1}}
|
||||
|
||||
###
|
||||
# @name OpenAI -- Get Models
|
||||
GET https://api.openai.com/v1/models
|
||||
Authorization: Bearer {{oai-key-1}}
|
||||
|
||||
###
|
||||
# @name Azure OpenAI -- Chat Completions
|
||||
POST https://{{azu-resource-name}}.openai.azure.com/openai/deployments/{{azu-deployment-id}}/chat/completions?api-version=2023-09-01-preview
|
||||
api-key: {{azu-key-1}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"max_tokens": 1,
|
||||
"stream": false,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "This is a test prompt."
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / OpenAI -- Get Models
|
||||
GET {{proxy-host}}/proxy/openai/v1/models
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
|
||||
###
|
||||
# @name Proxy / OpenAI -- Native Chat Completions
|
||||
POST {{proxy-host}}/proxy/openai/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-4-1106-preview",
|
||||
"max_tokens": 20,
|
||||
"stream": true,
|
||||
"temperature": 1,
|
||||
"seed": 123,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "phrase one"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / OpenAI -- Native Text Completions
|
||||
POST {{proxy-host}}/proxy/openai/v1/turbo-instruct/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-3.5-turbo-instruct",
|
||||
"max_tokens": 20,
|
||||
"temperature": 0,
|
||||
"prompt": "Genshin Impact is a game about",
|
||||
"stream": false
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / OpenAI -- Chat-to-Text API Translation
|
||||
# Accepts a chat completion request and reformats it to work with the text completion API. `model` is ignored.
|
||||
POST {{proxy-host}}/proxy/openai/turbo-instruct/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-4",
|
||||
"max_tokens": 20,
|
||||
"stream": true,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What is the name of the fourth president of the united states?"
|
||||
},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "That would be George Washington."
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": "I don't think that's right..."
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / OpenAI -- Create Embedding
|
||||
POST {{proxy-host}}/proxy/openai/embeddings
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "text-embedding-ada-002",
|
||||
"input": "This is a test embedding input."
|
||||
}
|
||||
|
||||
|
||||
###
|
||||
# @name Proxy / Anthropic -- Native Completion (old API)
|
||||
POST {{proxy-host}}/proxy/anthropic/v1/complete
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
anthropic-version: 2023-01-01
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "claude-v1.3",
|
||||
"max_tokens_to_sample": 20,
|
||||
"temperature": 0.2,
|
||||
"stream": true,
|
||||
"prompt": "What is genshin impact\n\n:Assistant:"
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / Anthropic -- Native Completion (2023-06-01 API)
|
||||
POST {{proxy-host}}/proxy/anthropic/v1/complete
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
anthropic-version: 2023-06-01
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "claude-v1.3",
|
||||
"max_tokens_to_sample": 20,
|
||||
"temperature": 0.2,
|
||||
"stream": true,
|
||||
"prompt": "What is genshin impact\n\n:Assistant:"
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / Anthropic -- OpenAI-to-Anthropic API Translation
|
||||
POST {{proxy-host}}/proxy/anthropic/v1/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
#anthropic-version: 2023-06-01
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"max_tokens": 20,
|
||||
"stream": false,
|
||||
"temperature": 0,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What is genshin impact"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / AWS Claude -- Native Completion
|
||||
POST {{proxy-host}}/proxy/aws/claude/v1/complete
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
anthropic-version: 2023-01-01
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "claude-v2",
|
||||
"max_tokens_to_sample": 10,
|
||||
"temperature": 0,
|
||||
"stream": true,
|
||||
"prompt": "What is genshin impact\n\n:Assistant:"
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / AWS Claude -- OpenAI-to-Anthropic API Translation
|
||||
POST {{proxy-host}}/proxy/aws/claude/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"max_tokens": 50,
|
||||
"stream": true,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What is genshin impact?"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / GCP Claude -- Native Completion
|
||||
POST {{proxy-host}}/proxy/gcp/claude/v1/complete
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
anthropic-version: 2023-01-01
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "claude-v2",
|
||||
"max_tokens_to_sample": 10,
|
||||
"temperature": 0,
|
||||
"stream": true,
|
||||
"prompt": "What is genshin impact\n\n:Assistant:"
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / GCP Claude -- OpenAI-to-Anthropic API Translation
|
||||
POST {{proxy-host}}/proxy/gcp/claude/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-3.5-turbo",
|
||||
"max_tokens": 50,
|
||||
"stream": true,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "What is genshin impact?"
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / Azure OpenAI -- Native Chat Completions
|
||||
POST {{proxy-host}}/proxy/azure/openai/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-4",
|
||||
"max_tokens": 20,
|
||||
"stream": true,
|
||||
"temperature": 1,
|
||||
"seed": 2,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Hi what is the name of the fourth president of the united states?"
|
||||
},
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": "That would be George Washington."
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": "That's not right."
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
###
|
||||
# @name Proxy / Google AI -- OpenAI-to-Google AI API Translation
|
||||
POST {{proxy-host}}/proxy/google-ai/v1/chat/completions
|
||||
Authorization: Bearer {{proxy-key}}
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"model": "gpt-4",
|
||||
"max_tokens": 42,
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Hi what is the name of the fourth president of the united states?"
|
||||
}
|
||||
]
|
||||
}
|
||||
@@ -0,0 +1,102 @@
|
||||
import Database from "better-sqlite3";
|
||||
import { v4 as uuidv4 } from "uuid";
|
||||
import { config } from "../src/config";
|
||||
|
||||
function generateRandomIP() {
|
||||
return (
|
||||
Math.floor(Math.random() * 255) +
|
||||
"." +
|
||||
Math.floor(Math.random() * 255) +
|
||||
"." +
|
||||
Math.floor(Math.random() * 255) +
|
||||
"." +
|
||||
Math.floor(Math.random() * 255)
|
||||
);
|
||||
}
|
||||
|
||||
function generateRandomDate() {
|
||||
const end = new Date();
|
||||
const start = new Date(end);
|
||||
start.setDate(end.getDate() - 90);
|
||||
const randomDate = new Date(
|
||||
start.getTime() + Math.random() * (end.getTime() - start.getTime())
|
||||
);
|
||||
return randomDate.toISOString();
|
||||
}
|
||||
|
||||
function generateMockSHA256() {
|
||||
const characters = 'abcdef0123456789';
|
||||
let hash = '';
|
||||
|
||||
for (let i = 0; i < 64; i++) {
|
||||
const randomIndex = Math.floor(Math.random() * characters.length);
|
||||
hash += characters[randomIndex];
|
||||
}
|
||||
|
||||
return hash;
|
||||
}
|
||||
|
||||
function getRandomModelFamily() {
|
||||
const modelFamilies = [
|
||||
"turbo",
|
||||
"gpt4",
|
||||
"gpt4-32k",
|
||||
"gpt4-turbo",
|
||||
"claude",
|
||||
"claude-opus",
|
||||
"gemini-pro",
|
||||
"mistral-tiny",
|
||||
"mistral-small",
|
||||
"mistral-medium",
|
||||
"mistral-large",
|
||||
"aws-claude",
|
||||
"aws-claude-opus",
|
||||
"gcp-claude",
|
||||
"gcp-claude-opus",
|
||||
"azure-turbo",
|
||||
"azure-gpt4",
|
||||
"azure-gpt4-32k",
|
||||
"azure-gpt4-turbo",
|
||||
"dall-e",
|
||||
"azure-dall-e",
|
||||
];
|
||||
return modelFamilies[Math.floor(Math.random() * modelFamilies.length)];
|
||||
}
|
||||
|
||||
(async () => {
|
||||
const db = new Database(config.sqliteDataPath);
|
||||
const numRows = 100;
|
||||
const insertStatement = db.prepare(`
|
||||
INSERT INTO events (type, ip, date, model, family, hashes, userToken, inputTokens, outputTokens)
|
||||
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)
|
||||
`);
|
||||
|
||||
const users = Array.from({ length: 10 }, () => uuidv4());
|
||||
function getRandomUser() {
|
||||
return users[Math.floor(Math.random() * users.length)];
|
||||
}
|
||||
|
||||
const transaction = db.transaction(() => {
|
||||
for (let i = 0; i < numRows; i++) {
|
||||
insertStatement.run(
|
||||
"chat_completion",
|
||||
generateRandomIP(),
|
||||
generateRandomDate(),
|
||||
getRandomModelFamily() + "-" + Math.floor(Math.random() * 100),
|
||||
getRandomModelFamily(),
|
||||
Array.from(
|
||||
{ length: Math.floor(Math.random() * 10) },
|
||||
generateMockSHA256
|
||||
).join(","),
|
||||
getRandomUser(),
|
||||
Math.floor(Math.random() * 500),
|
||||
Math.floor(Math.random() * 6000)
|
||||
);
|
||||
}
|
||||
});
|
||||
|
||||
transaction();
|
||||
|
||||
console.log(`Inserted ${numRows} rows into the events table.`);
|
||||
db.close();
|
||||
})();
|
||||
@@ -0,0 +1,118 @@
|
||||
// uses the aws sdk to sign a request, then uses axios to send it to the bedrock REST API manually
|
||||
import axios from "axios";
|
||||
import { Sha256 } from "@aws-crypto/sha256-js";
|
||||
import { SignatureV4 } from "@smithy/signature-v4";
|
||||
import { HttpRequest } from "@smithy/protocol-http";
|
||||
|
||||
const AWS_ACCESS_KEY_ID = process.env.AWS_ACCESS_KEY_ID!;
|
||||
const AWS_SECRET_ACCESS_KEY = process.env.AWS_SECRET_ACCESS_KEY!;
|
||||
|
||||
// Copied from amazon bedrock docs
|
||||
|
||||
// List models
|
||||
// ListFoundationModels
|
||||
// Service: Amazon Bedrock
|
||||
// List of Bedrock foundation models that you can use. For more information, see Foundation models in the
|
||||
// Bedrock User Guide.
|
||||
// Request Syntax
|
||||
// GET /foundation-models?
|
||||
// byCustomizationType=byCustomizationType&byInferenceType=byInferenceType&byOutputModality=byOutputModality&byProvider=byProvider
|
||||
// HTTP/1.1
|
||||
// URI Request Parameters
|
||||
// The request uses the following URI parameters.
|
||||
// byCustomizationType (p. 38)
|
||||
// List by customization type.
|
||||
// Valid Values: FINE_TUNING
|
||||
// byInferenceType (p. 38)
|
||||
// List by inference type.
|
||||
// Valid Values: ON_DEMAND | PROVISIONED
|
||||
// byOutputModality (p. 38)
|
||||
// List by output modality type.
|
||||
// Valid Values: TEXT | IMAGE | EMBEDDING
|
||||
// byProvider (p. 38)
|
||||
// A Bedrock model provider.
|
||||
// Pattern: ^[a-z0-9-]{1,63}$
|
||||
// Request Body
|
||||
// The request does not have a request body
|
||||
|
||||
// Run inference on a text model
|
||||
// Send an invoke request to run inference on a Titan Text G1 - Express model. We set the accept
|
||||
// parameter to accept any content type in the response.
|
||||
// POST https://bedrock.us-east-1.amazonaws.com/model/amazon.titan-text-express-v1/invoke
|
||||
// -H accept: */*
|
||||
// -H content-type: application/json
|
||||
// Payload
|
||||
// {"inputText": "Hello world"}
|
||||
// Example response
|
||||
// Response for the above request.
|
||||
// -H content-type: application/json
|
||||
// Payload
|
||||
// <the model response>
|
||||
|
||||
const AMZ_REGION = "us-east-1";
|
||||
const AMZ_HOST = "invoke-bedrock.us-east-1.amazonaws.com";
|
||||
|
||||
async function listModels() {
|
||||
const httpRequest = new HttpRequest({
|
||||
method: "GET",
|
||||
protocol: "https:",
|
||||
hostname: AMZ_HOST,
|
||||
path: "/foundation-models",
|
||||
headers: { ["Host"]: AMZ_HOST },
|
||||
});
|
||||
|
||||
const signedRequest = await signRequest(httpRequest);
|
||||
const response = await axios.get(
|
||||
`https://${signedRequest.hostname}${signedRequest.path}`,
|
||||
{ headers: signedRequest.headers }
|
||||
);
|
||||
console.log(response.data);
|
||||
}
|
||||
|
||||
async function invokeModel() {
|
||||
const model = "anthropic.claude-v1";
|
||||
const httpRequest = new HttpRequest({
|
||||
method: "POST",
|
||||
protocol: "https:",
|
||||
hostname: AMZ_HOST,
|
||||
path: `/model/${model}/invoke`,
|
||||
headers: {
|
||||
["Host"]: AMZ_HOST,
|
||||
["accept"]: "*/*",
|
||||
["content-type"]: "application/json",
|
||||
},
|
||||
body: JSON.stringify({
|
||||
temperature: 0.5,
|
||||
prompt: "\n\nHuman:Hello world\n\nAssistant:",
|
||||
max_tokens_to_sample: 10,
|
||||
}),
|
||||
});
|
||||
console.log("httpRequest", httpRequest);
|
||||
|
||||
const signedRequest = await signRequest(httpRequest);
|
||||
const response = await axios.post(
|
||||
`https://${signedRequest.hostname}${signedRequest.path}`,
|
||||
signedRequest.body,
|
||||
{ headers: signedRequest.headers }
|
||||
);
|
||||
console.log(response.status);
|
||||
console.log(response.headers);
|
||||
console.log(response.data);
|
||||
console.log("full url", response.request.res.responseUrl);
|
||||
}
|
||||
|
||||
async function signRequest(request: HttpRequest) {
|
||||
const signer = new SignatureV4({
|
||||
sha256: Sha256,
|
||||
credentials: {
|
||||
accessKeyId: AWS_ACCESS_KEY_ID,
|
||||
secretAccessKey: AWS_SECRET_ACCESS_KEY,
|
||||
},
|
||||
region: AMZ_REGION,
|
||||
service: "bedrock",
|
||||
});
|
||||
return await signer.sign(request, { signingDate: new Date() });
|
||||
}
|
||||
|
||||
// listModels();
|
||||
// invokeModel();
|
||||
@@ -0,0 +1,45 @@
|
||||
const axios = require("axios");
|
||||
|
||||
const concurrentRequests = 75;
|
||||
const headers = {
|
||||
Authorization: "Bearer test",
|
||||
"Content-Type": "application/json",
|
||||
};
|
||||
|
||||
const payload = {
|
||||
model: "gpt-4",
|
||||
max_tokens: 1,
|
||||
stream: false,
|
||||
messages: [{ role: "user", content: "Hi" }],
|
||||
};
|
||||
|
||||
const makeRequest = async (i) => {
|
||||
try {
|
||||
const response = await axios.post(
|
||||
"http://localhost:7860/proxy/google-ai/v1/chat/completions",
|
||||
payload,
|
||||
{ headers }
|
||||
);
|
||||
console.log(
|
||||
`Req ${i} finished with status code ${response.status} and response:`,
|
||||
response.data
|
||||
);
|
||||
} catch (error) {
|
||||
const msg = error.response
|
||||
console.error(`Error in req ${i}:`, error.message, msg || "");
|
||||
}
|
||||
};
|
||||
|
||||
const executeRequestsConcurrently = () => {
|
||||
const promises = [];
|
||||
for (let i = 1; i <= concurrentRequests; i++) {
|
||||
console.log(`Starting request ${i}`);
|
||||
promises.push(makeRequest(i));
|
||||
}
|
||||
|
||||
Promise.all(promises).then(() => {
|
||||
console.log("All requests finished");
|
||||
});
|
||||
};
|
||||
|
||||
executeRequestsConcurrently();
|
||||
@@ -0,0 +1,53 @@
|
||||
const axios = require("axios");
|
||||
|
||||
function randomInteger(max) {
|
||||
return Math.floor(Math.random() * max + 1);
|
||||
}
|
||||
|
||||
async function testQueue() {
|
||||
const requests = Array(10).fill(undefined).map(async function() {
|
||||
const maxTokens = randomInteger(2000);
|
||||
|
||||
const headers = {
|
||||
"Authorization": "Bearer test",
|
||||
"Content-Type": "application/json",
|
||||
"X-Forwarded-For": `${randomInteger(255)}.${randomInteger(255)}.${randomInteger(255)}.${randomInteger(255)}`,
|
||||
};
|
||||
|
||||
const payload = {
|
||||
model: "gpt-4o-mini-2024-07-18",
|
||||
max_tokens: 20 + maxTokens,
|
||||
stream: false,
|
||||
messages: [{role: "user", content: "You are being benchmarked regarding your reliability at outputting exact, machine-comprehensible data. Output the sentence \"The quick brown fox jumps over the lazy dog.\" Do not precede it with quotemarks or any form of preamble, and do not output anything after the sentence."}],
|
||||
temperature: 0,
|
||||
};
|
||||
|
||||
try {
|
||||
const response = await axios.post(
|
||||
"http://localhost:7860/proxy/openai/v1/chat/completions",
|
||||
payload,
|
||||
{ headers }
|
||||
);
|
||||
|
||||
if (response.status !== 200) {
|
||||
console.error(`Request {$maxTokens} finished with status code ${response.status} and response`, response.data);
|
||||
return;
|
||||
}
|
||||
|
||||
const content = response.data.choices[0].message.content;
|
||||
|
||||
console.log(
|
||||
`Request ${maxTokens} `,
|
||||
content === "The quick brown fox jumps over the lazy dog." ? "OK" : `mangled: ${content}`
|
||||
);
|
||||
} catch (error) {
|
||||
const msg = error.response;
|
||||
console.error(`Error in req ${maxTokens}:`, error.message, msg || "");
|
||||
}
|
||||
});
|
||||
|
||||
await Promise.all(requests);
|
||||
console.log("All requests finished");
|
||||
}
|
||||
|
||||
testQueue();
|
||||
@@ -0,0 +1,49 @@
|
||||
import { Router } from "express";
|
||||
import { z } from "zod";
|
||||
import { encodeCursor, decodeCursor } from "../../shared/utils";
|
||||
import { eventsRepo } from "../../shared/database/repos/event";
|
||||
|
||||
const router = Router();
|
||||
|
||||
/**
|
||||
* Returns events for the given user token.
|
||||
* GET /admin/events/:token
|
||||
* @query first - The number of events to return.
|
||||
* @query after - The cursor to start returning events from (exclusive).
|
||||
*/
|
||||
router.get("/:token", (req, res) => {
|
||||
const schema = z.object({
|
||||
token: z.string(),
|
||||
first: z.coerce.number().int().positive().max(200).default(25),
|
||||
after: z
|
||||
.string()
|
||||
.optional()
|
||||
.transform((v) => {
|
||||
try {
|
||||
return decodeCursor(v);
|
||||
} catch {
|
||||
return null;
|
||||
}
|
||||
})
|
||||
.nullable(),
|
||||
sort: z.string().optional(),
|
||||
});
|
||||
const args = schema.safeParse({ ...req.params, ...req.query });
|
||||
if (!args.success) {
|
||||
return res.status(400).json({ error: args.error });
|
||||
}
|
||||
|
||||
const data = eventsRepo
|
||||
.getUserEvents(args.data.token, {
|
||||
limit: args.data.first,
|
||||
cursor: args.data.after,
|
||||
})
|
||||
.map((e) => ({ node: e, cursor: encodeCursor(e.date) }));
|
||||
|
||||
res.json({
|
||||
data,
|
||||
endCursor: data[data.length - 1]?.cursor,
|
||||
});
|
||||
});
|
||||
|
||||
export { router as eventsApiRouter };
|
||||
@@ -0,0 +1,117 @@
|
||||
import { Router } from "express";
|
||||
import { z } from "zod";
|
||||
import * as userStore from "../../shared/users/user-store";
|
||||
import { parseSort, sortBy } from "../../shared/utils";
|
||||
import { UserPartialSchema, UserSchema } from "../../shared/users/schema";
|
||||
|
||||
const router = Router();
|
||||
|
||||
/**
|
||||
* Returns a list of all users, sorted by prompt count and then last used time.
|
||||
* GET /admin/users
|
||||
*/
|
||||
router.get("/", (req, res) => {
|
||||
const sort = parseSort(req.query.sort) || ["promptCount", "lastUsedAt"];
|
||||
const users = userStore.getUsers().sort(sortBy(sort, false));
|
||||
res.json({ users, count: users.length });
|
||||
});
|
||||
|
||||
/**
|
||||
* Returns the user with the given token.
|
||||
* GET /admin/users/:token
|
||||
*/
|
||||
router.get("/:token", (req, res) => {
|
||||
const user = userStore.getUser(req.params.token);
|
||||
if (!user) {
|
||||
return res.status(404).json({ error: "Not found" });
|
||||
}
|
||||
res.json(user);
|
||||
});
|
||||
|
||||
/**
|
||||
* Creates a new user.
|
||||
* Optionally accepts a JSON body containing `type`, and for temporary-type
|
||||
* users, `tokenLimits` and `expiresAt` fields.
|
||||
* Returns the created user's token.
|
||||
* POST /admin/users
|
||||
*/
|
||||
router.post("/", (req, res) => {
|
||||
const body = req.body;
|
||||
|
||||
const base = z.object({
|
||||
type: UserSchema.shape.type.exclude(["temporary"]).default("normal"),
|
||||
});
|
||||
const tempUser = base
|
||||
.extend({
|
||||
type: z.literal("temporary"),
|
||||
expiresAt: UserSchema.shape.expiresAt,
|
||||
tokenLimits: UserSchema.shape.tokenLimits,
|
||||
})
|
||||
.required();
|
||||
|
||||
const schema = z.union([base, tempUser]);
|
||||
const result = schema.safeParse(body);
|
||||
if (!result.success) {
|
||||
return res.status(400).json({ error: result.error });
|
||||
}
|
||||
|
||||
const token = userStore.createUser({ ...result.data });
|
||||
res.json({ token });
|
||||
});
|
||||
|
||||
/**
|
||||
* Updates the user with the given token, creating them if they don't exist.
|
||||
* Accepts a JSON body containing at least one field on the User type.
|
||||
* Returns the upserted user.
|
||||
* PUT /admin/users/:token
|
||||
*/
|
||||
router.put("/:token", (req, res) => {
|
||||
const result = UserPartialSchema.safeParse({
|
||||
...req.body,
|
||||
token: req.params.token,
|
||||
});
|
||||
if (!result.success) {
|
||||
return res.status(400).json({ error: result.error });
|
||||
}
|
||||
userStore.upsertUser(result.data);
|
||||
res.json(userStore.getUser(req.params.token));
|
||||
});
|
||||
|
||||
/**
|
||||
* Bulk-upserts users given a list of User updates.
|
||||
* Accepts a JSON body with the field `users` containing an array of updates.
|
||||
* Returns an object containing the upserted users and the number of upserts.
|
||||
* PUT /admin/users
|
||||
*/
|
||||
router.put("/", (req, res) => {
|
||||
const result = z.array(UserPartialSchema).safeParse(req.body.users);
|
||||
if (!result.success) {
|
||||
return res.status(400).json({ error: result.error });
|
||||
}
|
||||
const upserts = result.data.map((user) => userStore.upsertUser(user));
|
||||
res.json({ upserted_users: upserts, count: upserts.length });
|
||||
});
|
||||
|
||||
/**
|
||||
* Disables the user with the given token. Optionally accepts a `disabledReason`
|
||||
* query parameter.
|
||||
* Returns the disabled user.
|
||||
* DELETE /admin/users/:token
|
||||
*/
|
||||
router.delete("/:token", (req, res) => {
|
||||
const user = userStore.getUser(req.params.token);
|
||||
const disabledReason = z
|
||||
.string()
|
||||
.optional()
|
||||
.safeParse(req.query.disabledReason);
|
||||
if (!disabledReason.success) {
|
||||
return res.status(400).json({ error: disabledReason.error });
|
||||
}
|
||||
if (!user) {
|
||||
return res.status(404).json({ error: "Not found" });
|
||||
}
|
||||
userStore.disableUser(req.params.token, disabledReason.data);
|
||||
res.json(userStore.getUser(req.params.token));
|
||||
});
|
||||
|
||||
export { router as usersApiRouter };
|
||||
@@ -0,0 +1,54 @@
|
||||
import { Request, Response, RequestHandler } from "express";
|
||||
import { config } from "../config";
|
||||
|
||||
const ADMIN_KEY = config.adminKey;
|
||||
const failedAttempts = new Map<string, number>();
|
||||
|
||||
type AuthorizeParams = { via: "cookie" | "header" };
|
||||
|
||||
export const authorize: ({ via }: AuthorizeParams) => RequestHandler =
|
||||
({ via }) =>
|
||||
(req, res, next) => {
|
||||
const bearerToken = req.headers.authorization?.slice("Bearer ".length);
|
||||
const cookieToken = req.session.adminToken;
|
||||
const token = via === "cookie" ? cookieToken : bearerToken;
|
||||
const attempts = failedAttempts.get(req.ip) ?? 0;
|
||||
|
||||
if (!ADMIN_KEY) {
|
||||
req.log.warn(
|
||||
{ ip: req.ip },
|
||||
`Blocked admin request because no admin key is configured`
|
||||
);
|
||||
return res.status(401).json({ error: "Unauthorized" });
|
||||
}
|
||||
|
||||
if (attempts > 5) {
|
||||
req.log.warn(
|
||||
{ ip: req.ip, token: bearerToken },
|
||||
`Blocked admin request due to too many failed attempts`
|
||||
);
|
||||
return res.status(401).json({ error: "Too many attempts" });
|
||||
}
|
||||
|
||||
if (token && token === ADMIN_KEY) {
|
||||
return next();
|
||||
}
|
||||
|
||||
req.log.warn(
|
||||
{ ip: req.ip, attempts, invalidToken: String(token) },
|
||||
`Attempted admin request with invalid token`
|
||||
);
|
||||
return handleFailedLogin(req, res);
|
||||
};
|
||||
|
||||
function handleFailedLogin(req: Request, res: Response) {
|
||||
const attempts = failedAttempts.get(req.ip) ?? 0;
|
||||
const newAttempts = attempts + 1;
|
||||
failedAttempts.set(req.ip, newAttempts);
|
||||
if (req.accepts("json", "html") === "json") {
|
||||
return res.status(401).json({ error: "Unauthorized" });
|
||||
}
|
||||
delete req.session.adminToken;
|
||||
req.session.flash = { type: "error", message: `Invalid admin key.` };
|
||||
return res.redirect("/admin/login");
|
||||
}
|
||||
@@ -0,0 +1,26 @@
|
||||
import { Router } from "express";
|
||||
|
||||
const loginRouter = Router();
|
||||
|
||||
loginRouter.get("/login", (_req, res) => {
|
||||
res.render("admin_login");
|
||||
});
|
||||
|
||||
loginRouter.post("/login", (req, res) => {
|
||||
req.session.adminToken = req.body.token;
|
||||
res.redirect("/admin");
|
||||
});
|
||||
|
||||
loginRouter.get("/logout", (req, res) => {
|
||||
delete req.session.adminToken;
|
||||
res.redirect("/admin/login");
|
||||
});
|
||||
|
||||
loginRouter.get("/", (req, res) => {
|
||||
if (req.session.adminToken) {
|
||||
return res.redirect("/admin/manage");
|
||||
}
|
||||
res.redirect("/admin/login");
|
||||
});
|
||||
|
||||
export { loginRouter };
|
||||
@@ -0,0 +1,114 @@
|
||||
import express, { Router } from "express";
|
||||
import { createWhitelistMiddleware } from "../shared/cidr";
|
||||
import { HttpError } from "../shared/errors";
|
||||
import { injectCsrfToken, checkCsrfToken } from "../shared/inject-csrf";
|
||||
import { injectLocals } from "../shared/inject-locals";
|
||||
import { withSession } from "../shared/with-session";
|
||||
import { config } from "../config";
|
||||
import { renderPage } from "../info-page";
|
||||
import { buildInfo } from "../service-info";
|
||||
import { authorize } from "./auth";
|
||||
import { loginRouter } from "./login";
|
||||
import { eventsApiRouter } from "./api/events";
|
||||
import { usersApiRouter } from "./api/users";
|
||||
import { usersWebRouter as webRouter } from "./web/manage";
|
||||
import { logger } from "../logger";
|
||||
import { keyPool } from "../shared/key-management";
|
||||
|
||||
const adminRouter = Router();
|
||||
|
||||
const whitelist = createWhitelistMiddleware(
|
||||
"ADMIN_WHITELIST",
|
||||
config.adminWhitelist
|
||||
);
|
||||
|
||||
if (!whitelist.ranges.length && config.adminKey?.length) {
|
||||
logger.error("ADMIN_WHITELIST is empty. No admin requests will be allowed. Set 0.0.0.0/0 to allow all.");
|
||||
}
|
||||
|
||||
adminRouter.use(whitelist);
|
||||
adminRouter.use(
|
||||
express.json({ limit: "20mb" }),
|
||||
express.urlencoded({ extended: true, limit: "20mb" })
|
||||
);
|
||||
adminRouter.use(withSession);
|
||||
adminRouter.use(injectCsrfToken);
|
||||
|
||||
adminRouter.use("/users", authorize({ via: "header" }), usersApiRouter);
|
||||
adminRouter.use("/events", authorize({ via: "header" }), eventsApiRouter);
|
||||
|
||||
// Special endpoint to validate organization verification status for all OpenAI keys
|
||||
// This checks both gpt-image-1 and o3 streaming access which require verified organizations
|
||||
adminRouter.post("/validate-gpt-image-keys", authorize({ via: "header" }), async (req, res) => {
|
||||
try {
|
||||
logger.info("Manual validation of organization verification status initiated");
|
||||
|
||||
// Use the specialized validation function that tests each key's organization verification
|
||||
// status using o3 streaming and waits for the results
|
||||
const results = await keyPool.validateGptImageAccess();
|
||||
|
||||
logger.info({
|
||||
total: results.total,
|
||||
verified: results.verified.length,
|
||||
removed: results.removed.length,
|
||||
errors: results.errors.length
|
||||
}, "Manual organization verification check completed");
|
||||
|
||||
return res.json({
|
||||
success: true,
|
||||
message: "Organization verification check completed",
|
||||
results: {
|
||||
total: results.total,
|
||||
verified: results.verified.length,
|
||||
removed: results.removed.length,
|
||||
errors: results.errors.length,
|
||||
// Only include hashes, not full keys
|
||||
verified_keys: results.verified,
|
||||
removed_keys: results.removed,
|
||||
error_details: results.errors
|
||||
}
|
||||
});
|
||||
} catch (error) {
|
||||
logger.error({ error }, "Error validating organization verification status for OpenAI keys");
|
||||
return res.status(500).json({ error: "Failed to validate keys", details: error.message });
|
||||
}
|
||||
});
|
||||
|
||||
adminRouter.use(checkCsrfToken);
|
||||
adminRouter.use(injectLocals);
|
||||
adminRouter.use("/", loginRouter);
|
||||
adminRouter.use("/manage", authorize({ via: "cookie" }), webRouter);
|
||||
adminRouter.use("/service-info", authorize({ via: "cookie" }), (req, res) => {
|
||||
return res.send(
|
||||
renderPage(buildInfo(req.protocol + "://" + req.get("host"), true))
|
||||
);
|
||||
});
|
||||
|
||||
adminRouter.use(
|
||||
(
|
||||
err: Error,
|
||||
req: express.Request,
|
||||
res: express.Response,
|
||||
_next: express.NextFunction
|
||||
) => {
|
||||
const data: any = { message: err.message, stack: err.stack };
|
||||
if (err instanceof HttpError) {
|
||||
data.status = err.status;
|
||||
res.status(err.status);
|
||||
if (req.accepts(["html", "json"]) === "json") {
|
||||
return res.json({ error: data });
|
||||
}
|
||||
return res.render("admin_error", data);
|
||||
} else if (err.name === "ForbiddenError") {
|
||||
data.status = 403;
|
||||
if (err.message === "invalid csrf token") {
|
||||
data.message =
|
||||
"Invalid CSRF token; try refreshing the previous page before submitting again.";
|
||||
}
|
||||
return res.status(403).render("admin_error", { ...data, flash: null });
|
||||
}
|
||||
res.status(500).json({ error: data });
|
||||
}
|
||||
);
|
||||
|
||||
export { adminRouter };
|
||||
@@ -0,0 +1,632 @@
|
||||
import { Router } from "express";
|
||||
import ipaddr from "ipaddr.js";
|
||||
import multer from "multer";
|
||||
import { z } from "zod";
|
||||
import { config } from "../../config";
|
||||
import { HttpError } from "../../shared/errors";
|
||||
import * as userStore from "../../shared/users/user-store";
|
||||
import { parseSort, sortBy, paginate } from "../../shared/utils";
|
||||
import { keyPool } from "../../shared/key-management";
|
||||
import { LLMService, MODEL_FAMILIES } from "../../shared/models";
|
||||
import { getTokenCostUsd, prettyTokens } from "../../shared/stats";
|
||||
import {
|
||||
User,
|
||||
UserPartialSchema,
|
||||
UserSchema,
|
||||
UserTokenCounts,
|
||||
} from "../../shared/users/schema";
|
||||
import { getLastNImages } from "../../shared/file-storage/image-history";
|
||||
import { blacklists, parseCidrs, whitelists } from "../../shared/cidr";
|
||||
import { invalidatePowChallenges } from "../../user/web/pow-captcha";
|
||||
|
||||
const router = Router();
|
||||
|
||||
const upload = multer({
|
||||
storage: multer.memoryStorage(),
|
||||
fileFilter: (_req, file, cb) => {
|
||||
if (file.mimetype !== "application/json") {
|
||||
cb(new Error("Invalid file type"));
|
||||
} else {
|
||||
cb(null, true);
|
||||
}
|
||||
},
|
||||
});
|
||||
|
||||
router.get("/create-user", (req, res) => {
|
||||
const recentUsers = userStore
|
||||
.getUsers()
|
||||
.sort(sortBy(["createdAt"], false))
|
||||
.slice(0, 5);
|
||||
res.render("admin_create-user", {
|
||||
recentUsers,
|
||||
newToken: !!req.query.created,
|
||||
});
|
||||
});
|
||||
|
||||
router.get("/anti-abuse", (_req, res) => {
|
||||
const wl = [...whitelists.entries()];
|
||||
const bl = [...blacklists.entries()];
|
||||
|
||||
res.render("admin_anti-abuse", {
|
||||
captchaMode: config.captchaMode,
|
||||
difficulty: config.powDifficultyLevel,
|
||||
whitelists: wl.map((w) => ({
|
||||
name: w[0],
|
||||
mode: "whitelist",
|
||||
ranges: w[1].ranges,
|
||||
})),
|
||||
blacklists: bl.map((b) => ({
|
||||
name: b[0],
|
||||
mode: "blacklist",
|
||||
ranges: b[1].ranges,
|
||||
})),
|
||||
});
|
||||
});
|
||||
|
||||
router.post("/cidr", (req, res) => {
|
||||
const body = req.body;
|
||||
const valid = z
|
||||
.object({
|
||||
action: z.enum(["add", "remove"]),
|
||||
mode: z.enum(["whitelist", "blacklist"]),
|
||||
name: z.string().min(1),
|
||||
mask: z.string().min(1),
|
||||
})
|
||||
.safeParse(body);
|
||||
|
||||
if (!valid.success) {
|
||||
throw new HttpError(
|
||||
400,
|
||||
valid.error.issues.flatMap((issue) => issue.message).join(", ")
|
||||
);
|
||||
}
|
||||
|
||||
const { mode, name, mask } = valid.data;
|
||||
const list = (mode === "whitelist" ? whitelists : blacklists).get(name);
|
||||
if (!list) {
|
||||
throw new HttpError(404, "List not found");
|
||||
}
|
||||
if (valid.data.action === "remove") {
|
||||
const newRanges = new Set(list.ranges);
|
||||
newRanges.delete(mask);
|
||||
list.updateRanges([...newRanges]);
|
||||
req.session.flash = {
|
||||
type: "success",
|
||||
message: `${mode} ${name} updated`,
|
||||
};
|
||||
return res.redirect("/admin/manage/anti-abuse");
|
||||
} else if (valid.data.action === "add") {
|
||||
const result = parseCidrs(mask);
|
||||
if (result.length === 0) {
|
||||
throw new HttpError(400, "Invalid CIDR mask");
|
||||
}
|
||||
|
||||
const newRanges = new Set([...list.ranges, mask]);
|
||||
list.updateRanges([...newRanges]);
|
||||
req.session.flash = {
|
||||
type: "success",
|
||||
message: `${mode} ${name} updated`,
|
||||
};
|
||||
return res.redirect("/admin/manage/anti-abuse");
|
||||
}
|
||||
});
|
||||
|
||||
router.post("/create-user", (req, res) => {
|
||||
const body = req.body;
|
||||
|
||||
const base = z.object({ type: UserSchema.shape.type.default("normal") });
|
||||
const tempUser = base
|
||||
.extend({
|
||||
temporaryUserDuration: z.coerce
|
||||
.number()
|
||||
.int()
|
||||
.min(1)
|
||||
.max(10080 * 4),
|
||||
})
|
||||
.merge(
|
||||
MODEL_FAMILIES.reduce((schema, model) => {
|
||||
return schema.extend({
|
||||
[`temporaryUserQuota_${model}`]: z.coerce.number().int().min(0),
|
||||
});
|
||||
}, z.object({}))
|
||||
)
|
||||
.transform((data: any) => {
|
||||
const expiresAt = Date.now() + data.temporaryUserDuration * 60 * 1000;
|
||||
const tokenLimits = MODEL_FAMILIES.reduce((limits, modelFamily) => {
|
||||
const quotaValue = data[`temporaryUserQuota_${modelFamily}`];
|
||||
limits[modelFamily] = typeof quotaValue === 'number' ? quotaValue : 0;
|
||||
return limits;
|
||||
}, {} as any);
|
||||
return { ...data, expiresAt, tokenLimits };
|
||||
});
|
||||
|
||||
const createSchema = body.type === "temporary" ? tempUser : base;
|
||||
const result = createSchema.safeParse(body);
|
||||
if (!result.success) {
|
||||
throw new HttpError(
|
||||
400,
|
||||
result.error.issues.flatMap((issue) => issue.message).join(", ")
|
||||
);
|
||||
}
|
||||
|
||||
userStore.createUser({ ...result.data });
|
||||
return res.redirect(`/admin/manage/create-user?created=true`);
|
||||
});
|
||||
|
||||
router.get("/view-user/:token", (req, res) => {
|
||||
const user = userStore.getUser(req.params.token);
|
||||
if (!user) throw new HttpError(404, "User not found");
|
||||
res.render("admin_view-user", { user });
|
||||
});
|
||||
|
||||
router.get("/list-users", (req, res) => {
|
||||
const sort = parseSort(req.query.sort) || ["sumTokens", "createdAt"];
|
||||
const requestedPageSize =
|
||||
Number(req.query.perPage) || Number(req.cookies.perPage) || 20;
|
||||
const perPage = Math.max(1, Math.min(1000, requestedPageSize));
|
||||
const users = userStore
|
||||
.getUsers()
|
||||
.map((user) => {
|
||||
const sums = getSumsForUser(user);
|
||||
return { ...user, ...sums };
|
||||
})
|
||||
.sort(sortBy(sort, false));
|
||||
|
||||
const page = Number(req.query.page) || 1;
|
||||
const { items, ...pagination } = paginate(users, page, perPage);
|
||||
|
||||
return res.render("admin_list-users", {
|
||||
sort: sort.join(","),
|
||||
users: items,
|
||||
...pagination,
|
||||
});
|
||||
});
|
||||
|
||||
router.get("/import-users", (_req, res) => {
|
||||
res.render("admin_import-users");
|
||||
});
|
||||
|
||||
router.post("/import-users", upload.single("users"), (req, res) => {
|
||||
if (!req.file) throw new HttpError(400, "No file uploaded");
|
||||
|
||||
const data = JSON.parse(req.file.buffer.toString());
|
||||
|
||||
// Transform old token count format to new format
|
||||
const transformedUsers = data.users.map((user: any) => {
|
||||
if (user.tokenCounts) {
|
||||
const transformedTokenCounts: any = {};
|
||||
for (const [family, value] of Object.entries(user.tokenCounts)) {
|
||||
if (typeof value === 'number') {
|
||||
// Old format: just a number (legacy_total)
|
||||
transformedTokenCounts[family] = {
|
||||
input: 0,
|
||||
output: 0,
|
||||
legacy_total: value
|
||||
};
|
||||
} else if (typeof value === 'object' && value !== null) {
|
||||
// New format or partially new format
|
||||
const transformedCounts: { input: number; output: number; legacy_total?: number } = {
|
||||
input: (value as any).input || 0,
|
||||
output: (value as any).output || 0
|
||||
};
|
||||
if ((value as any).legacy_total !== undefined) {
|
||||
transformedCounts.legacy_total = (value as any).legacy_total;
|
||||
}
|
||||
transformedTokenCounts[family] = transformedCounts;
|
||||
}
|
||||
}
|
||||
user.tokenCounts = transformedTokenCounts;
|
||||
}
|
||||
|
||||
// Handle tokenLimits - should be flat numbers
|
||||
if (user.tokenLimits) {
|
||||
const transformedTokenLimits: any = {};
|
||||
for (const [family, value] of Object.entries(user.tokenLimits)) {
|
||||
if (typeof value === 'number') {
|
||||
// Already in correct format
|
||||
transformedTokenLimits[family] = value;
|
||||
} else if (typeof value === 'object' && value !== null) {
|
||||
// Old format with input/output/legacy_total - sum them up
|
||||
const val = value as any;
|
||||
transformedTokenLimits[family] = (val.input ?? 0) + (val.output ?? 0) + (val.legacy_total ?? 0);
|
||||
}
|
||||
}
|
||||
user.tokenLimits = transformedTokenLimits;
|
||||
}
|
||||
|
||||
// Handle tokenRefresh - should be flat numbers
|
||||
if (user.tokenRefresh) {
|
||||
const transformedTokenRefresh: any = {};
|
||||
for (const [family, value] of Object.entries(user.tokenRefresh)) {
|
||||
if (typeof value === 'number') {
|
||||
// Already in correct format
|
||||
transformedTokenRefresh[family] = value;
|
||||
} else if (typeof value === 'object' && value !== null) {
|
||||
// Old format with input/output/legacy_total - sum them up
|
||||
const val = value as any;
|
||||
transformedTokenRefresh[family] = (val.input ?? 0) + (val.output ?? 0) + (val.legacy_total ?? 0);
|
||||
}
|
||||
}
|
||||
user.tokenRefresh = transformedTokenRefresh;
|
||||
}
|
||||
|
||||
return user;
|
||||
});
|
||||
|
||||
const result = z.array(UserPartialSchema).safeParse(transformedUsers);
|
||||
if (!result.success) throw new HttpError(400, result.error.toString());
|
||||
|
||||
const upserts = result.data.map((user) => userStore.upsertUser(user));
|
||||
req.session.flash = {
|
||||
type: "success",
|
||||
message: `${upserts.length} users imported`,
|
||||
};
|
||||
res.redirect("/admin/manage/import-users");
|
||||
});
|
||||
|
||||
router.get("/export-users", (_req, res) => {
|
||||
res.render("admin_export-users");
|
||||
});
|
||||
|
||||
router.get("/export-users.json", (_req, res) => {
|
||||
const users = userStore.getUsers();
|
||||
res.setHeader("Content-Disposition", "attachment; filename=users.json");
|
||||
res.setHeader("Content-Type", "application/json");
|
||||
res.send(JSON.stringify({ users }, null, 2));
|
||||
});
|
||||
|
||||
router.get("/", (_req, res) => {
|
||||
res.render("admin_index");
|
||||
});
|
||||
|
||||
router.post("/edit-user/:token", (req, res) => {
|
||||
const result = UserPartialSchema.safeParse({
|
||||
...req.body,
|
||||
token: req.params.token,
|
||||
});
|
||||
if (!result.success) {
|
||||
throw new HttpError(
|
||||
400,
|
||||
result.error.issues.flatMap((issue) => issue.message).join(", ")
|
||||
);
|
||||
}
|
||||
|
||||
userStore.upsertUser(result.data);
|
||||
return res.status(200).json({ success: true });
|
||||
});
|
||||
|
||||
router.post("/reactivate-user/:token", (req, res) => {
|
||||
const user = userStore.getUser(req.params.token);
|
||||
if (!user) throw new HttpError(404, "User not found");
|
||||
|
||||
userStore.upsertUser({
|
||||
token: user.token,
|
||||
disabledAt: null,
|
||||
disabledReason: null,
|
||||
});
|
||||
return res.sendStatus(204);
|
||||
});
|
||||
|
||||
router.post("/disable-user/:token", (req, res) => {
|
||||
const user = userStore.getUser(req.params.token);
|
||||
if (!user) throw new HttpError(404, "User not found");
|
||||
|
||||
userStore.disableUser(req.params.token, req.body.reason);
|
||||
return res.sendStatus(204);
|
||||
});
|
||||
|
||||
router.post("/refresh-user-quota", (req, res) => {
|
||||
const user = userStore.getUser(req.body.token);
|
||||
if (!user) throw new HttpError(404, "User not found");
|
||||
|
||||
userStore.refreshQuota(user.token);
|
||||
req.session.flash = {
|
||||
type: "success",
|
||||
message: "User's quota was refreshed",
|
||||
};
|
||||
return res.redirect(`/admin/manage/view-user/${user.token}`);
|
||||
});
|
||||
|
||||
router.post("/maintenance", (req, res) => {
|
||||
const action = req.body.action;
|
||||
let flash = { type: "", message: "" };
|
||||
switch (action) {
|
||||
case "recheck": {
|
||||
const checkable: LLMService[] = [
|
||||
"openai",
|
||||
"anthropic",
|
||||
"aws",
|
||||
"gcp",
|
||||
"azure",
|
||||
"google-ai"
|
||||
];
|
||||
checkable.forEach((s) => keyPool.recheck(s));
|
||||
const keyCount = keyPool
|
||||
.list()
|
||||
.filter((k) => checkable.includes(k.service)).length;
|
||||
|
||||
flash.type = "success";
|
||||
flash.message = `Scheduled recheck of ${keyCount} keys.`;
|
||||
break;
|
||||
}
|
||||
case "resetQuotas": {
|
||||
const users = userStore.getUsers();
|
||||
users.forEach((user) => userStore.refreshQuota(user.token));
|
||||
const { claude, gpt4, turbo } = config.tokenQuota;
|
||||
flash.type = "success";
|
||||
flash.message = `All users' token quotas reset to ${turbo} (Turbo), ${gpt4} (GPT-4), ${claude} (Claude).`;
|
||||
break;
|
||||
}
|
||||
case "resetCounts": {
|
||||
const users = userStore.getUsers();
|
||||
users.forEach((user) => userStore.resetUsage(user.token));
|
||||
flash.type = "success";
|
||||
flash.message = `All users' token usage records reset.`;
|
||||
break;
|
||||
}
|
||||
case "downloadImageMetadata": {
|
||||
const data = JSON.stringify(
|
||||
{
|
||||
exportedAt: new Date().toISOString(),
|
||||
generations: getLastNImages(),
|
||||
},
|
||||
null,
|
||||
2
|
||||
);
|
||||
res.setHeader(
|
||||
"Content-Disposition",
|
||||
`attachment; filename=image-metadata-${new Date().toISOString()}.json`
|
||||
);
|
||||
res.setHeader("Content-Type", "application/json");
|
||||
return res.send(data);
|
||||
}
|
||||
case "expireTempTokens": {
|
||||
const users = userStore.getUsers();
|
||||
const temps = users.filter((u) => u.type === "temporary");
|
||||
temps.forEach((user) => {
|
||||
user.expiresAt = Date.now();
|
||||
user.disabledReason = "Admin forced expiration.";
|
||||
userStore.upsertUser(user);
|
||||
});
|
||||
invalidatePowChallenges();
|
||||
flash.type = "success";
|
||||
flash.message = `${temps.length} temporary users marked for expiration.`;
|
||||
break;
|
||||
}
|
||||
case "cleanTempTokens": {
|
||||
const users = userStore.getUsers();
|
||||
const disabledTempUsers = users.filter(
|
||||
(u) => u.type === "temporary" && u.expiresAt && u.expiresAt < Date.now()
|
||||
);
|
||||
disabledTempUsers.forEach((user) => {
|
||||
user.disabledAt = 1; //will be cleaned up by the next cron job
|
||||
userStore.upsertUser(user);
|
||||
});
|
||||
flash.type = "success";
|
||||
flash.message = `${disabledTempUsers.length} disabled temporary users marked for cleanup.`;
|
||||
break;
|
||||
}
|
||||
case "setDifficulty": {
|
||||
const selected = req.body["pow-difficulty"];
|
||||
const valid = ["low", "medium", "high", "extreme"];
|
||||
const isNumber = Number.isInteger(Number(selected));
|
||||
if (!selected || !valid.includes(selected) && !isNumber) {
|
||||
throw new HttpError(400, "Invalid difficulty " + selected);
|
||||
}
|
||||
config.powDifficultyLevel = isNumber ? Number(selected) : selected;
|
||||
invalidatePowChallenges();
|
||||
break;
|
||||
}
|
||||
case "generateTempIpReport": {
|
||||
const tempUsers = userStore
|
||||
.getUsers()
|
||||
.filter((u) => u.type === "temporary");
|
||||
const ipv4RangeMap = new Map<string, Set<string>>();
|
||||
const ipv6RangeMap = new Map<string, Set<string>>();
|
||||
|
||||
tempUsers.forEach((u) => {
|
||||
u.ip.forEach((ip) => {
|
||||
try {
|
||||
const parsed = ipaddr.parse(ip);
|
||||
if (parsed.kind() === "ipv4") {
|
||||
const subnet =
|
||||
parsed.toNormalizedString().split(".").slice(0, 3).join(".") +
|
||||
".0/24";
|
||||
const userSet = ipv4RangeMap.get(subnet) || new Set();
|
||||
userSet.add(u.token);
|
||||
ipv4RangeMap.set(subnet, userSet);
|
||||
} else if (parsed.kind() === "ipv6") {
|
||||
const subnet =
|
||||
parsed.toNormalizedString().split(":").slice(0, 4).join(":") +
|
||||
"::/48";
|
||||
const userSet = ipv6RangeMap.get(subnet) || new Set();
|
||||
userSet.add(u.token);
|
||||
ipv6RangeMap.set(subnet, userSet);
|
||||
}
|
||||
} catch (e) {
|
||||
req.log.warn(
|
||||
{ ip, error: e.message },
|
||||
"Invalid IP address; skipping"
|
||||
);
|
||||
}
|
||||
});
|
||||
});
|
||||
|
||||
const ipv4Ranges = Array.from(ipv4RangeMap.entries())
|
||||
.map(([subnet, userSet]) => ({
|
||||
subnet,
|
||||
distinctTokens: userSet.size,
|
||||
}))
|
||||
.sort((a, b) => b.distinctTokens - a.distinctTokens);
|
||||
|
||||
const ipv6Ranges = Array.from(ipv6RangeMap.entries())
|
||||
.map(([subnet, userSet]) => ({
|
||||
subnet,
|
||||
distinctTokens: userSet.size,
|
||||
}))
|
||||
.sort((a, b) => {
|
||||
if (a.distinctTokens === b.distinctTokens) {
|
||||
return a.subnet.localeCompare(b.subnet);
|
||||
}
|
||||
return b.distinctTokens - a.distinctTokens;
|
||||
});
|
||||
|
||||
const data = JSON.stringify(
|
||||
{
|
||||
exportedAt: new Date().toISOString(),
|
||||
ipv4Ranges,
|
||||
ipv6Ranges,
|
||||
},
|
||||
null,
|
||||
2
|
||||
);
|
||||
|
||||
res.setHeader(
|
||||
"Content-Disposition",
|
||||
`attachment; filename=temp-ip-report-${new Date().toISOString()}.json`
|
||||
);
|
||||
res.setHeader("Content-Type", "application/json");
|
||||
return res.send(data);
|
||||
}
|
||||
default: {
|
||||
throw new HttpError(400, "Invalid action");
|
||||
}
|
||||
}
|
||||
|
||||
req.session.flash = flash;
|
||||
const referer = req.get("referer");
|
||||
|
||||
return res.redirect(referer || "/admin/manage");
|
||||
});
|
||||
|
||||
router.get("/download-stats", (_req, res) => {
|
||||
return res.render("admin_download-stats");
|
||||
});
|
||||
|
||||
router.post("/generate-stats", (req, res) => {
|
||||
const body = req.body;
|
||||
|
||||
const valid = z
|
||||
.object({
|
||||
anon: z.coerce.boolean().optional().default(false),
|
||||
sort: z.string().optional().default("prompts"),
|
||||
maxUsers: z.coerce
|
||||
.number()
|
||||
.int()
|
||||
.min(5)
|
||||
.max(1000)
|
||||
.optional()
|
||||
.default(1000),
|
||||
tableType: z.enum(["code", "markdown"]).optional().default("markdown"),
|
||||
format: z
|
||||
.string()
|
||||
.optional()
|
||||
.default("# Stats\n{{header}}\n{{stats}}\n{{time}}"),
|
||||
})
|
||||
.strict()
|
||||
.safeParse(body);
|
||||
|
||||
if (!valid.success) {
|
||||
throw new HttpError(
|
||||
400,
|
||||
valid.error.issues.flatMap((issue) => issue.message).join(", ")
|
||||
);
|
||||
}
|
||||
|
||||
const { anon, sort, format, maxUsers, tableType } = valid.data;
|
||||
const users = userStore.getUsers();
|
||||
|
||||
let totalTokens = 0;
|
||||
let totalCost = 0;
|
||||
let totalPrompts = 0;
|
||||
let totalIps = 0;
|
||||
|
||||
const lines = users
|
||||
.map((u) => {
|
||||
const sums = getSumsForUser(u);
|
||||
totalTokens += sums.sumTokens;
|
||||
totalCost += sums.sumCost;
|
||||
totalPrompts += u.promptCount;
|
||||
totalIps += u.ip.length;
|
||||
|
||||
const getName = (u: User) => {
|
||||
const id = `...${u.token.slice(-5)}`;
|
||||
const banned = !!u.disabledAt;
|
||||
let nick = anon || !u.nickname ? "Anonymous" : u.nickname;
|
||||
|
||||
if (tableType === "markdown") {
|
||||
nick = banned ? `~~${nick}~~` : nick;
|
||||
return `${nick.slice(0, 18)} | ${id}`;
|
||||
} else {
|
||||
// Strikethrough doesn't work within code blocks
|
||||
const dead = !!u.disabledAt ? "[dead] " : "";
|
||||
nick = `${dead}${nick}`;
|
||||
return `${nick.slice(0, 18).padEnd(18)} ${id}`.padEnd(27);
|
||||
}
|
||||
};
|
||||
|
||||
const user = getName(u);
|
||||
const prompts = `${u.promptCount} proompts`.padEnd(14);
|
||||
const ips = `${u.ip.length} IPs`.padEnd(8);
|
||||
const tokens = `${sums.prettyUsage} tokens`.padEnd(30);
|
||||
const sortField = sort === "prompts" ? u.promptCount : sums.sumTokens;
|
||||
return { user, prompts, ips, tokens, sortField };
|
||||
})
|
||||
.sort((a, b) => b.sortField - a.sortField)
|
||||
.map(({ user, prompts, ips, tokens }, i) => {
|
||||
const pos = tableType === "markdown" ? (i + 1 + ".").padEnd(4) : "";
|
||||
return `${pos}${user} | ${prompts} | ${ips} | ${tokens}`;
|
||||
})
|
||||
.slice(0, maxUsers);
|
||||
|
||||
const strTotalPrompts = `${totalPrompts} proompts`;
|
||||
const strTotalIps = `${totalIps} IPs`;
|
||||
const strTotalTokens = `${prettyTokens(totalTokens)} tokens`;
|
||||
const strTotalCost = `US$${totalCost.toFixed(2)} cost`;
|
||||
const header = `!!!Note ${users.length} users | ${strTotalPrompts} | ${strTotalIps} | ${strTotalTokens} | ${strTotalCost}`;
|
||||
const time = `\n-> *(as of ${new Date().toISOString()})* <-`;
|
||||
|
||||
let table = [];
|
||||
table.push(lines.join("\n"));
|
||||
|
||||
if (valid.data.tableType === "markdown") {
|
||||
table = ["User||Prompts|IPs|Usage", "---|---|---|---|---", ...table];
|
||||
} else {
|
||||
table = ["```text", ...table, "```"];
|
||||
}
|
||||
|
||||
const result = format
|
||||
.replace("{{header}}", header)
|
||||
.replace("{{stats}}", table.join("\n"))
|
||||
.replace("{{time}}", time);
|
||||
|
||||
res.setHeader(
|
||||
"Content-Disposition",
|
||||
`attachment; filename=proxy-stats-${new Date().toISOString()}.md`
|
||||
);
|
||||
res.setHeader("Content-Type", "text/markdown");
|
||||
res.send(result);
|
||||
});
|
||||
|
||||
function getSumsForUser(user: User) {
|
||||
const sums = MODEL_FAMILIES.reduce(
|
||||
(s, model) => {
|
||||
const counts = user.tokenCounts[model] ?? { input: 0, output: 0 };
|
||||
// Ensure inputTokens and outputTokens are numbers, defaulting to 0 if NaN or undefined
|
||||
const inputTokens = Number(counts.input) || 0;
|
||||
const outputTokens = Number(counts.output) || 0;
|
||||
// We could also consider legacy_total here if input and output are 0
|
||||
// For now, sumTokens and sumCost will be based on current input/output.
|
||||
s.sumTokens += inputTokens + outputTokens;
|
||||
s.sumCost += getTokenCostUsd(model, inputTokens, outputTokens);
|
||||
return s;
|
||||
},
|
||||
{ sumTokens: 0, sumCost: 0, prettyUsage: "" }
|
||||
);
|
||||
sums.prettyUsage = `${prettyTokens(sums.sumTokens)} ($${sums.sumCost.toFixed(
|
||||
2
|
||||
)})`;
|
||||
return sums;
|
||||
}
|
||||
|
||||
export { router as usersWebRouter };
|
||||
@@ -0,0 +1,160 @@
|
||||
<%- include("partials/shared_header", { title: "Proof of Work Verification Settings - OAI Reverse Proxy Admin" }) %>
|
||||
<style>
|
||||
details {
|
||||
margin-top: 1em;
|
||||
}
|
||||
details summary {
|
||||
font-weight: bold;
|
||||
cursor: pointer;
|
||||
}
|
||||
details p {
|
||||
margin-left: 1em;
|
||||
}
|
||||
|
||||
#token-manage {
|
||||
display: flex;
|
||||
width: 100%;
|
||||
}
|
||||
#token-manage button {
|
||||
flex-grow: 1;
|
||||
margin: 0 0.5em;
|
||||
}
|
||||
</style>
|
||||
|
||||
<h1>Abuse Mitigation Settings</h1>
|
||||
<div>
|
||||
<h2>Proof-of-Work Verification</h2>
|
||||
<p>
|
||||
The Proof-of-Work difficulty level is used to determine how much work a client must perform to earn a temporary user
|
||||
token. Higher difficulty levels require more work, which can help mitigate abuse by making it more expensive for
|
||||
attackers to generate tokens. However, higher difficulty levels can also make it more difficult for legitimate users
|
||||
to generate tokens. Refer to documentation for guidance.
|
||||
</p>
|
||||
<%if (captchaMode === "none") { %>
|
||||
<p>
|
||||
<strong>PoW verification is not enabled. Set <code>CAPTCHA_MODE=proof_of_work</code> to enable.</strong>
|
||||
</p>
|
||||
<% } else { %>
|
||||
<h3>Difficulty Level</h3>
|
||||
<div>
|
||||
<label for="difficulty">Difficulty Level:</label>
|
||||
<select name="difficulty" id="difficulty" onchange="difficultyChanged(event)">
|
||||
<option value="low">Low</option>
|
||||
<option value="medium">Medium</option>
|
||||
<option value="high">High</option>
|
||||
<option value="extreme">Extreme</option>
|
||||
<option value="custom">Custom</option>
|
||||
</select>
|
||||
<div id="custom-difficulty-container" style="display: none">
|
||||
<label for="customDifficulty">Hashes required (average):</label>
|
||||
<input type="number" id="customDifficulty" value="0" min="1" max="1000000000" />
|
||||
</div>
|
||||
<button onclick='doAction("setDifficulty")'>Update Difficulty</button>
|
||||
</div>
|
||||
<div><span id="currentDifficulty">Current Difficulty: <%= difficulty %></span></div>
|
||||
<% } %>
|
||||
<form id="maintenanceForm" action="/admin/manage/maintenance" method="post">
|
||||
<input id="_csrf" type="hidden" name="_csrf" value="<%= csrfToken %>" />
|
||||
<input id="hiddenAction" type="hidden" name="action" value="" />
|
||||
<input id="hiddenDifficulty" type="hidden" name="pow-difficulty" value="" />
|
||||
</form>
|
||||
<h3>Manage Temporary User Tokens</h3>
|
||||
<div id="token-manage">
|
||||
<p><button onclick='doAction("expireTempTokens")'>🕒 Expire All Temp Tokens</button></p>
|
||||
<p><button onclick='doAction("cleanTempTokens")'>🧹 Delete Expired Temp Tokens</button></p>
|
||||
<p><button onclick='doAction("generateTempIpReport")'>📊 Generate Temp Token IP Report</button></p>
|
||||
</div>
|
||||
</div>
|
||||
<div>
|
||||
<h2>IP Whitelists and Blacklists</h2>
|
||||
<p>
|
||||
You can specify IP ranges to whitelist or blacklist from accessing the proxy. Entries can be specified as single
|
||||
addresses or
|
||||
<a href="https://en.wikipedia.org/wiki/Classless_Inter-Domain_Routing#CIDR_notation">CIDR notation</a>. IPv6 is
|
||||
supported but not recommended for use with the current version of the proxy.
|
||||
</p>
|
||||
<p>
|
||||
<strong>Note:</strong> Changes here are not persisted across server restarts. If you want to make changes permanent,
|
||||
you can copy the values to your deployment configuration.
|
||||
</p>
|
||||
<% for (let i = 0; i < whitelists.length; i++) { %>
|
||||
<%- include("partials/admin-cidr-widget", { list: whitelists[i] }) %>
|
||||
<% } %>
|
||||
<% for (let i = 0; i < blacklists.length; i++) { %>
|
||||
<%- include("partials/admin-cidr-widget", { list: blacklists[i] }) %>
|
||||
<% } %>
|
||||
<form action="/admin/manage/cidr" method="post" id="cidrForm">
|
||||
<input id="_csrf" type="hidden" name="_csrf" value="<%= csrfToken %>" />
|
||||
<input type="hidden" name="action" value="add" />
|
||||
<input type="hidden" name="name" value="" />
|
||||
<input type="hidden" name="mode" value="" />
|
||||
<input type="hidden" name="mask" value="" />
|
||||
</form>
|
||||
<details>
|
||||
<summary>Copy environment variables</summary>
|
||||
<p>
|
||||
If you have made changes with the UI, you can copy the values below to your deployment configuration to persist
|
||||
them across server restarts.
|
||||
</p>
|
||||
<pre>
|
||||
<% for (let i = 0; i < whitelists.length; i++) { %><%= whitelists[i].name %>=<%= whitelists[i].ranges.join(",") %><% } %>
|
||||
<% for (let i = 0; i < blacklists.length; i++) { %><%= blacklists[i].name %>=<%= blacklists[i].ranges.join(",") %><% } %>
|
||||
</pre>
|
||||
</details>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
function difficultyChanged(event) {
|
||||
const value = event.target.value;
|
||||
if (value === "custom") {
|
||||
document.getElementById("custom-difficulty-container").style.display = "block";
|
||||
} else {
|
||||
document.getElementById("custom-difficulty-container").style.display = "none";
|
||||
}
|
||||
}
|
||||
|
||||
function doAction(action) {
|
||||
document.getElementById("hiddenAction").value = action;
|
||||
if (action === "setDifficulty") {
|
||||
const selected = document.getElementById("difficulty").value;
|
||||
const hiddenDifficulty = document.getElementById("hiddenDifficulty");
|
||||
if (selected === "custom") {
|
||||
hiddenDifficulty.value = document.getElementById("customDifficulty").value;
|
||||
} else {
|
||||
hiddenDifficulty.value = selected;
|
||||
}
|
||||
}
|
||||
document.getElementById("maintenanceForm").submit();
|
||||
}
|
||||
|
||||
function onAddCidr(event) {
|
||||
const list = event.target.dataset;
|
||||
const newMask = prompt("Enter the IP or CIDR range to add to the list:");
|
||||
if (!newMask) {
|
||||
return;
|
||||
}
|
||||
|
||||
const form = document.getElementById("cidrForm");
|
||||
form["action"].value = "add";
|
||||
form["name"].value = list.name;
|
||||
form["mode"].value = list.mode;
|
||||
form["mask"].value = newMask;
|
||||
form.submit();
|
||||
}
|
||||
|
||||
function onRemoveCidr(event) {
|
||||
const list = event.target.dataset;
|
||||
const removeMask = event.target.dataset.mask;
|
||||
if (!removeMask) {
|
||||
return;
|
||||
}
|
||||
|
||||
const form = document.getElementById("cidrForm");
|
||||
form["action"].value = "remove";
|
||||
form["name"].value = list.name;
|
||||
form["mode"].value = list.mode;
|
||||
form["mask"].value = removeMask;
|
||||
form.submit();
|
||||
}
|
||||
</script>
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,132 @@
|
||||
<%- include("partials/shared_header", { title: "Create User - OAI Reverse Proxy Admin" }) %>
|
||||
|
||||
<style>
|
||||
#temporaryUserOptions {
|
||||
margin-top: 1em;
|
||||
max-width: 30em;
|
||||
}
|
||||
|
||||
#temporaryUserOptions h3 {
|
||||
margin-bottom: -0.4em;
|
||||
}
|
||||
|
||||
input[type="number"] {
|
||||
max-width: 10em;
|
||||
}
|
||||
|
||||
.temporary-user-fieldset {
|
||||
display: grid;
|
||||
grid-template-columns: repeat(4, 1fr); /* Four equal-width columns */
|
||||
column-gap: 1em;
|
||||
row-gap: 0.2em;
|
||||
}
|
||||
|
||||
.full-width {
|
||||
grid-column: 1 / -1;
|
||||
}
|
||||
|
||||
.quota-label {
|
||||
text-align: right;
|
||||
}
|
||||
</style>
|
||||
|
||||
<h1>Create User Token</h1>
|
||||
<p>User token types:</p>
|
||||
<ul>
|
||||
<li><strong>Normal</strong> - Standard users.
|
||||
<li><strong>Special</strong> - Exempt from token quotas and <code>MAX_IPS_PER_USER</code> enforcement.</li>
|
||||
<li><strong>Temporary</strong> - Disabled after a specified duration. Quotas never refresh.</li>
|
||||
</ul>
|
||||
|
||||
<form action="/admin/manage/create-user" method="post">
|
||||
<input type="hidden" name="_csrf" value="<%= csrfToken %>" />
|
||||
<label for="type">Type</label>
|
||||
<select name="type">
|
||||
<option value="normal">Normal</option>
|
||||
<option value="special">Special</option>
|
||||
<option value="temporary">Temporary</option>
|
||||
</select>
|
||||
<input type="submit" value="Create" />
|
||||
<fieldset id="temporaryUserOptions" style="display: none">
|
||||
<legend>Temporary User Options</legend>
|
||||
<div class="temporary-user-fieldset">
|
||||
<p class="full-width">
|
||||
Temporary users will be disabled after the specified duration, and their records will be permanently deleted after some time.
|
||||
These options apply only to new temporary users; existing ones use whatever options were in effect when they were created.
|
||||
</p>
|
||||
<label for="temporaryUserDuration" class="full-width">Access duration (in minutes)</label>
|
||||
<input type="number" name="temporaryUserDuration" id="temporaryUserDuration" value="60" class="full-width" />
|
||||
<!-- convenience calculations -->
|
||||
<span>6 hours:</span><code>360</code>
|
||||
<span>12 hours:</span><code>720</code>
|
||||
<span>1 day:</span><code>1440</code>
|
||||
<span>1 week:</span><code>10080</code>
|
||||
<h3 class="full-width">Token Quotas</h3>
|
||||
<p class="full-width">Temporary users' quotas are never refreshed.</p>
|
||||
<% Object.entries(quota).forEach(function([model, tokens]) { %>
|
||||
<label class="quota-label" for="temporaryUserQuota_<%= model %>"><%= model %></label>
|
||||
<input
|
||||
type="number"
|
||||
name="temporaryUserQuota_<%= model %>"
|
||||
id="temporaryUserQuota_<%= model %>"
|
||||
value="0"
|
||||
data-fieldtype="tokenquota"
|
||||
data-default="<%= tokens %>" />
|
||||
<% }) %>
|
||||
</div>
|
||||
</fieldset>
|
||||
</form>
|
||||
<% if (newToken) { %>
|
||||
<p>Just created <code><%= recentUsers[0].token %></code>.</p>
|
||||
<% } %>
|
||||
<h2>Recent Tokens</h2>
|
||||
<ul>
|
||||
<% recentUsers.forEach(function(user) { %>
|
||||
<li><a href="/admin/manage/view-user/<%= user.token %>"><%= user.token %></a></li>
|
||||
<% }) %>
|
||||
</ul>
|
||||
|
||||
<script>
|
||||
const typeInput = document.querySelector("select[name=type]");
|
||||
const temporaryUserOptions = document.querySelector("#temporaryUserOptions");
|
||||
typeInput.addEventListener("change", function () {
|
||||
localStorage.setItem("admin__create-user__type", typeInput.value);
|
||||
if (typeInput.value === "temporary") {
|
||||
temporaryUserOptions.style.display = "block";
|
||||
} else {
|
||||
temporaryUserOptions.style.display = "none";
|
||||
}
|
||||
});
|
||||
|
||||
function loadDefaults() {
|
||||
const defaultType = localStorage.getItem("admin__create-user__type");
|
||||
if (defaultType) {
|
||||
typeInput.value = defaultType;
|
||||
typeInput.dispatchEvent(new Event("change"));
|
||||
}
|
||||
|
||||
const durationInput = document.querySelector("input[name=temporaryUserDuration]");
|
||||
const defaultDuration = localStorage.getItem("admin__create-user__duration");
|
||||
durationInput.addEventListener("change", function () {
|
||||
localStorage.setItem("admin__create-user__duration", durationInput.value);
|
||||
});
|
||||
if (defaultDuration) {
|
||||
durationInput.value = defaultDuration;
|
||||
}
|
||||
|
||||
const tokenQuotaInputs = document.querySelectorAll("input[data-fieldtype=tokenquota]");
|
||||
tokenQuotaInputs.forEach(function (input) {
|
||||
const defaultQuota = localStorage.getItem("admin__create-user__quota__" + input.id);
|
||||
input.addEventListener("change", function () {
|
||||
localStorage.setItem("admin__create-user__quota__" + input.id, input.value);
|
||||
});
|
||||
if (defaultQuota) {
|
||||
input.value = defaultQuota;
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
loadDefaults();
|
||||
</script>
|
||||
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,138 @@
|
||||
<%- include("partials/shared_header", { title: "Download Stats - OAI Reverse Proxy Admin" }) %>
|
||||
<style>
|
||||
#statsForm {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
}
|
||||
|
||||
#statsForm ul {
|
||||
margin: 0;
|
||||
padding-left: 2em;
|
||||
font-size: 0.8em;
|
||||
}
|
||||
|
||||
#statsForm li {
|
||||
list-style: none;
|
||||
}
|
||||
|
||||
#statsForm textarea {
|
||||
font-family: monospace;
|
||||
flex-grow: 1;
|
||||
}
|
||||
</style>
|
||||
<h1>Download Stats</h1>
|
||||
<p>Download usage statistics to a Markdown document. You can paste this into a service like Rentry.org to share it.</p>
|
||||
<div>
|
||||
<h3>Options</h3>
|
||||
<form
|
||||
id="statsForm"
|
||||
action="/admin/manage/generate-stats"
|
||||
method="post"
|
||||
style="display: flex; flex-direction: column">
|
||||
<input id="_csrf" type="hidden" name="_csrf" value="<%= csrfToken %>" />
|
||||
<div>
|
||||
<label for="anon"><input id="anon" type="checkbox" name="anon" value="true" /> <span>Anonymize</span></label>
|
||||
</div>
|
||||
<div>
|
||||
<label for="sort">Sort</label>
|
||||
<select id="sort" name="sort">
|
||||
<option value="tokens" selected>By Token Count</option>
|
||||
<option value="prompts">By Prompt Count</option>
|
||||
</select>
|
||||
</div>
|
||||
<div>
|
||||
<label for="maxUsers">Max Users</label>
|
||||
<input id="maxUsers" type="number" name="maxUsers" value="1000" />
|
||||
</div>
|
||||
<div>
|
||||
<label for="tableType">Table Type</label>
|
||||
<select id="tableType" name="tableType">
|
||||
<option value="markdown" selected>Markdown Table</option>
|
||||
<option value="code">Code Block</option>
|
||||
</select>
|
||||
</div>
|
||||
<div>
|
||||
<label for="format">Custom Format</label>
|
||||
<ul>
|
||||
<li><code>{{header}}</code></li>
|
||||
<li><code>{{stats}}</code></li>
|
||||
<li><code>{{time}}</code></li>
|
||||
</ul>
|
||||
<textarea id="format" name="format" rows="10" cols="50" placeholder="{{stats}}">
|
||||
# Stats
|
||||
{{header}}
|
||||
{{stats}}
|
||||
{{time}}
|
||||
</textarea>
|
||||
</div>
|
||||
<div>
|
||||
<button type="submit">Download</button>
|
||||
<button id="copyButton" type="button">Copy to Clipboard</button>
|
||||
</div>
|
||||
</form>
|
||||
</div>
|
||||
|
||||
<script>
|
||||
function loadDefaults() {
|
||||
const getState = (key) => localStorage.getItem("admin__download-stats__" + key);
|
||||
const setState = (key, value) => localStorage.setItem("admin__download-stats__" + key, value);
|
||||
|
||||
const checkboxes = ["anon"];
|
||||
const values = ["sort", "format", "tableType", "maxUsers"];
|
||||
|
||||
checkboxes.forEach((key) => {
|
||||
const value = getState(key);
|
||||
if (value) {
|
||||
document.getElementById(key).checked = value == "true";
|
||||
}
|
||||
document.getElementById(key).addEventListener("change", (e) => {
|
||||
setState(key, e.target.checked);
|
||||
});
|
||||
});
|
||||
|
||||
values.forEach((key) => {
|
||||
const value = getState(key);
|
||||
if (value) {
|
||||
document.getElementById(key).value = value;
|
||||
}
|
||||
document.getElementById(key).addEventListener("change", (e) => {
|
||||
setState(key, e.target.value?.trim());
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
loadDefaults();
|
||||
|
||||
async function fetchAndCopy() {
|
||||
const form = document.getElementById("statsForm");
|
||||
const formData = new FormData(form);
|
||||
|
||||
const response = await fetch(form.action, {
|
||||
method: "POST",
|
||||
headers: { "Content-Type": "application/x-www-form-urlencoded" },
|
||||
credentials: "same-origin",
|
||||
body: new URLSearchParams(formData),
|
||||
});
|
||||
|
||||
if (response.ok) {
|
||||
const content = await response.text();
|
||||
copyToClipboard(content);
|
||||
} else {
|
||||
throw new Error("Failed to fetch generated stats. Try reloading the page.");
|
||||
}
|
||||
}
|
||||
|
||||
function copyToClipboard(text) {
|
||||
navigator.clipboard
|
||||
.writeText(text)
|
||||
.then(() => {
|
||||
alert("Copied to clipboard");
|
||||
})
|
||||
.catch((err) => {
|
||||
alert("Failed to copy to clipboard. Try downloading the file instead.");
|
||||
});
|
||||
}
|
||||
|
||||
document.getElementById("copyButton").addEventListener("click", fetchAndCopy);
|
||||
</script>
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,8 @@
|
||||
<%- include("partials/shared_header", { title: "Error" }) %>
|
||||
<div id="error-content" style="color: red; background-color: #eedddd; padding: 1em">
|
||||
<p><strong>⚠️ Error <%= status %>:</strong> <%= message %></p>
|
||||
<pre><%= stack %></pre>
|
||||
<a href="#" onclick="window.history.back()">Go Back</a> | <a href="/admin">Go Home</a>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
@@ -0,0 +1,28 @@
|
||||
<%- include("partials/shared_header", { title: "Export Users - OAI Reverse Proxy Admin" }) %>
|
||||
<h1>Export Users</h1>
|
||||
<p>
|
||||
Export users to JSON. The JSON will be an array of objects under the key
|
||||
<code>users</code>. You can use this JSON to import users later.
|
||||
</p>
|
||||
<script>
|
||||
function exportUsers() {
|
||||
var xhr = new XMLHttpRequest();
|
||||
xhr.open("GET", "/admin/manage/export-users.json", true);
|
||||
xhr.responseType = "blob";
|
||||
xhr.onload = function() {
|
||||
if (this.status === 200) {
|
||||
var blob = new Blob([this.response], { type: "application/json" });
|
||||
var url = URL.createObjectURL(blob);
|
||||
var a = document.createElement("a");
|
||||
a.href = url;
|
||||
a.download = "users.json";
|
||||
document.body.appendChild(a);
|
||||
a.click();
|
||||
a.remove();
|
||||
}
|
||||
};
|
||||
xhr.send();
|
||||
}
|
||||
</script>
|
||||
<button onclick="exportUsers()">Export</button>
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,54 @@
|
||||
<%- include("partials/shared_header", { title: "Import Users - OAI Reverse Proxy Admin" }) %>
|
||||
<h1>Import Users</h1>
|
||||
<p>
|
||||
Import users from JSON. The JSON should be an array of objects under the key
|
||||
<code>users</code>. Each object should have the following fields:
|
||||
</p>
|
||||
<ul>
|
||||
<li><code>token</code> (required): a unique identifier for the user</li>
|
||||
<li><code>nickname</code> (optional): a nickname for the user, max 80 chars</li>
|
||||
<li><code>ip</code> (optional): IP addresses the user has connected from</li>
|
||||
<li>
|
||||
<code>type</code> (optional): either <code>normal</code> or
|
||||
<code>special</code>
|
||||
</li>
|
||||
<li>
|
||||
<code>promptCount</code> (optional): the number of times the user has sent a
|
||||
prompt
|
||||
</li>
|
||||
<li>
|
||||
<code>tokenCounts</code> (optional): the number of tokens the user has
|
||||
consumed. This should be an object with model family keys (e.g. <code>turbo</code>,
|
||||
<code>gpt4</code>, <code>claude</code>), each containing an object with
|
||||
<code>input</code> and <code>output</code> token counts.
|
||||
</li>
|
||||
<li>
|
||||
<code>tokenLimits</code> (optional): the maximum number of tokens the user can
|
||||
consume. This should be an object with model family keys (e.g. <code>turbo</code>,
|
||||
<code>gpt4</code>, <code>claude</code>), each containing a single number
|
||||
representing the total token quota.
|
||||
</li>
|
||||
<li>
|
||||
<code>tokenRefresh</code> (optional): the amount of tokens to refresh when quotas
|
||||
are reset. Same format as <code>tokenLimits</code>.
|
||||
</li>
|
||||
<li>
|
||||
<code>createdAt</code> (optional): the timestamp when the user was created
|
||||
</li>
|
||||
<li>
|
||||
<code>disabledAt</code> (optional): the timestamp when the user was disabled
|
||||
</li>
|
||||
<li>
|
||||
<code>disabledReason</code> (optional): the reason the user was disabled
|
||||
</li>
|
||||
</ul>
|
||||
<p>
|
||||
If a user with the same token already exists, the existing user will be
|
||||
updated with the new values.
|
||||
</p>
|
||||
<form action="/admin/manage/import-users?_csrf=<%= csrfToken %>" method="post" enctype="multipart/form-data">
|
||||
<input type="file" name="users" />
|
||||
<input type="submit" value="Import" />
|
||||
</form>
|
||||
</form>
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,79 @@
|
||||
<%- include("partials/shared_header", { title: "OAI Reverse Proxy Admin" }) %>
|
||||
<h1>OAI Reverse Proxy Admin</h1>
|
||||
<% if (!usersEnabled) { %>
|
||||
<p style="color: red; background-color: #eedddd; padding: 1em">
|
||||
<strong>🚨 <code>user_token</code> gatekeeper is not enabled.</strong><br />
|
||||
<br />None of the user management features will do anything.
|
||||
</p>
|
||||
<% } %>
|
||||
<% if (!persistenceEnabled) { %>
|
||||
<p style="color: red; background-color: #eedddd; padding: 1em">
|
||||
<strong>⚠️ Users will be lost when the server restarts because persistence is not configured.</strong><br />
|
||||
<br />Be sure to export your users and import them again after restarting the server if you want to keep them.<br />
|
||||
<br />
|
||||
See the
|
||||
<a target="_blank" href="https://gitgud.io/khanon/oai-reverse-proxy/-/blob/main/docs/user-management.md#firebase-realtime-database">
|
||||
user management documentation</a
|
||||
>
|
||||
to learn how to set up persistence.
|
||||
</p>
|
||||
<% } %>
|
||||
<h3>Users</h3>
|
||||
<ul>
|
||||
<li><a href="/admin/manage/list-users">List Users</a></li>
|
||||
<li><a href="/admin/manage/create-user">Create User</a></li>
|
||||
<li><a href="/admin/manage/import-users">Import Users</a></li>
|
||||
<li><a href="/admin/manage/export-users">Export Users</a></li>
|
||||
<li><a href="/admin/manage/download-stats">Download Rentry Stats</a>
|
||||
<li><a href="/admin/manage/anti-abuse">Abuse Mitigation Settings</a></li>
|
||||
<li><a href="/admin/service-info">Service Info</a></li>
|
||||
</ul>
|
||||
<h3>Maintenance</h3>
|
||||
<form id="maintenanceForm" action="/admin/manage/maintenance" method="post">
|
||||
<input id="_csrf" type="hidden" name="_csrf" value="<%= csrfToken %>" />
|
||||
<input id="hiddenAction" type="hidden" name="action" value="" />
|
||||
<div>
|
||||
<fieldset>
|
||||
<legend>Key Recheck</legend>
|
||||
<button id="recheck-keys" type="button" onclick="submitForm('recheck')">Force Key Recheck</button>
|
||||
<label for="recheck-keys">Triggers a recheck of all keys without restarting the server.</label>
|
||||
</fieldset>
|
||||
<% if (quotasEnabled) { %>
|
||||
<fieldset>
|
||||
<legend>Bulk Quota Management</legend>
|
||||
<p>
|
||||
<button id="refresh-quotas" type="button" onclick="submitForm('resetQuotas')">Refresh All Quotas</button>
|
||||
Immediately refreshes all users' quotas by the configured amounts.
|
||||
</p>
|
||||
<p>
|
||||
<button id="clear-token-counts" type="button" onclick="submitForm('resetCounts')">Clear All Token Counts</button>
|
||||
Resets all users' token records to zero.
|
||||
</p>
|
||||
</fieldset>
|
||||
<% } %>
|
||||
<% if (imageGenerationEnabled) { %>
|
||||
<fieldset>
|
||||
<legend>Image Generation</legend>
|
||||
<button id="download-image-metadata" type="button" onclick="submitForm('downloadImageMetadata')">Download Image Metadata</button>
|
||||
<label for="download-image-metadata">Downloads a metadata file containing URL, prompt, and truncated user token for all cached images.</label>
|
||||
</fieldset>
|
||||
<% } %>
|
||||
</div>
|
||||
</form>
|
||||
|
||||
<script>
|
||||
let confirmed = false;
|
||||
function submitForm(action) {
|
||||
if (action === "resetCounts" && !confirmed) {
|
||||
document.getElementById("clear-token-counts").innerText = "💣 Confirm Clear All Token Counts";
|
||||
alert("⚠️ This will permanently clear token records for all users. If you only want to refresh quotas, use the other button.");
|
||||
confirmed = true;
|
||||
return;
|
||||
}
|
||||
|
||||
document.getElementById("hiddenAction").value = action;
|
||||
document.getElementById("maintenanceForm").submit();
|
||||
}
|
||||
</script>
|
||||
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,86 @@
|
||||
<%- include("partials/shared_header", { title: "Users - OAI Reverse Proxy Admin" }) %>
|
||||
<h1>User Token List</h1>
|
||||
|
||||
<% if (users.length === 0) { %>
|
||||
<p>No users found.</p>
|
||||
<% } else { %>
|
||||
<label for="toggle-nicknames"><input type="checkbox" id="toggle-nicknames" onchange="toggleNicknames()" /> Show Nicknames</label>
|
||||
<table class="striped full-width">
|
||||
<thead>
|
||||
<tr>
|
||||
<th>User</th>
|
||||
<th <% if (sort.includes("ip")) { %>class="active"<% } %> ><a href="/admin/manage/list-users?sort=ip">IPs</a></th>
|
||||
<th <% if (sort.includes("promptCount")) { %>class="active"<% } %> ><a href="/admin/manage/list-users?sort=promptCount">Prompts</a></th>
|
||||
<th <% if (sort.includes("sumCost")) { %>class="active"<% } %> ><a href="/admin/manage/list-users?sort=sumCost">Usage</a></th>
|
||||
<th>Type</th>
|
||||
<th <% if (sort.includes("createdAt")) { %>class="active"<% } %> ><a href="/admin/manage/list-users?sort=createdAt">Created (UTC)</a></th>
|
||||
<th <% if (sort.includes("lastUsedAt")) { %>class="active"<% } %> ><a href="/admin/manage/list-users?sort=lastUsedAt">Last Used (UTC)</a></th>
|
||||
<th colspan="2">Banned?</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<% users.forEach(function(user){ %>
|
||||
<tr>
|
||||
<td>
|
||||
<a href="/admin/manage/view-user/<%= user.token %>">
|
||||
<code class="usertoken"><%= user.token %></code>
|
||||
<% if (user.nickname) { %>
|
||||
<span class="nickname" style="display: none"><%= user.nickname %></span>
|
||||
<% } else { %>
|
||||
<code class="nickname" style="display: none"><%= "..." + user.token.slice(-5) %></code>
|
||||
<% } %>
|
||||
</a>
|
||||
</td>
|
||||
<td><%= user.ip.length %></td>
|
||||
<td><%= user.promptCount %></td>
|
||||
<td><%= user.prettyUsage %></td>
|
||||
<td><%= user.type %></td>
|
||||
<td><%= user.createdAt %></td>
|
||||
<td><%= user.lastUsedAt ?? "never" %></td>
|
||||
<td class="actions">
|
||||
<% if (user.disabledAt) { %>
|
||||
<a title="Unban" href="#" class="unban" data-token="<%= user.token %>">🔄️</a>
|
||||
<% } else { %>
|
||||
<a title="Ban" href="#" class="ban" data-token="<%= user.token %>">🚫</a>
|
||||
<% } %>
|
||||
<td><%= user.disabledAt ? "Yes" : "No" %> <%= user.disabledReason ? `(${user.disabledReason})` : "" %></td>
|
||||
</td>
|
||||
</tr>
|
||||
<% }); %>
|
||||
</table>
|
||||
<ul class="pagination">
|
||||
<% if (page > 1) { %>
|
||||
<li><a href="/admin/manage/list-users?sort=<%= sort %>&page=<%= page - 1 %>">«</a></li>
|
||||
<% } %> <% for (var i = 1; i <= pageCount; i++) { %>
|
||||
<li <% if (i === page) { %>class="active"<% } %>><a href="/admin/manage/list-users?sort=<%= sort %>&page=<%= i %>"><%= i %></a></li>
|
||||
<% } %> <% if (page < pageCount) { %>
|
||||
<li><a href="/admin/manage/list-users?sort=<%= sort %>&page=<%= page + 1 %>">»</a></li>
|
||||
<% } %>
|
||||
</ul>
|
||||
|
||||
<p>Showing <%= page * pageSize - pageSize + 1 %> to <%= users.length + page * pageSize - pageSize %> of <%= totalCount %> users.</p>
|
||||
<%- include("partials/shared_pagination") %>
|
||||
<% } %>
|
||||
|
||||
<script>
|
||||
function toggleNicknames() {
|
||||
const checked = document.getElementById("toggle-nicknames").checked;
|
||||
const visibleSelector = checked ? ".nickname" : ".usertoken";
|
||||
const hiddenSelector = checked ? ".usertoken" : ".nickname";
|
||||
document.querySelectorAll(visibleSelector).forEach(function (el) {
|
||||
el.style.display = "inline";
|
||||
});
|
||||
document.querySelectorAll(hiddenSelector).forEach(function (el) {
|
||||
el.style.display = "none";
|
||||
});
|
||||
localStorage.setItem("showNicknames", checked);
|
||||
}
|
||||
|
||||
const state = localStorage.getItem("showNicknames") === "true";
|
||||
document.getElementById("toggle-nicknames").checked = state;
|
||||
toggleNicknames();
|
||||
</script>
|
||||
|
||||
<%- include("partials/admin-ban-xhr-script") %>
|
||||
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,10 @@
|
||||
<%- include("partials/shared_header", { title: "Login" }) %>
|
||||
<h1>Login</h1>
|
||||
<form action="/admin/login" method="post">
|
||||
<input type="hidden" name="_csrf" value="<%= csrfToken %>" />
|
||||
<label for="token">Admin Key</label>
|
||||
<input type="password" name="token" />
|
||||
<input type="submit" value="Login" />
|
||||
</form>
|
||||
</body>
|
||||
</html>
|
||||
@@ -0,0 +1,166 @@
|
||||
<%- include("partials/shared_header", { title: "View User - OAI Reverse Proxy Admin" }) %>
|
||||
<h1>View User</h1>
|
||||
|
||||
<table class="striped">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">Key</th>
|
||||
<th scope="col" colspan="2">Value</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th scope="row">Token</th>
|
||||
<td colspan="2"><%- user.token %></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Nickname</th>
|
||||
<td><%- user.nickname ?? "none" %></td>
|
||||
<td class="actions">
|
||||
<a title="Edit" id="edit-nickname" href="#" data-field="nickname" data-token="<%= user.token %>">✏️</a>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Type</th>
|
||||
<td><%- user.type %></td>
|
||||
<td class="actions">
|
||||
<a title="Edit" id="edit-type" href="#" data-field="type" data-token="<%= user.token %>">✏️</a>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Prompts</th>
|
||||
<td colspan="2"><%- user.promptCount %></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Created At</th>
|
||||
<td colspan="2"><%- user.createdAt %></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Last Used At</th>
|
||||
<td colspan="2"><%- user.lastUsedAt || "never" %></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Disabled At</th>
|
||||
<td><%- user.disabledAt %></td>
|
||||
<td class="actions">
|
||||
<% if (user.disabledAt) { %>
|
||||
<a title="Unban" href="#" class="unban" data-token="<%= user.token %>">🔄️</a>
|
||||
<% } else { %>
|
||||
<a title="Ban" href="#" class="ban" data-token="<%= user.token %>">🚫</a>
|
||||
<% } %>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">Disabled Reason</th>
|
||||
<td><%- user.disabledReason %></td>
|
||||
<% if (user.disabledAt) { %>
|
||||
<td class="actions">
|
||||
<a title="Edit" id="edit-disabledReason" href="#" data-field="disabledReason" data-token="<%= user.token %>"
|
||||
>✏️</a
|
||||
>
|
||||
</td>
|
||||
<% } %>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">IP Address Limit</th>
|
||||
<td><%- (user.maxIps ?? maxIps) || "Unlimited" %></td>
|
||||
<td class="actions">
|
||||
<a title="Edit" id="edit-maxIps" href="#" data-field="maxIps" data-token="<%= user.token %>">✏️</a>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">IPs</th>
|
||||
<td colspan="2"><%- include("partials/shared_user_ip_list", { user, shouldRedact: false }) %></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th scope="row">
|
||||
Admin Note <span title="Unlike nickname, this is not visible to or editable by the user">🔒</span>
|
||||
</th>
|
||||
<td><%- user.adminNote ?? "none" %></td>
|
||||
<td class="actions">
|
||||
<a title="Edit" id="edit-adminNote" href="#" data-field="adminNote" data-token="<%= user.token %>">✏️</a>
|
||||
</td>
|
||||
</tr>
|
||||
<% if (user.type === "temporary") { %>
|
||||
<tr>
|
||||
<th scope="row">Expires At</th>
|
||||
<td colspan="2"><%- user.expiresAt %></td>
|
||||
</tr>
|
||||
<% } %>
|
||||
<% if (user.meta) { %>
|
||||
<tr>
|
||||
<th scope="row">Meta</th>
|
||||
<td colspan="2"><%- JSON.stringify(user.meta) %></td>
|
||||
</tr>
|
||||
<% } %>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
<form style="display: none" id="current-values">
|
||||
<input type="hidden" name="token" value="<%- user.token %>" />
|
||||
<% ["nickname", "type", "disabledAt", "disabledReason", "maxIps", "adminNote"].forEach(function (key) { %>
|
||||
<input type="hidden" name="<%- key %>" value="<%- user[key] %>" />
|
||||
<% }); %>
|
||||
<!-- tokenRefresh_ keys are dynamically generated -->
|
||||
<% Object.entries(quota).forEach(([family]) => { %>
|
||||
<input type="hidden" name="tokenRefresh_<%- family %>" value="<%- user.tokenRefresh[family] || quota[family] %>" />
|
||||
<% }); %>
|
||||
</form>
|
||||
|
||||
<h3>Quota Information</h3>
|
||||
<% if (quotasEnabled) { %>
|
||||
<form action="/admin/manage/refresh-user-quota" method="POST">
|
||||
<input type="hidden" name="token" value="<%- user.token %>" />
|
||||
<input type="hidden" name="_csrf" value="<%- csrfToken %>" />
|
||||
<button type="submit" class="btn btn-primary">Refresh Quotas for User</button>
|
||||
</form>
|
||||
<% } %>
|
||||
<%- include("partials/shared_quota-info", { quota, user, showRefreshEdit: true }) %>
|
||||
|
||||
<p><a href="/admin/manage/list-users">Back to User List</a></p>
|
||||
|
||||
<script>
|
||||
document.querySelectorAll("td.actions a[data-field]").forEach(function (a) {
|
||||
a.addEventListener("click", function (e) {
|
||||
e.preventDefault();
|
||||
const token = a.dataset.token;
|
||||
const field = a.dataset.field;
|
||||
const existingValue = document.querySelector(`#current-values input[name=${field}]`).value;
|
||||
|
||||
let value = prompt(`Enter new value for '${field}':`, existingValue);
|
||||
if (value !== null) {
|
||||
if (value === "") {
|
||||
value = null;
|
||||
}
|
||||
|
||||
const payload = { _csrf: document.querySelector("meta[name=csrf-token]").getAttribute("content") };
|
||||
if (field.startsWith("tokenRefresh_")) {
|
||||
const family = field.slice("tokenRefresh_".length);
|
||||
payload.tokenRefresh = { [family]: Number(value) };
|
||||
} else {
|
||||
payload[field] = value;
|
||||
}
|
||||
|
||||
fetch(`/admin/manage/edit-user/${token}`, {
|
||||
method: "POST",
|
||||
credentials: "same-origin",
|
||||
body: JSON.stringify(payload),
|
||||
headers: { "Content-Type": "application/json", Accept: "application/json" },
|
||||
})
|
||||
.then((res) => Promise.all([res.ok, res.json()]))
|
||||
.then(([ok, json]) => {
|
||||
const url = new URL(window.location.href);
|
||||
const params = new URLSearchParams();
|
||||
if (!ok) {
|
||||
alert(`Failed to edit user: ${json.message}`);
|
||||
}
|
||||
url.search = params.toString();
|
||||
window.location.assign(url);
|
||||
});
|
||||
}
|
||||
});
|
||||
});
|
||||
</script>
|
||||
|
||||
<%- include("partials/admin-ban-xhr-script") %>
|
||||
<%- include("partials/admin-footer") %>
|
||||
@@ -0,0 +1,32 @@
|
||||
<script>
|
||||
document.querySelectorAll("td.actions a.ban").forEach(function (a) {
|
||||
a.addEventListener("click", function (e) {
|
||||
e.preventDefault();
|
||||
var token = a.getAttribute("data-token");
|
||||
if (confirm("Are you sure you want to ban this user?")) {
|
||||
let reason = prompt("Reason for ban:");
|
||||
fetch("/admin/manage/disable-user/" + token, {
|
||||
method: "POST",
|
||||
credentials: "same-origin",
|
||||
body: JSON.stringify({ reason, _csrf: document.querySelector("meta[name=csrf-token]").getAttribute("content") }),
|
||||
headers: { "Content-Type": "application/json" },
|
||||
}).then(() => window.location.reload());
|
||||
}
|
||||
});
|
||||
});
|
||||
|
||||
document.querySelectorAll("td.actions a.unban").forEach(function (a) {
|
||||
a.addEventListener("click", function (e) {
|
||||
e.preventDefault();
|
||||
var token = a.getAttribute("data-token");
|
||||
if (confirm("Are you sure you want to unban this user?")) {
|
||||
fetch("/admin/manage/reactivate-user/" + token, {
|
||||
method: "POST",
|
||||
credentials: "same-origin",
|
||||
body: JSON.stringify({ _csrf: document.querySelector("meta[name=csrf-token]").getAttribute("content") }),
|
||||
headers: { "Content-Type": "application/json" },
|
||||
}).then(() => window.location.reload());
|
||||
}
|
||||
});
|
||||
});
|
||||
</script>
|
||||
@@ -0,0 +1,13 @@
|
||||
<h3>
|
||||
<%= list.name %>
|
||||
(<%= list.mode %>)
|
||||
</h3>
|
||||
<ul>
|
||||
<% list.ranges.forEach(function(mask) { %>
|
||||
<li>
|
||||
<%= mask %>
|
||||
<button class="remove" data-mode="<%= list.mode %>" data-name="<%= list.name %>" data-mask="<%= mask %>" onclick="onRemoveCidr(event)">Remove</button>
|
||||
</li>
|
||||
<% }); %>
|
||||
</ul>
|
||||
<button class="add" data-mode="<%= list.mode %>" data-name="<%= list.name %>" onclick="onAddCidr(event)">Add</button>
|
||||
@@ -0,0 +1,15 @@
|
||||
<hr />
|
||||
<footer>
|
||||
<a href="/admin">Index</a> | <a href="/admin/logout">Logout</a>
|
||||
</footer>
|
||||
<script>
|
||||
document.querySelectorAll("td,time").forEach(function(td) {
|
||||
if (td.innerText.match(/^\d{13}$/)) {
|
||||
if (td.innerText == 0) return 'never';
|
||||
var date = new Date(parseInt(td.innerText));
|
||||
td.innerText = date.toISOString().replace("T", " ").replace(/\.\d+Z$/, "Z");
|
||||
}
|
||||
});
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
+959
@@ -0,0 +1,959 @@
|
||||
import crypto from "crypto";
|
||||
import dotenv from "dotenv";
|
||||
import type firebase from "firebase-admin";
|
||||
import path from "path";
|
||||
import pino from "pino";
|
||||
import type { LLMService, ModelFamily } from "./shared/models";
|
||||
import { MODEL_FAMILIES } from "./shared/models";
|
||||
|
||||
dotenv.config();
|
||||
|
||||
const startupLogger = pino({ level: "debug" }).child({ module: "startup" });
|
||||
const isDev = process.env.NODE_ENV !== "production";
|
||||
|
||||
export const DATA_DIR = path.join(__dirname, "..", "data");
|
||||
export const USER_ASSETS_DIR = path.join(DATA_DIR, "user-files");
|
||||
|
||||
type Config = {
|
||||
/** The port the proxy server will listen on. */
|
||||
port: number;
|
||||
/** The network interface the proxy server will listen on. */
|
||||
bindAddress: string;
|
||||
/** Comma-delimited list of OpenAI API keys. */
|
||||
openaiKey?: string;
|
||||
/** Comma-delimited list of Anthropic API keys. */
|
||||
anthropicKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Google AI API keys. Note that these are not the
|
||||
* same as the GCP keys/credentials used for Vertex AI; the models are the
|
||||
* same but the APIs are different. Vertex is the GCP product for enterprise.
|
||||
**/
|
||||
googleAIKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Google AI experimental model names that are
|
||||
* allowed to bypass the experimental model block. By default, all models
|
||||
* containing "exp" are blocked, but specific models listed here will be
|
||||
* permitted.
|
||||
*
|
||||
* @example "gemini-2.0-flash-exp,gemini-exp-1206"
|
||||
*/
|
||||
allowedExpModels?: string;
|
||||
/**
|
||||
* Comma-delimited list of Mistral AI API keys.
|
||||
*/
|
||||
mistralAIKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Deepseek API keys.
|
||||
*/
|
||||
deepseekKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Xai (Grok) API keys.
|
||||
*/
|
||||
xaiKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Cohere API keys.
|
||||
*/
|
||||
cohereKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Qwen API keys.
|
||||
*/
|
||||
qwenKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of GLM API keys.
|
||||
*/
|
||||
glmKey?: string;
|
||||
/**
|
||||
* Comma-delimited list of Moonshot API keys.
|
||||
*/
|
||||
moonshotKey?: string;
|
||||
|
||||
/**
|
||||
* Comma-delimited list of AWS credentials. Each credential item should be a
|
||||
* colon-delimited list of access key, secret key, and AWS region.
|
||||
*
|
||||
* The credentials must have access to the actions `bedrock:InvokeModel` and
|
||||
* `bedrock:InvokeModelWithResponseStream`. You must also have already
|
||||
* provisioned the necessary models in your AWS account, on the specific
|
||||
* regions specified for each credential. Models are region-specific.
|
||||
*
|
||||
* @example `AWS_CREDENTIALS=access_key_1:secret_key_1:us-east-1,access_key_2:secret_key_2:us-west-2`
|
||||
*/
|
||||
awsCredentials?: string;
|
||||
/**
|
||||
* Comma-delimited list of GCP credentials. Each credential item should be a
|
||||
* colon-delimited list of access key, secret key, and GCP region.
|
||||
*
|
||||
* @example `GCP_CREDENTIALS=project1:1@1.com:us-east5:-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----,project2:2@2.com:us-east5:-----BEGIN PRIVATE KEY-----xxx-----END PRIVATE KEY-----`
|
||||
*/
|
||||
gcpCredentials?: string;
|
||||
/**
|
||||
* Comma-delimited list of Azure OpenAI credentials. Each credential item
|
||||
* should be a colon-delimited list of Azure resource name, deployment ID, and
|
||||
* API key.
|
||||
*
|
||||
* The resource name is the subdomain in your Azure OpenAI deployment's URL,
|
||||
* e.g. `https://resource-name.openai.azure.com
|
||||
*
|
||||
* @example `AZURE_CREDENTIALS=resource_name_1:deployment_id_1:api_key_1,resource_name_2:deployment_id_2:api_key_2`
|
||||
*/
|
||||
azureCredentials?: string;
|
||||
/**
|
||||
* The proxy key to require for requests. Only applicable if the user
|
||||
* management mode is set to 'proxy_key', and required if so.
|
||||
*/
|
||||
proxyKey?: string;
|
||||
/**
|
||||
* The admin key used to access the /admin API or UI. Required if the user
|
||||
* management mode is set to 'user_token'.
|
||||
*/
|
||||
adminKey?: string;
|
||||
/**
|
||||
* Which user management mode to use.
|
||||
* - `none`: No user management. Proxy is open to all requests with basic
|
||||
* abuse protection.
|
||||
* - `proxy_key`: A specific proxy key must be provided in the Authorization
|
||||
* header to use the proxy.
|
||||
* - `user_token`: Users must be created via by admins and provide their
|
||||
* personal access token in the Authorization header to use the proxy.
|
||||
* Configure this function and add users via the admin API or UI.
|
||||
*/
|
||||
gatekeeper: "none" | "proxy_key" | "user_token";
|
||||
/**
|
||||
* Persistence layer to use for user management.
|
||||
* - `memory`: Users are stored in memory and are lost on restart (default)
|
||||
* - `firebase_rtdb`: Users are stored in a Firebase Realtime Database;
|
||||
* requires `firebaseKey` and `firebaseRtdbUrl` to be set.
|
||||
* - `sqlite`: Users are stored in an SQLite database; requires
|
||||
* `sqliteUserStorePath` to be set.
|
||||
*/
|
||||
gatekeeperStore: "memory" | "firebase_rtdb" | "sqlite";
|
||||
/** URL of the Firebase Realtime Database if using the Firebase RTDB store. */
|
||||
firebaseRtdbUrl?: string;
|
||||
/** Path to the SQLite database file for storing user data. */
|
||||
sqliteUserStorePath?: string;
|
||||
/**
|
||||
* Base64-encoded Firebase service account key if using the Firebase RTDB
|
||||
* store. Note that you should encode the *entire* JSON key file, not just the
|
||||
* `private_key` field inside it.
|
||||
*/
|
||||
firebaseKey?: string;
|
||||
/**
|
||||
* Maximum number of IPs allowed per user token.
|
||||
* Users with the manually-assigned `special` role are exempt from this limit.
|
||||
* - Defaults to 0, which means that users are not IP-limited.
|
||||
*/
|
||||
maxIpsPerUser: number;
|
||||
/**
|
||||
* Whether a user token should be automatically disabled if it exceeds the
|
||||
* `maxIpsPerUser` limit, or if only connections from new IPs are be rejected.
|
||||
*/
|
||||
maxIpsAutoBan: boolean;
|
||||
/**
|
||||
* Which captcha verification mode to use. Requires `user_token` gatekeeper.
|
||||
* Allows users to automatically obtain a token by solving a captcha.
|
||||
* - `none`: No captcha verification; tokens are issued manually.
|
||||
* - `proof_of_work`: Users must solve an Argon2 proof of work to obtain a
|
||||
* temporary usertoken valid for a limited period.
|
||||
*/
|
||||
captchaMode: "none" | "proof_of_work";
|
||||
/**
|
||||
* Duration (in hours) for which a PoW-issued temporary user token is valid.
|
||||
*/
|
||||
powTokenHours: number;
|
||||
/**
|
||||
* The maximum number of IPs from which a single temporary user token can be
|
||||
* used. Upon reaching the limit, the `maxIpsAutoBan` behavior is triggered.
|
||||
*/
|
||||
powTokenMaxIps: number;
|
||||
/**
|
||||
* Difficulty level for the proof-of-work challenge.
|
||||
* - `low`: 200 iterations
|
||||
* - `medium`: 900 iterations
|
||||
* - `high`: 1900 iterations
|
||||
* - `extreme`: 4000 iterations
|
||||
* - `number`: A custom number of iterations to use.
|
||||
*
|
||||
* Difficulty level only affects the number of iterations used in the PoW,
|
||||
* not the complexity of the hash itself. Therefore, the average time-to-solve
|
||||
* will scale linearly with the number of iterations.
|
||||
*
|
||||
* Refer to docs/proof-of-work.md for guidance and hashrate benchmarks.
|
||||
*/
|
||||
powDifficultyLevel: "low" | "medium" | "high" | "extreme" | number;
|
||||
/**
|
||||
* Duration (in minutes) before a PoW challenge expires. Users' browsers must
|
||||
* solve the challenge within this time frame or it will be rejected. Should
|
||||
* be kept somewhat low to prevent abusive clients from working on many
|
||||
* challenges in parallel, but you may need to increase this value for higher
|
||||
* difficulty levels or older devices will not be able to solve the challenge
|
||||
* in time.
|
||||
*
|
||||
* Defaults to 30 minutes.
|
||||
*/
|
||||
powChallengeTimeout: number;
|
||||
/**
|
||||
* Duration (in hours) before expired temporary user tokens are purged from
|
||||
* the user database. Users can refresh expired tokens by solving a faster PoW
|
||||
* challenge as long as the original token has not been purged. Once purged,
|
||||
* the user must solve a full PoW challenge to obtain a new token.
|
||||
*
|
||||
* Defaults to 48 hours. At 0, tokens are purged immediately upon expiry.
|
||||
*/
|
||||
powTokenPurgeHours: number;
|
||||
/**
|
||||
* Maximum number of active temporary user tokens that can be associated with
|
||||
* a single IP address. Note that this may impact users sending requests from
|
||||
* hosted AI chat clients such as Agnaistic or RisuAI, as they may share IPs.
|
||||
*
|
||||
* When the limit is reached, the oldest token with the same IP will be
|
||||
* expired. At 0, no limit is enforced. Defaults to 0.
|
||||
*/
|
||||
// powMaxTokensPerIp: number;
|
||||
/** Per-user limit for requests per minute to text and chat models. */
|
||||
textModelRateLimit: number;
|
||||
/** Per-user limit for requests per minute to image generation models. */
|
||||
imageModelRateLimit: number;
|
||||
/**
|
||||
* For OpenAI, the maximum number of context tokens (prompt + max output) a
|
||||
* user can request before their request is rejected.
|
||||
* Context limits can help prevent excessive spend.
|
||||
* - Defaults to 0, which means no limit beyond OpenAI's stated maximums.
|
||||
*/
|
||||
maxContextTokensOpenAI: number;
|
||||
/**
|
||||
* For Anthropic, the maximum number of context tokens a user can request.
|
||||
* Claude context limits can prevent requests from tying up concurrency slots
|
||||
* for too long, which can lengthen queue times for other users.
|
||||
* - Defaults to 0, which means no limit beyond Anthropic's stated maximums.
|
||||
*/
|
||||
maxContextTokensAnthropic: number;
|
||||
/** For OpenAI, the maximum number of sampled tokens a user can request. */
|
||||
maxOutputTokensOpenAI: number;
|
||||
/** For Anthropic, the maximum number of sampled tokens a user can request. */
|
||||
maxOutputTokensAnthropic: number;
|
||||
/** Whether requests containing the following phrases should be rejected. */
|
||||
rejectPhrases: string[];
|
||||
/** Message to return when rejecting requests. */
|
||||
rejectMessage: string;
|
||||
/** Verbosity level of diagnostic logging. */
|
||||
logLevel: "trace" | "debug" | "info" | "warn" | "error";
|
||||
/**
|
||||
* Whether to allow the usage of AWS credentials which could be logging users'
|
||||
* model invocations. By default, such keys are treated as if they were
|
||||
* disabled because users may not be aware that their usage is being logged.
|
||||
*
|
||||
* Some credentials do not have the policy attached that allows the proxy to
|
||||
* confirm logging status, in which case the proxy assumes that logging could
|
||||
* be enabled and will refuse to use the key. If you still want to use such a
|
||||
* key and can't attach the policy, you can set this to true.
|
||||
*/
|
||||
allowAwsLogging?: boolean;
|
||||
/**
|
||||
* Path to the SQLite database file for storing data such as event logs. By
|
||||
* default, the database will be stored at `data/database.sqlite`.
|
||||
*
|
||||
* Ensure target is writable by the server process, and be careful not to
|
||||
* select a path that is served publicly. The default path is safe.
|
||||
*/
|
||||
sqliteDataPath?: string;
|
||||
/**
|
||||
* Whether to log events, such as generated completions, to the database.
|
||||
* Events are associated with IP+user token pairs. If user_token mode is
|
||||
* disabled, no events will be logged.
|
||||
*
|
||||
* Currently there is no pruning mechanism for the events table, so it will
|
||||
* grow indefinitely. You may want to periodically prune the table manually.
|
||||
*/
|
||||
eventLogging?: boolean;
|
||||
/**
|
||||
* When hashing prompt histories, how many messages to trim from the end.
|
||||
* If zero, only the full prompt hash will be stored.
|
||||
* If greater than zero, for each number N, a hash of the prompt with the
|
||||
* last N messages removed will be stored.
|
||||
*
|
||||
* Experimental function, config may change in future versions.
|
||||
*/
|
||||
eventLoggingTrim?: number;
|
||||
/** Whether prompts and responses should be logged to persistent storage. */
|
||||
promptLogging?: boolean;
|
||||
/** Which prompt logging backend to use. */
|
||||
promptLoggingBackend?: "google_sheets" | "file";
|
||||
/** Prefix for prompt logging files when using the file backend. */
|
||||
promptLoggingFilePrefix?: string;
|
||||
/** Base64-encoded Google Sheets API key. */
|
||||
googleSheetsKey?: string;
|
||||
/** Google Sheets spreadsheet ID. */
|
||||
googleSheetsSpreadsheetId?: string;
|
||||
/** Whether to periodically check keys for usage and validity. */
|
||||
checkKeys: boolean;
|
||||
/** Whether to publicly show total token costs on the info page. */
|
||||
showTokenCosts: boolean;
|
||||
/**
|
||||
* Comma-separated list of origins to block. Requests matching any of these
|
||||
* origins or referers will be rejected.
|
||||
* - Partial matches are allowed, so `reddit` will match `www.reddit.com`.
|
||||
* - Include only the hostname, not the protocol or path, e.g:
|
||||
* `reddit.com,9gag.com,gaiaonline.com`
|
||||
*/
|
||||
blockedOrigins?: string;
|
||||
/** Message to return when rejecting requests from blocked origins. */
|
||||
blockMessage?: string;
|
||||
/** Destination URL to redirect blocked requests to, for non-JSON requests. */
|
||||
blockRedirect?: string;
|
||||
/** Which model families to allow requests for. Applies only to OpenAI. */
|
||||
allowedModelFamilies: ModelFamily[];
|
||||
/**
|
||||
* The number of (LLM) tokens a user can consume before requests are rejected.
|
||||
* Limits include both prompt and response tokens. `special` users are exempt.
|
||||
* - Defaults to 0, which means no limit.
|
||||
* - Changes are not automatically applied to existing users. Use the
|
||||
* admin API or UI to update existing users, or use the QUOTA_REFRESH_PERIOD
|
||||
* setting to periodically set all users' quotas to these values.
|
||||
*/
|
||||
tokenQuota: { [key in ModelFamily]: number };
|
||||
/**
|
||||
* The period over which to enforce token quotas. Quotas will be fully reset
|
||||
* at the start of each period, server time. Unused quota does not roll over.
|
||||
* You can also provide a cron expression for a custom schedule. If not set,
|
||||
* quotas will never automatically refresh.
|
||||
* - Defaults to unset, which means quotas will never automatically refresh.
|
||||
*/
|
||||
quotaRefreshPeriod?: "hourly" | "daily" | string;
|
||||
/** Whether to allow users to change their own nicknames via the UI. */
|
||||
allowNicknameChanges: boolean;
|
||||
/** Whether to show recent DALL-E image generations on the homepage. */
|
||||
showRecentImages: boolean;
|
||||
/**
|
||||
* If true, cookies will be set without the `Secure` attribute, allowing
|
||||
* the admin UI to used over HTTP.
|
||||
*/
|
||||
useInsecureCookies: boolean;
|
||||
/**
|
||||
* Whether to use a more minimal public Service Info page with static content.
|
||||
* Disables all stats pertaining to traffic, prompt/token usage, and queues.
|
||||
* The full info page will appear if you have signed in as an admin using the
|
||||
* configured ADMIN_KEY and go to /admin/service-info.
|
||||
**/
|
||||
staticServiceInfo?: boolean;
|
||||
/**
|
||||
* Trusted proxy hops. If you are deploying the server behind a reverse proxy
|
||||
* (Nginx, Cloudflare Tunnel, AWS WAF, etc.) the IP address of incoming
|
||||
* requests will be the IP address of the proxy, not the actual user.
|
||||
*
|
||||
* Depending on your hosting configuration, there may be multiple proxies/load
|
||||
* balancers between your server and the user. Each one will append the
|
||||
* incoming IP address to the `X-Forwarded-For` header. The user's real IP
|
||||
* address will be the first one in the list, assuming the header has not been
|
||||
* tampered with. Setting this value correctly ensures that the server doesn't
|
||||
* trust values in `X-Forwarded-For` not added by trusted proxies.
|
||||
*
|
||||
* In order for the server to determine the user's real IP address, you need
|
||||
* to tell it how many proxies are between the user and the server so it can
|
||||
* select the correct IP address from the `X-Forwarded-For` header.
|
||||
*
|
||||
* *WARNING:* If you set it incorrectly, the proxy will either record the
|
||||
* wrong IP address, or it will be possible for users to spoof their IP
|
||||
* addresses and bypass rate limiting. Check the request logs to see what
|
||||
* incoming X-Forwarded-For values look like.
|
||||
*
|
||||
* Examples:
|
||||
* - X-Forwarded-For: "34.1.1.1, 172.1.1.1, 10.1.1.1" => trustedProxies: 3
|
||||
* - X-Forwarded-For: "34.1.1.1" => trustedProxies: 1
|
||||
* - no X-Forwarded-For header => trustedProxies: 0 (the actual IP of the incoming request will be used)
|
||||
*
|
||||
* As of 2024/01/08:
|
||||
* For HuggingFace or Cloudflare Tunnel, use 1.
|
||||
* For Render, use 3.
|
||||
* For deployments not behind a load balancer, use 0.
|
||||
*
|
||||
* You should double check against your actual request logs to be sure.
|
||||
*
|
||||
* Defaults to 1, as most deployments are on HuggingFace or Cloudflare Tunnel.
|
||||
*/
|
||||
trustedProxies?: number;
|
||||
/**
|
||||
* Whether to allow OpenAI tool usage. The proxy doesn't impelment any
|
||||
* support for tools/function calling but can pass requests and responses as
|
||||
* is. Note that the proxy also cannot accurately track quota usage for
|
||||
* requests involving tools, so you must opt in to this feature at your own
|
||||
* risk.
|
||||
*/
|
||||
allowOpenAIToolUsage?: boolean;
|
||||
/**
|
||||
* Which services will accept prompts containing images, for use with
|
||||
* multimodal models. Users with `special` role are exempt from this
|
||||
* restriction.
|
||||
*
|
||||
* Do not enable this feature for untrusted users, as malicious users could
|
||||
* send images which violate your provider's terms of service or local laws.
|
||||
*
|
||||
* Defaults to no services, meaning image prompts are disabled. Use a comma-
|
||||
* separated list. Available services are:
|
||||
* openai,anthropic,google-ai,mistral-ai,aws,gcp,azure,xai
|
||||
*/
|
||||
allowedVisionServices: LLMService[];
|
||||
/**
|
||||
* Allows overriding the default proxy endpoint route. Defaults to /proxy.
|
||||
* A leading slash is required.
|
||||
*/
|
||||
proxyEndpointRoute: string;
|
||||
/**
|
||||
* If set, only requests from these IP addresses will be permitted to use the
|
||||
* admin API and UI. Provide a comma-separated list of IP addresses or CIDR
|
||||
* ranges. If not set, the admin API and UI will be open to all requests.
|
||||
*/
|
||||
adminWhitelist: string[];
|
||||
/**
|
||||
* If set, requests from these IP addresses will be blocked from using the
|
||||
* application. Provide a comma-separated list of IP addresses or CIDR ranges.
|
||||
* If not set, no IP addresses will be blocked.
|
||||
*
|
||||
* Takes precedence over the adminWhitelist.
|
||||
*/
|
||||
ipBlacklist: string[];
|
||||
/**
|
||||
* Whether to enable country-based blocking. If enabled, requests from
|
||||
* countries listed in blockedCountries will be rejected.
|
||||
*
|
||||
* Uses ipinfo.io API to determine the country of incoming requests.
|
||||
* Requests are cached for 1 hour to reduce API calls.
|
||||
*
|
||||
* Defaults to false.
|
||||
*/
|
||||
enableCountryBlocking: boolean;
|
||||
/**
|
||||
* Comma-separated list of ISO 3166-1 alpha-2 country codes to block.
|
||||
* Examples: "GB,CN,RU" to block United Kingdom, China, and Russia.
|
||||
*
|
||||
* Only effective if enableCountryBlocking is true.
|
||||
* Country codes are case-insensitive.
|
||||
*
|
||||
* If not set or empty, no countries will be blocked.
|
||||
* Cannot be used together with allowedCountries.
|
||||
*/
|
||||
blockedCountries: string[];
|
||||
/**
|
||||
* Comma-separated list of ISO 3166-1 alpha-2 country codes to allow.
|
||||
* Examples: "CN,US" to only allow China and United States, blocking all others.
|
||||
*
|
||||
* Only effective if enableCountryBlocking is true.
|
||||
* Country codes are case-insensitive.
|
||||
*
|
||||
* If not set or empty, all countries are allowed (unless blocked by blockedCountries).
|
||||
* Cannot be used together with blockedCountries - if both are set, allowedCountries takes precedence.
|
||||
*/
|
||||
allowedCountries: string[];
|
||||
/**
|
||||
* Optional API token for ipinfo.io to increase rate limits.
|
||||
* Without a token, you get 50,000 requests per month.
|
||||
* With a token, you get higher limits based on your plan.
|
||||
*
|
||||
* If not set, the free tier will be used.
|
||||
*/
|
||||
ipinfoToken?: string;
|
||||
/**
|
||||
* If set, pushes requests further back into the queue according to their
|
||||
* token costs by factor*tokens*milliseconds (or more intuitively
|
||||
* factor*thousands_of_tokens*seconds).
|
||||
* Accepts floats.
|
||||
*/
|
||||
tokensPunishmentFactor: number;
|
||||
/**
|
||||
* Configuration for HTTP requests made by the proxy to other servers, such
|
||||
* as when checking keys or forwarding users' requests to external services.
|
||||
* If not set, all requests will be made using the default agent.
|
||||
*
|
||||
* If set, the proxy may make requests to other servers using the specified
|
||||
* settings. This is useful if you wish to route users' requests through
|
||||
* another proxy or VPN, or if you have multiple network interfaces and want
|
||||
* to use a specific one for outgoing requests.
|
||||
*/
|
||||
httpAgent?: {
|
||||
/**
|
||||
* The name of the network interface to use. The first external IPv4 address
|
||||
* belonging to this interface will be used for outgoing requests.
|
||||
*/
|
||||
interface?: string;
|
||||
/**
|
||||
* The URL of a proxy server to use. Supports SOCKS4, SOCKS5, HTTP, and
|
||||
* HTTPS. If not set, the proxy will be made using the default agent.
|
||||
* - SOCKS4: `socks4://some-socks-proxy.com:9050`
|
||||
* - SOCKS5: `socks5://username:password@some-socks-proxy.com:9050`
|
||||
* - HTTP: `http://proxy-server-over-tcp.com:3128`
|
||||
* - HTTPS: `https://proxy-server-over-tls.com:3129`
|
||||
*
|
||||
* **Note:** If your proxy server issues a certificate, you may need to set
|
||||
* `NODE_EXTRA_CA_CERTS` to the path to your certificate, otherwise this
|
||||
* application will reject TLS connections.
|
||||
*/
|
||||
proxyUrl?: string;
|
||||
};
|
||||
/** URL for the image on the login page. Defaults to empty string (no image). */
|
||||
loginImageUrl?: string;
|
||||
/** Whether to enable the token-based login page for the service info page. Defaults to true. */
|
||||
enableInfoPageLogin?: boolean;
|
||||
/** Authentication mode for the service info page. (token | password) */
|
||||
serviceInfoAuthMode: "token" | "password";
|
||||
/** Password for the service info page if serviceInfoAuthMode is 'password'. */
|
||||
serviceInfoPassword?: string;
|
||||
};
|
||||
|
||||
// To change configs, create a file called .env in the root directory.
|
||||
// See .env.example for an example.
|
||||
export const config: Config = {
|
||||
port: getEnvWithDefault("PORT", 7860),
|
||||
bindAddress: getEnvWithDefault("BIND_ADDRESS", "0.0.0.0"),
|
||||
openaiKey: getEnvWithDefault("OPENAI_KEY", ""),
|
||||
anthropicKey: getEnvWithDefault("ANTHROPIC_KEY", ""),
|
||||
qwenKey: getEnvWithDefault("QWEN_KEY", ""),
|
||||
glmKey: getEnvWithDefault("GLM_KEY", ""),
|
||||
googleAIKey: getEnvWithDefault("GOOGLE_AI_KEY", ""),
|
||||
allowedExpModels: getEnvWithDefault("ALLOWED_EXP_MODELS", ""),
|
||||
mistralAIKey: getEnvWithDefault("MISTRAL_AI_KEY", ""),
|
||||
deepseekKey: getEnvWithDefault("DEEPSEEK_KEY", ""),
|
||||
xaiKey: getEnvWithDefault("XAI_KEY", ""),
|
||||
cohereKey: getEnvWithDefault("COHERE_KEY", ""),
|
||||
moonshotKey: getEnvWithDefault("MOONSHOT_KEY", ""),
|
||||
awsCredentials: getEnvWithDefault("AWS_CREDENTIALS", ""),
|
||||
gcpCredentials: getEnvWithDefault("GCP_CREDENTIALS", ""),
|
||||
azureCredentials: getEnvWithDefault("AZURE_CREDENTIALS", ""),
|
||||
proxyKey: getEnvWithDefault("PROXY_KEY", ""),
|
||||
adminKey: getEnvWithDefault("ADMIN_KEY", ""),
|
||||
sqliteDataPath: getEnvWithDefault(
|
||||
"SQLITE_DATA_PATH",
|
||||
path.join(DATA_DIR, "database.sqlite")
|
||||
),
|
||||
eventLogging: getEnvWithDefault("EVENT_LOGGING", false),
|
||||
eventLoggingTrim: getEnvWithDefault("EVENT_LOGGING_TRIM", 5),
|
||||
gatekeeper: getEnvWithDefault("GATEKEEPER", "none"),
|
||||
gatekeeperStore: getEnvWithDefault("GATEKEEPER_STORE", "memory") as Config["gatekeeperStore"],
|
||||
sqliteUserStorePath: getEnvWithDefault(
|
||||
"SQLITE_USER_STORE_PATH",
|
||||
path.join(DATA_DIR, "user-store.sqlite")
|
||||
),
|
||||
maxIpsPerUser: getEnvWithDefault("MAX_IPS_PER_USER", 0),
|
||||
maxIpsAutoBan: getEnvWithDefault("MAX_IPS_AUTO_BAN", false),
|
||||
captchaMode: getEnvWithDefault("CAPTCHA_MODE", "none"),
|
||||
powTokenHours: getEnvWithDefault("POW_TOKEN_HOURS", 24),
|
||||
powTokenMaxIps: getEnvWithDefault("POW_TOKEN_MAX_IPS", 2),
|
||||
powDifficultyLevel: getEnvWithDefault("POW_DIFFICULTY_LEVEL", "low"),
|
||||
powChallengeTimeout: getEnvWithDefault("POW_CHALLENGE_TIMEOUT", 30),
|
||||
powTokenPurgeHours: getEnvWithDefault("POW_TOKEN_PURGE_HOURS", 48),
|
||||
firebaseRtdbUrl: getEnvWithDefault("FIREBASE_RTDB_URL", undefined),
|
||||
firebaseKey: getEnvWithDefault("FIREBASE_KEY", undefined),
|
||||
textModelRateLimit: getEnvWithDefault("TEXT_MODEL_RATE_LIMIT", 4),
|
||||
imageModelRateLimit: getEnvWithDefault("IMAGE_MODEL_RATE_LIMIT", 4),
|
||||
maxContextTokensOpenAI: getEnvWithDefault("MAX_CONTEXT_TOKENS_OPENAI", 32768),
|
||||
maxContextTokensAnthropic: getEnvWithDefault(
|
||||
"MAX_CONTEXT_TOKENS_ANTHROPIC",
|
||||
32768
|
||||
),
|
||||
maxOutputTokensOpenAI: getEnvWithDefault(
|
||||
["MAX_OUTPUT_TOKENS_OPENAI", "MAX_OUTPUT_TOKENS"],
|
||||
1024
|
||||
),
|
||||
maxOutputTokensAnthropic: getEnvWithDefault(
|
||||
["MAX_OUTPUT_TOKENS_ANTHROPIC", "MAX_OUTPUT_TOKENS"],
|
||||
1024
|
||||
),
|
||||
allowedModelFamilies: getEnvWithDefault(
|
||||
"ALLOWED_MODEL_FAMILIES",
|
||||
getDefaultModelFamilies()
|
||||
),
|
||||
rejectPhrases: parseCsv(getEnvWithDefault("REJECT_PHRASES", "")),
|
||||
rejectMessage: getEnvWithDefault(
|
||||
"REJECT_MESSAGE",
|
||||
"This content violates /aicg/'s acceptable use policy."
|
||||
),
|
||||
logLevel: getEnvWithDefault("LOG_LEVEL", "info"),
|
||||
checkKeys: getEnvWithDefault("CHECK_KEYS", !isDev),
|
||||
showTokenCosts: getEnvWithDefault("SHOW_TOKEN_COSTS", false),
|
||||
allowAwsLogging: getEnvWithDefault("ALLOW_AWS_LOGGING", false),
|
||||
promptLogging: getEnvWithDefault("PROMPT_LOGGING", false),
|
||||
promptLoggingBackend: getEnvWithDefault("PROMPT_LOGGING_BACKEND", undefined),
|
||||
promptLoggingFilePrefix: getEnvWithDefault(
|
||||
"PROMPT_LOGGING_FILE_PREFIX",
|
||||
"prompt-logs"
|
||||
),
|
||||
googleSheetsKey: getEnvWithDefault("GOOGLE_SHEETS_KEY", undefined),
|
||||
googleSheetsSpreadsheetId: getEnvWithDefault(
|
||||
"GOOGLE_SHEETS_SPREADSHEET_ID",
|
||||
undefined
|
||||
),
|
||||
blockedOrigins: getEnvWithDefault("BLOCKED_ORIGINS", undefined),
|
||||
blockMessage: getEnvWithDefault(
|
||||
"BLOCK_MESSAGE",
|
||||
"You must be over the age of majority in your country to use this service."
|
||||
),
|
||||
blockRedirect: getEnvWithDefault("BLOCK_REDIRECT", "https://www.9gag.com"),
|
||||
tokenQuota: MODEL_FAMILIES.reduce(
|
||||
(acc, family: ModelFamily) => {
|
||||
acc[family] = getEnvWithDefault(
|
||||
`TOKEN_QUOTA_${family.toUpperCase().replace(/-/g, "_")}`,
|
||||
0
|
||||
) as number;
|
||||
return acc;
|
||||
},
|
||||
{} as { [key in ModelFamily]: number }
|
||||
),
|
||||
quotaRefreshPeriod: getEnvWithDefault("QUOTA_REFRESH_PERIOD", undefined),
|
||||
allowNicknameChanges: getEnvWithDefault("ALLOW_NICKNAME_CHANGES", true),
|
||||
showRecentImages: getEnvWithDefault("SHOW_RECENT_IMAGES", true),
|
||||
useInsecureCookies: getEnvWithDefault("USE_INSECURE_COOKIES", isDev),
|
||||
staticServiceInfo: getEnvWithDefault("STATIC_SERVICE_INFO", false),
|
||||
trustedProxies: getEnvWithDefault("TRUSTED_PROXIES", 1),
|
||||
allowOpenAIToolUsage: getEnvWithDefault("ALLOW_OPENAI_TOOL_USAGE", false),
|
||||
allowedVisionServices: parseCsv(
|
||||
getEnvWithDefault("ALLOWED_VISION_SERVICES", "")
|
||||
) as LLMService[],
|
||||
proxyEndpointRoute: getEnvWithDefault("PROXY_ENDPOINT_ROUTE", "/proxy"),
|
||||
adminWhitelist: parseCsv(
|
||||
getEnvWithDefault("ADMIN_WHITELIST", "0.0.0.0/0,::/0")
|
||||
),
|
||||
ipBlacklist: parseCsv(getEnvWithDefault("IP_BLACKLIST", "")),
|
||||
tokensPunishmentFactor: getEnvWithDefault("TOKENS_PUNISHMENT_FACTOR", 0.0),
|
||||
httpAgent: {
|
||||
interface: getEnvWithDefault("HTTP_AGENT_INTERFACE", undefined),
|
||||
proxyUrl: getEnvWithDefault("HTTP_AGENT_PROXY_URL", undefined),
|
||||
},
|
||||
loginImageUrl: getEnvWithDefault("LOGIN_IMAGE_URL", ""),
|
||||
enableInfoPageLogin: getEnvWithDefault("ENABLE_INFO_PAGE_LOGIN", true),
|
||||
serviceInfoAuthMode: getEnvWithDefault("SERVICE_INFO_AUTH_MODE", "token") as Config["serviceInfoAuthMode"],
|
||||
serviceInfoPassword: getEnvWithDefault("SERVICE_INFO_PASSWORD", undefined),
|
||||
enableCountryBlocking: getEnvWithDefault("ENABLE_COUNTRY_BLOCKING", false),
|
||||
blockedCountries: parseCsv(getEnvWithDefault("BLOCKED_COUNTRIES", "")),
|
||||
allowedCountries: parseCsv(getEnvWithDefault("ALLOWED_COUNTRIES", "")),
|
||||
ipinfoToken: getEnvWithDefault("IPINFO_TOKEN", undefined),
|
||||
} as const;
|
||||
|
||||
function generateSigningKey() {
|
||||
if (process.env.COOKIE_SECRET !== undefined) {
|
||||
// legacy, replaced by SIGNING_KEY
|
||||
return process.env.COOKIE_SECRET;
|
||||
} else if (process.env.SIGNING_KEY !== undefined) {
|
||||
return process.env.SIGNING_KEY;
|
||||
}
|
||||
|
||||
const secrets = [
|
||||
config.adminKey,
|
||||
config.openaiKey,
|
||||
config.anthropicKey,
|
||||
config.googleAIKey,
|
||||
config.mistralAIKey,
|
||||
config.deepseekKey,
|
||||
config.xaiKey,
|
||||
config.cohereKey,
|
||||
config.qwenKey,
|
||||
config.glmKey,
|
||||
config.moonshotKey,
|
||||
config.awsCredentials,
|
||||
config.gcpCredentials,
|
||||
config.azureCredentials,
|
||||
];
|
||||
if (secrets.filter((s) => s).length === 0) {
|
||||
startupLogger.warn(
|
||||
"No SIGNING_KEY or secrets are set. All sessions, cookies, and proofs of work will be invalidated on restart."
|
||||
);
|
||||
return crypto.randomBytes(32).toString("hex");
|
||||
}
|
||||
|
||||
startupLogger.info("No SIGNING_KEY set; one will be generated from secrets.");
|
||||
startupLogger.info(
|
||||
"It's recommended to set SIGNING_KEY explicitly to ensure users' sessions and cookies always persist across restarts."
|
||||
);
|
||||
const seed = secrets.map((s) => s || "n/a").join("");
|
||||
return crypto.createHash("sha256").update(seed).digest("hex");
|
||||
}
|
||||
|
||||
const signingKey = generateSigningKey();
|
||||
export const SECRET_SIGNING_KEY = signingKey;
|
||||
|
||||
export async function assertConfigIsValid() {
|
||||
if (process.env.MODEL_RATE_LIMIT !== undefined) {
|
||||
const limit =
|
||||
parseInt(process.env.MODEL_RATE_LIMIT, 10) || config.textModelRateLimit;
|
||||
|
||||
config.textModelRateLimit = limit;
|
||||
config.imageModelRateLimit = Math.max(Math.floor(limit / 2), 1);
|
||||
|
||||
startupLogger.warn(
|
||||
{ textLimit: limit, imageLimit: config.imageModelRateLimit },
|
||||
"MODEL_RATE_LIMIT is deprecated. Use TEXT_MODEL_RATE_LIMIT and IMAGE_MODEL_RATE_LIMIT instead."
|
||||
);
|
||||
}
|
||||
|
||||
if (process.env.ALLOW_IMAGE_PROMPTS === "true") {
|
||||
const hasAllowedServices = config.allowedVisionServices.length > 0;
|
||||
if (!hasAllowedServices) {
|
||||
config.allowedVisionServices = ["openai", "anthropic"];
|
||||
startupLogger.warn(
|
||||
{ allowedVisionServices: config.allowedVisionServices },
|
||||
"ALLOW_IMAGE_PROMPTS is deprecated. Use ALLOWED_VISION_SERVICES instead."
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
if (config.promptLogging && !config.promptLoggingBackend) {
|
||||
throw new Error(
|
||||
"Prompt logging is enabled but no backend is configured. Set PROMPT_LOGGING_BACKEND to 'google_sheets' or 'file'."
|
||||
);
|
||||
}
|
||||
|
||||
if (!["none", "proxy_key", "user_token"].includes(config.gatekeeper)) {
|
||||
throw new Error(
|
||||
`Invalid gatekeeper mode: ${config.gatekeeper}. Must be one of: none, proxy_key, user_token.`
|
||||
);
|
||||
}
|
||||
|
||||
if (config.gatekeeper === "user_token" && !config.adminKey) {
|
||||
throw new Error(
|
||||
"`user_token` gatekeeper mode requires an `ADMIN_KEY` to be set."
|
||||
);
|
||||
}
|
||||
|
||||
if (
|
||||
config.captchaMode === "proof_of_work" &&
|
||||
config.gatekeeper !== "user_token"
|
||||
) {
|
||||
throw new Error(
|
||||
"Captcha mode 'proof_of_work' requires gatekeeper mode 'user_token'."
|
||||
);
|
||||
}
|
||||
|
||||
if (config.captchaMode === "proof_of_work") {
|
||||
const val = config.powDifficultyLevel;
|
||||
const isDifficulty =
|
||||
typeof val === "string" &&
|
||||
["low", "medium", "high", "extreme"].includes(val);
|
||||
const isIterations =
|
||||
typeof val === "number" && Number.isInteger(val) && val > 0;
|
||||
if (!isDifficulty && !isIterations) {
|
||||
throw new Error(
|
||||
"Invalid POW_DIFFICULTY_LEVEL. Must be one of: low, medium, high, extreme, or a positive integer."
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
if (config.gatekeeper === "proxy_key" && !config.proxyKey) {
|
||||
throw new Error(
|
||||
"`proxy_key` gatekeeper mode requires a `PROXY_KEY` to be set."
|
||||
);
|
||||
}
|
||||
|
||||
if (
|
||||
config.gatekeeperStore === "firebase_rtdb" &&
|
||||
(!config.firebaseKey || !config.firebaseRtdbUrl)
|
||||
) {
|
||||
throw new Error(
|
||||
"Firebase RTDB store requires `FIREBASE_KEY` and `FIREBASE_RTDB_URL` to be set."
|
||||
);
|
||||
}
|
||||
|
||||
if (config.gatekeeperStore === "sqlite" && !config.sqliteUserStorePath) {
|
||||
throw new Error(
|
||||
"SQLite user store requires `SQLITE_USER_STORE_PATH` to be set."
|
||||
);
|
||||
}
|
||||
|
||||
if (Object.values(config.httpAgent || {}).filter(Boolean).length === 0) {
|
||||
delete config.httpAgent;
|
||||
} else if (config.httpAgent) {
|
||||
if (config.httpAgent.interface && config.httpAgent.proxyUrl) {
|
||||
throw new Error(
|
||||
"Cannot set both `HTTP_AGENT_INTERFACE` and `HTTP_AGENT_PROXY_URL`."
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
if (config.enableInfoPageLogin) {
|
||||
if (!["token", "password"].includes(config.serviceInfoAuthMode)) {
|
||||
throw new Error(
|
||||
`Invalid SERVICE_INFO_AUTH_MODE: ${config.serviceInfoAuthMode}. Must be 'token' or 'password'.`
|
||||
);
|
||||
}
|
||||
if (config.serviceInfoAuthMode === "password" && !config.serviceInfoPassword) {
|
||||
throw new Error(
|
||||
"SERVICE_INFO_AUTH_MODE is 'password' but SERVICE_INFO_PASSWORD is not set."
|
||||
);
|
||||
}
|
||||
// If service info login is token-based, gatekeeper must be 'user_token' mode for getUser() to be effective.
|
||||
if (config.serviceInfoAuthMode === "token" && config.gatekeeper !== "user_token") {
|
||||
throw new Error(
|
||||
"SERVICE_INFO_AUTH_MODE is 'token' for info page login, but GATEKEEPER is not 'user_token'. User token authentication will not work."
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
// Ensure forks which add new secret-like config keys don't unwittingly expose
|
||||
// them to users.
|
||||
for (const key of getKeys(config)) {
|
||||
const maybeSensitive = ["key", "credentials", "secret", "password"].some(
|
||||
(sensitive) =>
|
||||
key.toLowerCase().includes(sensitive) && !["checkKeys"].includes(key)
|
||||
);
|
||||
const secured = new Set([...SENSITIVE_KEYS, ...OMITTED_KEYS]);
|
||||
if (maybeSensitive && !secured.has(key))
|
||||
throw new Error(
|
||||
`Config key "${key}" may be sensitive but is exposed. Add it to SENSITIVE_KEYS or OMITTED_KEYS.`
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Config keys that are masked on the info page, but not hidden as their
|
||||
* presence may be relevant to the user due to privacy implications.
|
||||
*/
|
||||
export const SENSITIVE_KEYS: (keyof Config)[] = [
|
||||
"googleSheetsSpreadsheetId",
|
||||
"httpAgent",
|
||||
];
|
||||
|
||||
/**
|
||||
* Config keys that are not displayed on the info page at all, generally because
|
||||
* they are not relevant to the user or can be inferred from other config.
|
||||
*/
|
||||
export const OMITTED_KEYS = [
|
||||
"port",
|
||||
"bindAddress",
|
||||
"logLevel",
|
||||
"openaiKey",
|
||||
"anthropicKey",
|
||||
"googleAIKey",
|
||||
"deepseekKey",
|
||||
"xaiKey",
|
||||
"cohereKey",
|
||||
"qwenKey",
|
||||
"glmKey",
|
||||
"moonshotKey",
|
||||
"mistralAIKey",
|
||||
"awsCredentials",
|
||||
"gcpCredentials",
|
||||
"azureCredentials",
|
||||
"proxyKey",
|
||||
"adminKey",
|
||||
"rejectPhrases",
|
||||
"rejectMessage",
|
||||
"showTokenCosts",
|
||||
"promptLoggingFilePrefix",
|
||||
"googleSheetsKey",
|
||||
"firebaseKey",
|
||||
"firebaseRtdbUrl",
|
||||
"sqliteDataPath",
|
||||
"sqliteUserStorePath",
|
||||
"eventLogging",
|
||||
"eventLoggingTrim",
|
||||
"gatekeeperStore",
|
||||
"maxIpsPerUser",
|
||||
"blockedOrigins",
|
||||
"blockMessage",
|
||||
"blockRedirect",
|
||||
"allowNicknameChanges",
|
||||
"showRecentImages",
|
||||
"useInsecureCookies",
|
||||
"staticServiceInfo",
|
||||
"checkKeys",
|
||||
"allowedModelFamilies",
|
||||
"trustedProxies",
|
||||
"proxyEndpointRoute",
|
||||
"adminWhitelist",
|
||||
"ipBlacklist",
|
||||
"enableCountryBlocking",
|
||||
"blockedCountries",
|
||||
"allowedCountries",
|
||||
"ipinfoToken",
|
||||
"powTokenPurgeHours",
|
||||
"loginImageUrl",
|
||||
"enableInfoPageLogin",
|
||||
"serviceInfoPassword",
|
||||
] satisfies (keyof Config)[];
|
||||
type OmitKeys = (typeof OMITTED_KEYS)[number];
|
||||
|
||||
type Printable<T> = {
|
||||
[P in keyof T as Exclude<P, OmitKeys>]: T[P] extends object
|
||||
? Printable<T[P]>
|
||||
: string;
|
||||
};
|
||||
type PublicConfig = Printable<Config>;
|
||||
|
||||
const getKeys = Object.keys as <T extends object>(obj: T) => Array<keyof T>;
|
||||
|
||||
export function listConfig(obj: Config = config) {
|
||||
const result: Record<string, unknown> = {};
|
||||
for (const key of getKeys(obj)) {
|
||||
const value = obj[key]?.toString() || "";
|
||||
|
||||
const shouldMask = SENSITIVE_KEYS.includes(key);
|
||||
const shouldOmit =
|
||||
OMITTED_KEYS.includes(key as OmitKeys) ||
|
||||
value === "" ||
|
||||
value === "undefined";
|
||||
|
||||
if (shouldOmit) {
|
||||
continue;
|
||||
}
|
||||
|
||||
const validKey = key as keyof Printable<Config>;
|
||||
|
||||
if (value && shouldMask) {
|
||||
result[validKey] = "********";
|
||||
} else {
|
||||
result[validKey] = value;
|
||||
}
|
||||
|
||||
if (typeof obj[key] === "object" && !Array.isArray(obj[key])) {
|
||||
result[key] = listConfig(obj[key] as unknown as Config);
|
||||
}
|
||||
}
|
||||
return result as PublicConfig;
|
||||
}
|
||||
|
||||
/**
|
||||
* Tries to get a config value from one or more environment variables (in
|
||||
* order), falling back to a default value if none are set.
|
||||
*/
|
||||
function getEnvWithDefault<T>(env: string | string[], defaultValue: T): T {
|
||||
const value = Array.isArray(env)
|
||||
? env.map((e) => process.env[e]).find((v) => v !== undefined)
|
||||
: process.env[env];
|
||||
if (value === undefined) {
|
||||
return defaultValue;
|
||||
}
|
||||
try {
|
||||
if (
|
||||
[
|
||||
"OPENAI_KEY",
|
||||
"ANTHROPIC_KEY",
|
||||
"GOOGLE_AI_KEY",
|
||||
"AWS_CREDENTIALS",
|
||||
"GCP_CREDENTIALS",
|
||||
"AZURE_CREDENTIALS",
|
||||
"QWEN_KEY",
|
||||
].includes(String(env))
|
||||
) {
|
||||
return value as unknown as T;
|
||||
}
|
||||
|
||||
// Intended to be used for comma-delimited lists
|
||||
if (Array.isArray(defaultValue)) {
|
||||
return value.split(",").map((v) => v.trim()) as T;
|
||||
}
|
||||
|
||||
return JSON.parse(value) as T;
|
||||
} catch (err) {
|
||||
return value as unknown as T;
|
||||
}
|
||||
}
|
||||
|
||||
function parseCsv(val: string): string[] {
|
||||
if (!val) return [];
|
||||
|
||||
const regex = /(".*?"|[^",]+)(?=\s*,|\s*$)/g;
|
||||
const matches = val.match(regex) || [];
|
||||
return matches.map((item) => item.replace(/^"|"$/g, "").trim());
|
||||
}
|
||||
|
||||
function getDefaultModelFamilies(): ModelFamily[] {
|
||||
return MODEL_FAMILIES.filter(
|
||||
(f) => !f.includes("o1-pro") && !f.includes("o3-pro")
|
||||
) as ModelFamily[];
|
||||
}
|
||||
@@ -0,0 +1,404 @@
|
||||
/* ──────────────────────────────────────────────────────────────
|
||||
Login-gated info page
|
||||
drop-in replacement for src/info-page.ts
|
||||
──────────────────────────────────────────────────────────── */
|
||||
|
||||
import fs from "fs";
|
||||
import express, { Router, Request, Response } from "express";
|
||||
import showdown from "showdown";
|
||||
import { config } from "./config";
|
||||
import { buildInfo, ServiceInfo } from "./service-info";
|
||||
import { getLastNImages } from "./shared/file-storage/image-history";
|
||||
import { keyPool } from "./shared/key-management";
|
||||
import { MODEL_FAMILY_SERVICE, ModelFamily } from "./shared/models";
|
||||
import { withSession } from "./shared/with-session";
|
||||
import { injectCsrfToken, checkCsrfToken } from "./shared/inject-csrf";
|
||||
import { getUser } from "./shared/users/user-store";
|
||||
|
||||
/* ──────────────── TYPES: extend express-session ──────────── */
|
||||
declare module "express-session" {
|
||||
interface Session {
|
||||
infoPageAuthed?: boolean;
|
||||
}
|
||||
}
|
||||
|
||||
/* ──────────────── misc constants ─────────────────────────── */
|
||||
const INFO_PAGE_TTL = 2_000; // ms
|
||||
const LOGIN_ROUTE = "/";
|
||||
|
||||
const MODEL_FAMILY_FRIENDLY_NAME: { [f in ModelFamily]: string } = {
|
||||
qwen: "Qwen",
|
||||
glm: "GLM",
|
||||
cohere: "Cohere",
|
||||
deepseek: "Deepseek",
|
||||
xai: "Grok",
|
||||
moonshot: "Moonshot",
|
||||
turbo: "GPT-4o Mini / 3.5 Turbo",
|
||||
gpt4: "GPT-4",
|
||||
"gpt4-32k": "GPT-4 32k",
|
||||
"gpt4-turbo": "GPT-4 Turbo",
|
||||
gpt4o: "GPT-4o",
|
||||
gpt41: "GPT-4.1",
|
||||
"gpt41-mini": "GPT-4.1 Mini",
|
||||
"gpt41-nano": "GPT-4.1 Nano",
|
||||
gpt5: "GPT-5",
|
||||
"gpt5-mini": "GPT-5 Mini",
|
||||
"gpt5-nano": "GPT-5 Nano",
|
||||
"gpt5-chat-latest": "GPT-5 Chat Latest",
|
||||
gpt45: "GPT-4.5",
|
||||
o1: "OpenAI o1",
|
||||
"o1-mini": "OpenAI o1 mini",
|
||||
"o1-pro": "OpenAI o1 pro",
|
||||
"o3-pro": "OpenAI o3 pro",
|
||||
"o3-mini": "OpenAI o3 mini",
|
||||
"o3": "OpenAI o3",
|
||||
"o4-mini": "OpenAI o4 mini",
|
||||
"codex-mini": "OpenAI Codex Mini",
|
||||
"dall-e": "DALL-E",
|
||||
"gpt-image": "GPT Image",
|
||||
claude: "Claude (Sonnet)",
|
||||
"claude-opus": "Claude (Opus)",
|
||||
"gemini-flash": "Gemini Flash",
|
||||
"gemini-pro": "Gemini Pro",
|
||||
"gemini-ultra": "Gemini Ultra",
|
||||
"mistral-tiny": "Mistral 7B",
|
||||
"mistral-small": "Mistral Nemo",
|
||||
"mistral-medium": "Mistral Medium",
|
||||
"mistral-large": "Mistral Large",
|
||||
"aws-claude": "AWS Claude (Sonnet)",
|
||||
"aws-claude-opus": "AWS Claude (Opus)",
|
||||
"aws-mistral-tiny": "AWS Mistral 7B",
|
||||
"aws-mistral-small": "AWS Mistral Nemo",
|
||||
"aws-mistral-medium": "AWS Mistral Medium",
|
||||
"aws-mistral-large": "AWS Mistral Large",
|
||||
"gcp-claude": "GCP Claude (Sonnet)",
|
||||
"gcp-claude-opus": "GCP Claude (Opus)",
|
||||
"azure-turbo": "Azure GPT-3.5 Turbo",
|
||||
"azure-gpt4": "Azure GPT-4",
|
||||
"azure-gpt4-32k": "Azure GPT-4 32k",
|
||||
"azure-gpt4-turbo": "Azure GPT-4 Turbo",
|
||||
"azure-gpt4o": "Azure GPT-4o",
|
||||
"azure-gpt45": "Azure GPT-4.5",
|
||||
"azure-gpt41": "Azure GPT-4.1",
|
||||
"azure-gpt41-mini": "Azure GPT-4.1 Mini",
|
||||
"azure-gpt41-nano": "Azure GPT-4.1 Nano",
|
||||
"azure-gpt5": "Azure GPT-5",
|
||||
"azure-gpt5-mini": "Azure GPT-5 Mini",
|
||||
"azure-gpt5-nano": "Azure GPT-5 Nano",
|
||||
"azure-gpt5-chat-latest": "Azure GPT-5 Chat Latest",
|
||||
"azure-o1": "Azure o1",
|
||||
"azure-o1-mini": "Azure o1 mini",
|
||||
"azure-o1-pro": "Azure o1 pro",
|
||||
"azure-o3-pro": "Azure o3 pro",
|
||||
"azure-o3-mini": "Azure o3 mini",
|
||||
"azure-o3": "Azure o3",
|
||||
"azure-o4-mini": "Azure o4 mini",
|
||||
"azure-codex-mini": "Azure Codex Mini",
|
||||
"azure-dall-e": "Azure DALL-E",
|
||||
"azure-gpt-image": "Azure GPT Image",
|
||||
};
|
||||
|
||||
const converter = new showdown.Converter();
|
||||
|
||||
/* optional markdown greeting */
|
||||
const customGreeting = fs.existsSync("greeting.md")
|
||||
? `<div id="servergreeting">${fs.readFileSync("greeting.md", "utf8")}</div>`
|
||||
: "";
|
||||
|
||||
/* ──────────────── Login page ──────────────────────── */
|
||||
function renderLoginPage(csrf: string, error?: string) {
|
||||
const errBlock = error
|
||||
? `<div class="error-message">${escapeHtml(error)}</div>`
|
||||
: "";
|
||||
const pageTitle = getServerTitle();
|
||||
return `<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>${pageTitle} – Login</title>
|
||||
<style>
|
||||
body{font-family:Arial, sans-serif;display:flex;justify-content:center;
|
||||
align-items:center;height:100vh;margin:0;padding:20px;background:#f5f5f5;}
|
||||
.login-container{background:#fff;border-radius:8px;box-shadow:0 4px 8px rgba(0,0,0,.1);
|
||||
padding:30px;width:100%;max-width:400px;text-align:center;}
|
||||
.logo-image{max-width:200px;margin-bottom:20px;}
|
||||
.form-group{margin-bottom:20px;}
|
||||
input[type=text], input[type=password]{width:100%;padding:10px;border:1px solid #ddd;border-radius:4px;
|
||||
box-sizing:border-box;font-size:16px;}
|
||||
button{background:#4caf50;color:#fff;border:none;padding:12px 20px;border-radius:4px;
|
||||
cursor:pointer;font-size:16px;width:100%;}
|
||||
button:hover{background:#45a049;}
|
||||
.error-message{color:#f44336;margin-bottom:15px;}
|
||||
|
||||
@media (prefers-color-scheme: dark) {
|
||||
body { background: #2c2c2c; color: #e0e0e0; }
|
||||
.login-container { background: #383838; box-shadow: 0 4px 12px rgba(0,0,0,0.4); border: 1px solid #4a4a4a; }
|
||||
input[type=text], input[type=password] { background: #4a4a4a; color: #e0e0e0; border: 1px solid #5a5a5a; }
|
||||
input[type=text]::placeholder, input[type=password]::placeholder { color: #999; }
|
||||
button { background: #007bff; } /* Using a blue for dark mode button */
|
||||
button:hover { background: #0056b3; }
|
||||
.error-message { color: #ff8a80; } /* Lighter red for errors in dark mode */
|
||||
}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
<div class="login-container">
|
||||
${config.loginImageUrl ? `<img src="${config.loginImageUrl}" alt="Logo" class="logo-image">` : ''}
|
||||
${errBlock}
|
||||
<form method="POST" action="${LOGIN_ROUTE}">
|
||||
<div class="form-group">
|
||||
${config.serviceInfoAuthMode === "password"
|
||||
? `<input type="password" id="password" name="password" required placeholder="Service Password">`
|
||||
: `<input type="text" id="token" name="token" required placeholder="Your token">`}
|
||||
<input type="hidden" name="_csrf" value="${csrf}">
|
||||
</div>
|
||||
<button type="submit">Access Dashboard</button>
|
||||
</form>
|
||||
</div>
|
||||
</body>
|
||||
</html>`;
|
||||
}
|
||||
|
||||
/* ──────────────── login-required middleware ──────────────── */
|
||||
function requireLogin(
|
||||
req: Request,
|
||||
res: Response,
|
||||
next: express.NextFunction
|
||||
) {
|
||||
if (req.session?.infoPageAuthed) return next();
|
||||
return res.send(renderLoginPage(res.locals.csrfToken));
|
||||
}
|
||||
|
||||
/* ──────────────── INFO PAGE CACHING ──────────────────────── */
|
||||
let infoPageHtml: string | undefined;
|
||||
let infoPageLastUpdated = 0;
|
||||
|
||||
export function handleInfoPage(req: Request, res: Response) {
|
||||
if (infoPageLastUpdated + INFO_PAGE_TTL > Date.now()) {
|
||||
return res.send(infoPageHtml);
|
||||
}
|
||||
|
||||
const baseUrl =
|
||||
process.env.SPACE_ID && !req.get("host")?.includes("hf.space")
|
||||
? getExternalUrlForHuggingfaceSpaceId(process.env.SPACE_ID)
|
||||
: req.protocol + "://" + req.get("host");
|
||||
|
||||
const info = buildInfo(baseUrl + config.proxyEndpointRoute);
|
||||
infoPageHtml = renderPage(info);
|
||||
infoPageLastUpdated = Date.now();
|
||||
|
||||
res.send(infoPageHtml);
|
||||
}
|
||||
|
||||
/* ──────────────── RENDER FULL INFO PAGE ──────────────────── */
|
||||
export function renderPage(info: ServiceInfo) {
|
||||
const title = getServerTitle();
|
||||
const headerHtml = buildInfoPageHeader(info);
|
||||
|
||||
return `<!doctype html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8" />
|
||||
<meta name="robots" content="noindex" />
|
||||
<title>${title}</title>
|
||||
<link rel="stylesheet" href="/res/css/reset.css" />
|
||||
<link rel="stylesheet" href="/res/css/sakura.css" />
|
||||
<link rel="stylesheet" href="/res/css/sakura-dark.css"
|
||||
media="screen and (prefers-color-scheme: dark)" />
|
||||
<style>
|
||||
body{font-family:sans-serif;padding:1em;max-width:900px;margin:0;}
|
||||
.self-service-links{display:flex;justify-content:center;margin-bottom:1em;
|
||||
padding:0.5em;font-size:0.8em;}
|
||||
.self-service-links a{margin:0 0.5em;}
|
||||
</style>
|
||||
</head>
|
||||
<body>
|
||||
${headerHtml}
|
||||
<hr/>
|
||||
${getSelfServiceLinks()}
|
||||
<h2>Service Info</h2>
|
||||
<pre>${JSON.stringify(info, null, 2)}</pre>
|
||||
</body>
|
||||
</html>`;
|
||||
}
|
||||
|
||||
/* ──────────────── header & helper functions ──────────────── */
|
||||
/* (all copied verbatim from original file) */
|
||||
function buildInfoPageHeader(info: ServiceInfo) {
|
||||
const title = getServerTitle();
|
||||
let infoBody = `# ${title}`;
|
||||
|
||||
if (config.promptLogging) {
|
||||
infoBody += `\n## Prompt Logging Enabled
|
||||
This proxy keeps full logs of all prompts and AI responses. Prompt logs are anonymous and do not contain IP addresses or timestamps.
|
||||
|
||||
[You can see the type of data logged here, along with the rest of the code.](https://gitgud.io/khanon/oai-reverse-proxy/-/blob/main/src/shared/prompt-logging/index.ts).
|
||||
|
||||
**If you are uncomfortable with this, don't send prompts to this proxy!**`;
|
||||
}
|
||||
|
||||
if (config.staticServiceInfo) {
|
||||
return converter.makeHtml(infoBody + customGreeting);
|
||||
}
|
||||
|
||||
const waits: string[] = [];
|
||||
|
||||
for (const modelFamily of config.allowedModelFamilies) {
|
||||
const service = MODEL_FAMILY_SERVICE[modelFamily];
|
||||
|
||||
const hasKeys = keyPool.list().some(
|
||||
(k) => k.service === service && k.modelFamilies.includes(modelFamily)
|
||||
);
|
||||
|
||||
const wait = info[modelFamily]?.estimatedQueueTime;
|
||||
if (hasKeys && wait) {
|
||||
waits.push(
|
||||
`**${MODEL_FAMILY_FRIENDLY_NAME[modelFamily] || modelFamily}**: ${wait}`
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
infoBody += "\n\n" + waits.join(" / ");
|
||||
infoBody += customGreeting;
|
||||
infoBody += buildRecentImageSection();
|
||||
|
||||
return converter.makeHtml(infoBody);
|
||||
}
|
||||
|
||||
function getSelfServiceLinks() {
|
||||
if (config.gatekeeper !== "user_token") return "";
|
||||
const links = [["Check your user token", "/user/lookup"]];
|
||||
if (config.captchaMode !== "none") {
|
||||
links.unshift(["Request a user token", "/user/captcha"]);
|
||||
}
|
||||
return `<div class="self-service-links">${links
|
||||
.map(([t, l]) => `<a href="${l}">${t}</a>`)
|
||||
.join(" | ")}</div>`;
|
||||
}
|
||||
|
||||
function getServerTitle() {
|
||||
if (process.env.SERVER_TITLE) return process.env.SERVER_TITLE;
|
||||
if (process.env.SPACE_ID)
|
||||
return `${process.env.SPACE_AUTHOR_NAME} / ${process.env.SPACE_TITLE}`;
|
||||
if (process.env.RENDER)
|
||||
return `Render / ${process.env.RENDER_SERVICE_NAME}`;
|
||||
return "Tunnel";
|
||||
}
|
||||
|
||||
function buildRecentImageSection() {
|
||||
const imageModels: ModelFamily[] = [
|
||||
"azure-dall-e",
|
||||
"dall-e",
|
||||
"gpt-image",
|
||||
"azure-gpt-image",
|
||||
];
|
||||
// Condition 1: Is the feature enabled via config?
|
||||
// Condition 2: Is at least one relevant image model family allowed in config?
|
||||
if (
|
||||
!config.showRecentImages ||
|
||||
imageModels.every((f) => !config.allowedModelFamilies.includes(f))
|
||||
) {
|
||||
return ""; // Exit if feature is disabled or no relevant models are allowed
|
||||
}
|
||||
|
||||
// Condition 3: Are there any actual images to display?
|
||||
const recentImages = getLastNImages(12).reverse();
|
||||
if (recentImages.length === 0) {
|
||||
// If the feature is enabled and models are allowed, but no images exist,
|
||||
// do not render the section, including its title.
|
||||
return "";
|
||||
}
|
||||
|
||||
// If all conditions pass (feature enabled, models allowed, images exist), build and return the HTML
|
||||
let html = `<h2>Recent Image Generations</h2>`;
|
||||
html += `<div style="display:flex;flex-wrap:wrap;" id="recent-images">`;
|
||||
for (const { url, prompt } of recentImages) {
|
||||
const thumbUrl = url.replace(/\.png$/, "_t.jpg");
|
||||
const escapedPrompt = escapeHtml(prompt);
|
||||
html += `<div style="margin:0.5em" class="recent-image">
|
||||
<a href="${url}" target="_blank"><img src="${thumbUrl}" title="${escapedPrompt}"
|
||||
alt="${escapedPrompt}" style="max-width:150px;max-height:150px;"/></a></div>`;
|
||||
}
|
||||
html += `</div><p style="clear:both;text-align:center;">
|
||||
<a href="/user/image-history">View all recent images</a></p>`;
|
||||
return html;
|
||||
}
|
||||
|
||||
function escapeHtml(unsafe: string) {
|
||||
return unsafe
|
||||
.replace(/&/g, "&")
|
||||
.replace(/</g, "<")
|
||||
.replace(/>/g, ">")
|
||||
.replace(/"/g, """)
|
||||
.replace(/'/g, "'")
|
||||
.replace(/\[/g, "[")
|
||||
.replace(/]/g, "]");
|
||||
}
|
||||
|
||||
|
||||
function getExternalUrlForHuggingfaceSpaceId(spaceId: string) {
|
||||
try {
|
||||
const [u, s] = spaceId.split("/");
|
||||
return `https://${u}-${s.replace(/_/g, "-")}.hf.space`;
|
||||
} catch {
|
||||
return "";
|
||||
}
|
||||
}
|
||||
|
||||
/* ──────────────── ROUTER ─────────────────────────────────── */
|
||||
const infoPageRouter = Router();
|
||||
|
||||
infoPageRouter.use(
|
||||
express.json({ limit: "1mb" }),
|
||||
express.urlencoded({ extended: true, limit: "1mb" }),
|
||||
withSession,
|
||||
injectCsrfToken,
|
||||
checkCsrfToken
|
||||
);
|
||||
|
||||
/* login attempt */
|
||||
infoPageRouter.post(LOGIN_ROUTE, (req, res) => {
|
||||
if (config.serviceInfoAuthMode === "password") {
|
||||
const password = (req.body.password || "").trim();
|
||||
// Simple string comparison; for production, consider a timing-safe comparison library
|
||||
if (config.serviceInfoPassword && password === config.serviceInfoPassword) {
|
||||
req.session!.infoPageAuthed = true;
|
||||
return res.redirect("/");
|
||||
} else {
|
||||
return res
|
||||
.status(401)
|
||||
.send(renderLoginPage(res.locals.csrfToken, "Invalid password. Please try again."));
|
||||
}
|
||||
} else {
|
||||
// Token-based authentication (using any valid user token)
|
||||
const token = (req.body.token || "").trim();
|
||||
const user = getUser(token); // returns undefined if invalid
|
||||
|
||||
if (user && !user.disabledAt) {
|
||||
// Only allow access if user exists AND is not disabled
|
||||
req.session!.infoPageAuthed = true;
|
||||
return res.redirect("/");
|
||||
} else if (user && user.disabledAt) {
|
||||
// User exists but is disabled
|
||||
const reason = user.disabledReason || "Your account has been disabled";
|
||||
return res
|
||||
.status(401)
|
||||
.send(renderLoginPage(res.locals.csrfToken, `Access denied: ${reason}`));
|
||||
} else {
|
||||
// User doesn't exist
|
||||
return res
|
||||
.status(401)
|
||||
.send(renderLoginPage(res.locals.csrfToken, "Invalid token. Please try again."));
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
/* GET / – either login form or info page */
|
||||
if (config.enableInfoPageLogin) {
|
||||
infoPageRouter.get(LOGIN_ROUTE, requireLogin, handleInfoPage);
|
||||
} else {
|
||||
infoPageRouter.get(LOGIN_ROUTE, handleInfoPage);
|
||||
}
|
||||
|
||||
/* ─── Removed the public /status route : simply not added ─── */
|
||||
|
||||
export { infoPageRouter };
|
||||
@@ -0,0 +1,20 @@
|
||||
import pino from "pino";
|
||||
import { config } from "./config";
|
||||
|
||||
const transport =
|
||||
process.env.NODE_ENV === "production"
|
||||
? undefined
|
||||
: {
|
||||
target: "pino-pretty",
|
||||
options: {
|
||||
singleLine: true,
|
||||
messageFormat: "{if module}\x1b[90m[{module}] \x1b[39m{end}{msg}",
|
||||
ignore: "module",
|
||||
},
|
||||
};
|
||||
|
||||
export const logger = pino({
|
||||
level: config.logLevel,
|
||||
base: { pid: process.pid, module: "server" },
|
||||
transport,
|
||||
});
|
||||
@@ -0,0 +1,9 @@
|
||||
import { NextFunction, Request, Response } from "express";
|
||||
|
||||
export function addV1(req: Request, res: Response, next: NextFunction) {
|
||||
// Clients don't consistently use the /v1 prefix so we'll add it for them.
|
||||
if (!req.path.startsWith("/v1/") && !req.path.match(/^\/(v1alpha|v1beta)\//)) {
|
||||
req.url = `/v1${req.url}`;
|
||||
}
|
||||
next();
|
||||
}
|
||||
@@ -0,0 +1,394 @@
|
||||
import { Request, RequestHandler, Router } from "express";
|
||||
import { config } from "../config";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import {
|
||||
addKey,
|
||||
createPreprocessorMiddleware,
|
||||
finalizeBody,
|
||||
} from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import { ProxyReqManager } from "./middleware/request/proxy-req-manager";
|
||||
import { claudeModels } from "../shared/claude-models";
|
||||
import { validateClaude41OpusParameters } from "../shared/claude-4-1-validation";
|
||||
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
const getModelsResponse = () => {
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
if (!config.anthropicKey) return { object: "list", data: [], has_more: false, first_id: null, last_id: null };
|
||||
|
||||
const date = new Date()
|
||||
const models = claudeModels.map(model => ({
|
||||
// Common
|
||||
id: model.anthropicId,
|
||||
owned_by: "anthropic",
|
||||
// Anthropic
|
||||
type: "model",
|
||||
display_name: model.displayName,
|
||||
created_at: date.toISOString(),
|
||||
// OpenAI
|
||||
object: "model",
|
||||
created: date.getTime(),
|
||||
}));
|
||||
|
||||
modelsCache = {
|
||||
// Common
|
||||
object: "list",
|
||||
data: models,
|
||||
// Anthropic
|
||||
has_more: false,
|
||||
first_id: models[0]?.id,
|
||||
last_id: models[models.length - 1]?.id,
|
||||
};
|
||||
modelsCacheTime = date.getTime();
|
||||
|
||||
return modelsCache;
|
||||
};
|
||||
|
||||
const handleModelRequest: RequestHandler = (_req, res) => {
|
||||
res.status(200).json(getModelsResponse());
|
||||
};
|
||||
|
||||
const anthropicBlockingResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
switch (`${req.inboundApi}<-${req.outboundApi}`) {
|
||||
case "openai<-anthropic-text":
|
||||
req.log.info("Transforming Anthropic Text back to OpenAI format");
|
||||
newBody = transformAnthropicTextResponseToOpenAI(body, req);
|
||||
break;
|
||||
case "openai<-anthropic-chat":
|
||||
req.log.info("Transforming Anthropic Chat back to OpenAI format");
|
||||
newBody = transformAnthropicChatResponseToOpenAI(body);
|
||||
break;
|
||||
case "anthropic-text<-anthropic-chat":
|
||||
req.log.info("Transforming Anthropic Chat back to Anthropic chat format");
|
||||
newBody = transformAnthropicChatResponseToAnthropicText(body);
|
||||
break;
|
||||
}
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
function flattenChatResponse(
|
||||
content: { type: string; text: string }[]
|
||||
): string {
|
||||
return content
|
||||
.map((part: { type: string; text: string }) =>
|
||||
part.type === "text" ? part.text : ""
|
||||
)
|
||||
.join("\n");
|
||||
}
|
||||
|
||||
export function transformAnthropicChatResponseToAnthropicText(
|
||||
anthropicBody: Record<string, any>
|
||||
): Record<string, any> {
|
||||
return {
|
||||
type: "completion",
|
||||
id: "ant-" + anthropicBody.id,
|
||||
completion: flattenChatResponse(anthropicBody.content),
|
||||
stop_reason: anthropicBody.stop_reason,
|
||||
stop: anthropicBody.stop_sequence,
|
||||
model: anthropicBody.model,
|
||||
usage: anthropicBody.usage,
|
||||
};
|
||||
}
|
||||
|
||||
function transformAnthropicTextResponseToOpenAI(
|
||||
anthropicBody: Record<string, any>,
|
||||
req: Request
|
||||
): Record<string, any> {
|
||||
const totalTokens = (req.promptTokens ?? 0) + (req.outputTokens ?? 0);
|
||||
return {
|
||||
id: "ant-" + anthropicBody.log_id,
|
||||
object: "chat.completion",
|
||||
created: Date.now(),
|
||||
model: anthropicBody.model,
|
||||
usage: {
|
||||
prompt_tokens: req.promptTokens,
|
||||
completion_tokens: req.outputTokens,
|
||||
total_tokens: totalTokens,
|
||||
},
|
||||
choices: [
|
||||
{
|
||||
message: {
|
||||
role: "assistant",
|
||||
content: anthropicBody.completion?.trim(),
|
||||
},
|
||||
finish_reason: anthropicBody.stop_reason,
|
||||
index: 0,
|
||||
},
|
||||
],
|
||||
};
|
||||
}
|
||||
|
||||
export function transformAnthropicChatResponseToOpenAI(
|
||||
anthropicBody: Record<string, any>
|
||||
): Record<string, any> {
|
||||
return {
|
||||
id: "ant-" + anthropicBody.id,
|
||||
object: "chat.completion",
|
||||
created: Date.now(),
|
||||
model: anthropicBody.model,
|
||||
usage: anthropicBody.usage,
|
||||
choices: [
|
||||
{
|
||||
message: {
|
||||
role: "assistant",
|
||||
content: flattenChatResponse(anthropicBody.content),
|
||||
},
|
||||
finish_reason: anthropicBody.stop_reason,
|
||||
index: 0,
|
||||
},
|
||||
],
|
||||
};
|
||||
}
|
||||
|
||||
/**
|
||||
* If a client using the OpenAI compatibility endpoint requests an actual OpenAI
|
||||
* model, reassigns it to Sonnet.
|
||||
*/
|
||||
function maybeReassignModel(req: Request) {
|
||||
const model = req.body.model;
|
||||
if (model.includes("claude")) return; // use whatever model the user requested
|
||||
req.body.model = "claude-3-5-sonnet-latest";
|
||||
}
|
||||
|
||||
/**
|
||||
* If client requests more than 4096 output tokens the request must have a
|
||||
* particular version header.
|
||||
* https://docs.anthropic.com/en/release-notes/api#july-15th-2024
|
||||
*
|
||||
* Also adds the required beta header for 1-hour cache duration if requested.
|
||||
* Also adds the 1M context beta header for Claude Sonnet 4 if context > 200k tokens.
|
||||
* Also validates Claude 4.1 Opus parameters (temperature/top_p).
|
||||
*/
|
||||
function setAnthropicBetaHeader(req: Request) {
|
||||
// Validate Claude 4.1 Opus parameters before processing
|
||||
validateClaude41OpusParameters(req);
|
||||
|
||||
const { max_tokens_to_sample } = req.body;
|
||||
const model = req.body.model;
|
||||
|
||||
// Initialize beta headers array
|
||||
const betaHeaders: string[] = [];
|
||||
|
||||
// Add max tokens beta header if needed
|
||||
if (max_tokens_to_sample > 4096) {
|
||||
betaHeaders.push("max-tokens-3-5-sonnet-2024-07-15");
|
||||
}
|
||||
|
||||
// Add extended cache TTL beta header if 1h cache is requested
|
||||
if (req.body.cache_control?.ttl === "1h") {
|
||||
betaHeaders.push("extended-cache-ttl-2025-04-11");
|
||||
}
|
||||
|
||||
// Add 1M context beta header for Claude Sonnet 4 if context > 200k tokens
|
||||
if (model?.includes("claude-sonnet-4") && req.promptTokens && req.outputTokens) {
|
||||
const contextTokens = req.promptTokens + req.outputTokens;
|
||||
if (contextTokens > 200000) {
|
||||
betaHeaders.push("context-1m-2025-08-07");
|
||||
}
|
||||
}
|
||||
|
||||
// Set the combined beta headers if any were added
|
||||
if (betaHeaders.length > 0) {
|
||||
req.headers["anthropic-beta"] = betaHeaders.join(",");
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Adds web search tool for Claude-3.5 and Claude-3.7 models when enable_web_search is true
|
||||
*
|
||||
* Supports all optional parameters documented in the Claude API:
|
||||
* - max_uses: Limit the number of searches per request
|
||||
* - allowed_domains: Only include results from these domains
|
||||
* - blocked_domains: Never include results from these domains
|
||||
* - user_location: Localize search results
|
||||
*/
|
||||
function addWebSearchTool(req: Request) {
|
||||
// Check if this is a Claude model that supports web search and if web search is enabled
|
||||
const isClaude35 = req.body.model?.includes("claude-3-5") || req.body.model?.includes("claude-3.5");
|
||||
const isClaude37 = req.body.model?.includes("claude-3-7") || req.body.model?.includes("claude-3.7");
|
||||
const isClaude4 = req.body.model?.includes("claude-sonnet-4") || req.body.model?.includes("claude-opus-4");
|
||||
const useWebSearch = (isClaude35 || isClaude37 || isClaude4) && Boolean(req.body.enable_web_search);
|
||||
|
||||
if (useWebSearch) {
|
||||
// Create the base web search tool
|
||||
const webSearchTool: any = {
|
||||
'type': 'web_search_20250305',
|
||||
'name': 'web_search',
|
||||
};
|
||||
|
||||
// Add optional parameters if provided by the client
|
||||
|
||||
// max_uses: Limit the number of searches per request
|
||||
if (typeof req.body.web_search_max_uses === 'number') {
|
||||
webSearchTool.max_uses = req.body.web_search_max_uses;
|
||||
delete req.body.web_search_max_uses;
|
||||
}
|
||||
|
||||
// allowed_domains: Only include results from these domains
|
||||
if (Array.isArray(req.body.web_search_allowed_domains)) {
|
||||
webSearchTool.allowed_domains = req.body.web_search_allowed_domains;
|
||||
delete req.body.web_search_allowed_domains;
|
||||
}
|
||||
|
||||
// blocked_domains: Never include results from these domains
|
||||
if (Array.isArray(req.body.web_search_blocked_domains)) {
|
||||
webSearchTool.blocked_domains = req.body.web_search_blocked_domains;
|
||||
delete req.body.web_search_blocked_domains;
|
||||
}
|
||||
|
||||
// user_location: Localize search results
|
||||
if (req.body.web_search_user_location) {
|
||||
webSearchTool.user_location = req.body.web_search_user_location;
|
||||
delete req.body.web_search_user_location;
|
||||
}
|
||||
|
||||
// Add the web search tool to the tools array
|
||||
req.body.tools = [...(req.body.tools || []), webSearchTool];
|
||||
}
|
||||
|
||||
// Delete custom parameters as they're not standard Claude API parameters
|
||||
delete req.body.enable_web_search;
|
||||
delete req.body.reasoning_effort;
|
||||
}
|
||||
|
||||
function selectUpstreamPath(manager: ProxyReqManager) {
|
||||
const req = manager.request;
|
||||
const pathname = req.url.split("?")[0];
|
||||
req.log.debug({ pathname }, "Anthropic path filter");
|
||||
const isText = req.outboundApi === "anthropic-text";
|
||||
const isChat = req.outboundApi === "anthropic-chat";
|
||||
if (isChat && pathname === "/v1/complete") {
|
||||
manager.setPath("/v1/messages");
|
||||
}
|
||||
if (isText && pathname === "/v1/chat/completions") {
|
||||
manager.setPath("/v1/complete");
|
||||
}
|
||||
if (isChat && pathname === "/v1/chat/completions") {
|
||||
manager.setPath("/v1/messages");
|
||||
}
|
||||
if (isChat && ["sonnet", "opus"].includes(req.params.type)) {
|
||||
manager.setPath("/v1/messages");
|
||||
}
|
||||
}
|
||||
|
||||
const anthropicProxy = createQueuedProxyMiddleware({
|
||||
target: "https://api.anthropic.com",
|
||||
mutations: [selectUpstreamPath, addKey, finalizeBody],
|
||||
blockingResponseHandler: anthropicBlockingResponseHandler,
|
||||
});
|
||||
|
||||
const nativeAnthropicChatPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "anthropic-chat", outApi: "anthropic-chat", service: "anthropic" },
|
||||
{ afterTransform: [setAnthropicBetaHeader, addWebSearchTool] }
|
||||
);
|
||||
|
||||
const nativeTextPreprocessor = createPreprocessorMiddleware(
|
||||
{
|
||||
inApi: "anthropic-text",
|
||||
outApi: "anthropic-text",
|
||||
service: "anthropic",
|
||||
},
|
||||
{ afterTransform: [setAnthropicBetaHeader, addWebSearchTool] }
|
||||
);
|
||||
|
||||
const textToChatPreprocessor = createPreprocessorMiddleware(
|
||||
{
|
||||
inApi: "anthropic-text",
|
||||
outApi: "anthropic-chat",
|
||||
service: "anthropic",
|
||||
},
|
||||
{ afterTransform: [setAnthropicBetaHeader, addWebSearchTool] }
|
||||
);
|
||||
|
||||
/**
|
||||
* Routes text completion prompts to anthropic-chat if they need translation
|
||||
* (claude-3 based models do not support the old text completion endpoint).
|
||||
*/
|
||||
const preprocessAnthropicTextRequest: RequestHandler = (req, res, next) => {
|
||||
const model = req.body.model;
|
||||
const isClaude4Model = model?.includes("claude-sonnet-4") || model?.includes("claude-opus-4");
|
||||
if (model?.startsWith("claude-3") || isClaude4Model) {
|
||||
textToChatPreprocessor(req, res, next);
|
||||
} else {
|
||||
nativeTextPreprocessor(req, res, next);
|
||||
}
|
||||
};
|
||||
|
||||
const oaiToTextPreprocessor = createPreprocessorMiddleware(
|
||||
{
|
||||
inApi: "openai",
|
||||
outApi: "anthropic-text",
|
||||
service: "anthropic",
|
||||
},
|
||||
{ afterTransform: [setAnthropicBetaHeader] }
|
||||
);
|
||||
|
||||
const oaiToChatPreprocessor = createPreprocessorMiddleware(
|
||||
{
|
||||
inApi: "openai",
|
||||
outApi: "anthropic-chat",
|
||||
service: "anthropic",
|
||||
},
|
||||
{ afterTransform: [setAnthropicBetaHeader, addWebSearchTool] }
|
||||
);
|
||||
|
||||
/**
|
||||
* Routes an OpenAI prompt to either the legacy Claude text completion endpoint
|
||||
* or the new Claude chat completion endpoint, based on the requested model.
|
||||
*/
|
||||
const preprocessOpenAICompatRequest: RequestHandler = (req, res, next) => {
|
||||
maybeReassignModel(req);
|
||||
const model = req.body.model;
|
||||
const isClaude4 = model?.includes("claude-sonnet-4") || model?.includes("claude-opus-4");
|
||||
if (model?.includes("claude-3") || isClaude4) {
|
||||
oaiToChatPreprocessor(req, res, next);
|
||||
} else {
|
||||
oaiToTextPreprocessor(req, res, next);
|
||||
}
|
||||
};
|
||||
|
||||
const anthropicRouter = Router();
|
||||
anthropicRouter.get("/v1/models", handleModelRequest);
|
||||
// Native Anthropic chat completion endpoint.
|
||||
anthropicRouter.post(
|
||||
"/v1/messages",
|
||||
ipLimiter,
|
||||
nativeAnthropicChatPreprocessor,
|
||||
anthropicProxy
|
||||
);
|
||||
// Anthropic text completion endpoint. Translates to Anthropic chat completion
|
||||
// if the requested model is a Claude 3 model.
|
||||
anthropicRouter.post(
|
||||
"/v1/complete",
|
||||
ipLimiter,
|
||||
preprocessAnthropicTextRequest,
|
||||
anthropicProxy
|
||||
);
|
||||
// OpenAI-to-Anthropic compatibility endpoint. Accepts an OpenAI chat completion
|
||||
// request and transforms/routes it to the appropriate Anthropic format and
|
||||
// endpoint based on the requested model.
|
||||
anthropicRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
preprocessOpenAICompatRequest,
|
||||
anthropicProxy
|
||||
);
|
||||
|
||||
export const anthropic = anthropicRouter;
|
||||
@@ -0,0 +1,345 @@
|
||||
import { Request, RequestHandler, Router } from "express";
|
||||
import { v4 } from "uuid";
|
||||
import {
|
||||
transformAnthropicChatResponseToAnthropicText,
|
||||
transformAnthropicChatResponseToOpenAI,
|
||||
} from "./anthropic";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import {
|
||||
createPreprocessorMiddleware,
|
||||
finalizeSignedRequest,
|
||||
signAwsRequest,
|
||||
} from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import { ProxyReqManager } from "./middleware/request/proxy-req-manager";
|
||||
import { validateClaude41OpusParameters } from "../shared/claude-4-1-validation";
|
||||
|
||||
const awsBlockingResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
switch (`${req.inboundApi}<-${req.outboundApi}`) {
|
||||
case "openai<-anthropic-text":
|
||||
req.log.info("Transforming Anthropic Text back to OpenAI format");
|
||||
newBody = transformAwsTextResponseToOpenAI(body, req);
|
||||
break;
|
||||
case "openai<-anthropic-chat":
|
||||
req.log.info("Transforming AWS Anthropic Chat back to OpenAI format");
|
||||
newBody = transformAnthropicChatResponseToOpenAI(body);
|
||||
break;
|
||||
case "anthropic-text<-anthropic-chat":
|
||||
req.log.info("Transforming AWS Anthropic Chat back to Text format");
|
||||
newBody = transformAnthropicChatResponseToAnthropicText(body);
|
||||
break;
|
||||
}
|
||||
|
||||
// AWS does not always confirm the model in the response, so we have to add it
|
||||
if (!newBody.model && req.body.model) {
|
||||
newBody.model = req.body.model;
|
||||
}
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
function transformAwsTextResponseToOpenAI(
|
||||
awsBody: Record<string, any>,
|
||||
req: Request
|
||||
): Record<string, any> {
|
||||
const totalTokens = (req.promptTokens ?? 0) + (req.outputTokens ?? 0);
|
||||
return {
|
||||
id: "aws-" + v4(),
|
||||
object: "chat.completion",
|
||||
created: Date.now(),
|
||||
model: req.body.model,
|
||||
usage: {
|
||||
prompt_tokens: req.promptTokens,
|
||||
completion_tokens: req.outputTokens,
|
||||
total_tokens: totalTokens,
|
||||
},
|
||||
choices: [
|
||||
{
|
||||
message: {
|
||||
role: "assistant",
|
||||
content: awsBody.completion?.trim(),
|
||||
},
|
||||
finish_reason: awsBody.stop_reason,
|
||||
index: 0,
|
||||
},
|
||||
],
|
||||
};
|
||||
}
|
||||
|
||||
const awsClaudeProxy = createQueuedProxyMiddleware({
|
||||
target: ({ signedRequest }) => {
|
||||
if (!signedRequest) throw new Error("Must sign request before proxying");
|
||||
return `${signedRequest.protocol}//${signedRequest.hostname}`;
|
||||
},
|
||||
mutations: [signAwsRequest, finalizeSignedRequest],
|
||||
blockingResponseHandler: awsBlockingResponseHandler,
|
||||
});
|
||||
|
||||
const nativeTextPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "anthropic-text", outApi: "anthropic-text", service: "aws" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
);
|
||||
|
||||
const textToChatPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "anthropic-text", outApi: "anthropic-chat", service: "aws" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
);
|
||||
|
||||
/**
|
||||
* Routes text completion prompts to aws anthropic-chat if they need translation
|
||||
* (claude-3 and claude-4 based models do not support the old text completion endpoint).
|
||||
*/
|
||||
const preprocessAwsTextRequest: RequestHandler = (req, res, next) => {
|
||||
const model = req.body.model;
|
||||
const isClaude4Model = model?.includes("claude-sonnet-4") || model?.includes("claude-opus-4");
|
||||
if (model?.includes("claude-3") || isClaude4Model) {
|
||||
textToChatPreprocessor(req, res, next);
|
||||
} else {
|
||||
nativeTextPreprocessor(req, res, next);
|
||||
}
|
||||
};
|
||||
|
||||
const oaiToAwsTextPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "anthropic-text", service: "aws" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
);
|
||||
|
||||
const oaiToAwsChatPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "anthropic-chat", service: "aws" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
);
|
||||
|
||||
/**
|
||||
* Routes an OpenAI prompt to either the legacy Claude text completion endpoint
|
||||
* or the new Claude chat completion endpoint, based on the requested model.
|
||||
*/
|
||||
const preprocessOpenAICompatRequest: RequestHandler = (req, res, next) => {
|
||||
const model = req.body.model;
|
||||
const isClaude4Model = model?.includes("claude-sonnet-4") || model?.includes("claude-opus-4");
|
||||
if (model?.includes("claude-3") || isClaude4Model) {
|
||||
oaiToAwsChatPreprocessor(req, res, next);
|
||||
} else {
|
||||
oaiToAwsTextPreprocessor(req, res, next);
|
||||
}
|
||||
};
|
||||
|
||||
const awsClaudeRouter = Router();
|
||||
// Native(ish) Anthropic text completion endpoint.
|
||||
awsClaudeRouter.post(
|
||||
"/v1/complete",
|
||||
ipLimiter,
|
||||
preprocessAwsTextRequest,
|
||||
awsClaudeProxy
|
||||
);
|
||||
// Native Anthropic chat completion endpoint.
|
||||
awsClaudeRouter.post(
|
||||
"/v1/messages",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "anthropic-chat", outApi: "anthropic-chat", service: "aws" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
),
|
||||
awsClaudeProxy
|
||||
);
|
||||
|
||||
// OpenAI-to-AWS Anthropic compatibility endpoint.
|
||||
awsClaudeRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
preprocessOpenAICompatRequest,
|
||||
awsClaudeProxy
|
||||
);
|
||||
|
||||
/**
|
||||
* Tries to deal with:
|
||||
* - frontends sending AWS model names even when they want to use the OpenAI-
|
||||
* compatible endpoint
|
||||
* - frontends sending Anthropic model names that AWS doesn't recognize
|
||||
* - frontends sending OpenAI model names because they expect the proxy to
|
||||
* translate them
|
||||
*
|
||||
* If client sends AWS model ID it will be used verbatim. Otherwise, various
|
||||
* strategies are used to try to map a non-AWS model name to AWS model ID.
|
||||
*/
|
||||
function maybeReassignModel(req: Request) {
|
||||
// Validate Claude 4.1 Opus parameters before processing
|
||||
validateClaude41OpusParameters(req);
|
||||
|
||||
const model = req.body.model;
|
||||
|
||||
// If it looks like an AWS model, use it as-is
|
||||
if (model.includes("anthropic.claude")) {
|
||||
return;
|
||||
}
|
||||
|
||||
// Anthropic model names can look like:
|
||||
// - claude-v1
|
||||
// - claude-2.1
|
||||
// - claude-3-5-sonnet-20240620 (old format: number-model)
|
||||
// - claude-3-opus-latest (old format: number-model)
|
||||
// - claude-sonnet-4-20250514 (new format: model-number)
|
||||
// - claude-opus-4-latest (new format: model-number)
|
||||
// - anthropic.claude-3-sonnet-20240229-v1:0 (AWS format with old naming)
|
||||
// - anthropic.claude-sonnet-4-20250514-v1:0 (AWS format with new naming)
|
||||
const pattern =
|
||||
/^(?:anthropic\.)?claude-(?:(?:(instant-)?(v)?(\d+)([.-](\d))?(-\d+k)?(-sonnet-|-opus-|-haiku-)?(latest|\d*))|(?:(sonnet-|opus-|haiku-)(\d+)([.-](\d))?(-\d+k)?-(latest|\d+)))(?:-v\d+(?::\d+)?)?$/i;
|
||||
const match = model.match(pattern);
|
||||
|
||||
if (!match) {
|
||||
throw new Error(`Provided model name (${model}) doesn't resemble a Claude model ID.`);
|
||||
}
|
||||
|
||||
// Check which format matched (old or new)
|
||||
// New format: claude-sonnet-4-20250514 or anthropic.claude-sonnet-4-20250514-v1:0
|
||||
// Old format: claude-3-sonnet-20240229 or anthropic.claude-3-sonnet-20240229-v1:0
|
||||
const isNewFormat = !!match[9];
|
||||
|
||||
let major, minor, name, rev;
|
||||
|
||||
if (isNewFormat) {
|
||||
// New format: claude-sonnet-4-20250514
|
||||
// match[9] = sonnet-/opus-/haiku-
|
||||
// match[10] = 4 (major version)
|
||||
// match[12] = minor version (if any, from [.-](\d) pattern)
|
||||
// match[14] = revision (latest or date)
|
||||
const modelType = match[9]?.match(/([a-z]+)/)?.[1] || "";
|
||||
name = modelType;
|
||||
major = match[10];
|
||||
minor = match[12];
|
||||
rev = match[14];
|
||||
|
||||
// Special case: if revision is a single digit and no minor version,
|
||||
// treat revision as minor version (e.g., claude-opus-4-1 -> version 4.1)
|
||||
if (!minor && rev && /^\d$/.test(rev)) {
|
||||
minor = rev;
|
||||
rev = undefined;
|
||||
}
|
||||
|
||||
// Handle instant case for completeness
|
||||
const instant = match[1];
|
||||
if (instant) {
|
||||
req.body.model = "anthropic.claude-instant-v1";
|
||||
return;
|
||||
}
|
||||
} else {
|
||||
// Old format: claude-3-sonnet-20240229
|
||||
// match[1] = instant- (if any)
|
||||
// match[3] = 3 (major version)
|
||||
// match[5] = minor version (if any)
|
||||
// match[7] = -sonnet-/-opus-/-haiku- (if any)
|
||||
// match[8] = revision (latest or date)
|
||||
const instant = match[1];
|
||||
if (instant) {
|
||||
req.body.model = "anthropic.claude-instant-v1";
|
||||
return;
|
||||
}
|
||||
|
||||
major = match[3];
|
||||
minor = match[5];
|
||||
name = match[7]?.match(/([a-z]+)/)?.[1] || "";
|
||||
rev = match[8];
|
||||
}
|
||||
|
||||
const ver = minor ? `${major}.${minor}` : major;
|
||||
|
||||
switch (ver) {
|
||||
case "1":
|
||||
case "1.0":
|
||||
req.body.model = "anthropic.claude-v1";
|
||||
return;
|
||||
case "2":
|
||||
case "2.0":
|
||||
req.body.model = "anthropic.claude-v2";
|
||||
return;
|
||||
case "2.1":
|
||||
req.body.model = "anthropic.claude-v2:1";
|
||||
return;
|
||||
case "3":
|
||||
case "3.0":
|
||||
// there is only one snapshot for all Claude 3 models so there is no need
|
||||
// to check the revision
|
||||
switch (name) {
|
||||
case "sonnet":
|
||||
req.body.model = "anthropic.claude-3-sonnet-20240229-v1:0";
|
||||
return;
|
||||
case "haiku":
|
||||
req.body.model = "anthropic.claude-3-haiku-20240307-v1:0";
|
||||
return;
|
||||
case "opus":
|
||||
req.body.model = "anthropic.claude-3-opus-20240229-v1:0";
|
||||
return;
|
||||
}
|
||||
break;
|
||||
case "3.5":
|
||||
switch (name) {
|
||||
case "sonnet":
|
||||
switch (rev) {
|
||||
case "20241022":
|
||||
case "latest":
|
||||
req.body.model = "anthropic.claude-3-5-sonnet-20241022-v2:0";
|
||||
return;
|
||||
case "20240620":
|
||||
req.body.model = "anthropic.claude-3-5-sonnet-20240620-v1:0";
|
||||
return;
|
||||
}
|
||||
break;
|
||||
case "haiku":
|
||||
switch (rev) {
|
||||
case "20241022":
|
||||
case "latest":
|
||||
req.body.model = "anthropic.claude-3-5-haiku-20241022-v1:0";
|
||||
return;
|
||||
}
|
||||
case "opus":
|
||||
// Add after model id is announced never
|
||||
break;
|
||||
}
|
||||
case "3.7":
|
||||
switch (name) {
|
||||
case "sonnet":
|
||||
req.body.model = "anthropic.claude-3-7-sonnet-20250219-v1:0";
|
||||
return;
|
||||
}
|
||||
break;
|
||||
case "4":
|
||||
case "4.0":
|
||||
// Mapping "claude-4-..." variants to their actual AWS Bedrock IDs
|
||||
// as defined in src/shared/claude-models.ts.
|
||||
switch (name) {
|
||||
case "sonnet":
|
||||
req.body.model = "anthropic.claude-sonnet-4-20250514-v1:0";
|
||||
return;
|
||||
case "opus":
|
||||
req.body.model = "anthropic.claude-opus-4-20250514-v1:0";
|
||||
return;
|
||||
// No case for "haiku" here, as "claude-4-haiku" is not defined
|
||||
// in claude-models.ts. It will fall through and throw an error.
|
||||
}
|
||||
break;
|
||||
case "4.1":
|
||||
// Mapping "claude-4.1-..." variants to their actual AWS Bedrock IDs
|
||||
// as defined in src/shared/claude-models.ts.
|
||||
switch (name) {
|
||||
case "opus":
|
||||
req.body.model = "anthropic.claude-opus-4-1-20250805-v1:0";
|
||||
return;
|
||||
// No sonnet or haiku variants for 4.1 yet
|
||||
}
|
||||
break;
|
||||
}
|
||||
|
||||
throw new Error(`Provided model name (${model}) could not be mapped to a known AWS Claude model ID.`);
|
||||
}
|
||||
|
||||
export const awsClaude = awsClaudeRouter;
|
||||
@@ -0,0 +1,95 @@
|
||||
import { Request, Router } from "express";
|
||||
import {
|
||||
detectMistralInputApi,
|
||||
transformMistralTextToMistralChat,
|
||||
} from "./mistral-ai";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import {
|
||||
createPreprocessorMiddleware,
|
||||
finalizeSignedRequest,
|
||||
signAwsRequest,
|
||||
} from "./middleware/request";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
|
||||
const awsMistralBlockingResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
if (req.inboundApi === "mistral-ai" && req.outboundApi === "mistral-text") {
|
||||
newBody = transformMistralTextToMistralChat(body);
|
||||
}
|
||||
// AWS does not always confirm the model in the response, so we have to add it
|
||||
if (!newBody.model && req.body.model) {
|
||||
newBody.model = req.body.model;
|
||||
}
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
const awsMistralProxy = createQueuedProxyMiddleware({
|
||||
target: ({ signedRequest }) => {
|
||||
if (!signedRequest) throw new Error("Must sign request before proxying");
|
||||
return `${signedRequest.protocol}//${signedRequest.hostname}`;
|
||||
},
|
||||
mutations: [signAwsRequest,finalizeSignedRequest],
|
||||
blockingResponseHandler: awsMistralBlockingResponseHandler,
|
||||
});
|
||||
|
||||
function maybeReassignModel(req: Request) {
|
||||
const model = req.body.model;
|
||||
|
||||
// If it looks like an AWS model, use it as-is
|
||||
if (model.startsWith("mistral.")) {
|
||||
return;
|
||||
}
|
||||
// Mistral 7B Instruct
|
||||
else if (model.includes("7b")) {
|
||||
req.body.model = "mistral.mistral-7b-instruct-v0:2";
|
||||
}
|
||||
// Mistral 8x7B Instruct
|
||||
else if (model.includes("8x7b")) {
|
||||
req.body.model = "mistral.mixtral-8x7b-instruct-v0:1";
|
||||
}
|
||||
// Mistral Large (Feb 2024)
|
||||
else if (model.includes("large-2402")) {
|
||||
req.body.model = "mistral.mistral-large-2402-v1:0";
|
||||
}
|
||||
// Mistral Large 2 (July 2024)
|
||||
else if (model.includes("large")) {
|
||||
req.body.model = "mistral.mistral-large-2407-v1:0";
|
||||
}
|
||||
// Mistral Small (Feb 2024)
|
||||
else if (model.includes("small")) {
|
||||
req.body.model = "mistral.mistral-small-2402-v1:0";
|
||||
} else {
|
||||
throw new Error(
|
||||
`Can't map '${model}' to a supported AWS model ID; make sure you are requesting a Mistral model supported by Amazon Bedrock`
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
const nativeMistralChatPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "mistral-ai", outApi: "mistral-ai", service: "aws" },
|
||||
{
|
||||
beforeTransform: [detectMistralInputApi],
|
||||
afterTransform: [maybeReassignModel],
|
||||
}
|
||||
);
|
||||
|
||||
const awsMistralRouter = Router();
|
||||
awsMistralRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
nativeMistralChatPreprocessor,
|
||||
awsMistralProxy
|
||||
);
|
||||
|
||||
export const awsMistral = awsMistralRouter;
|
||||
@@ -0,0 +1,98 @@
|
||||
/* Shared code between AWS Claude and AWS Mistral endpoints. */
|
||||
|
||||
import { Request, Response, Router } from "express";
|
||||
import { config } from "../config";
|
||||
import { addV1 } from "./add-v1";
|
||||
import { awsClaude } from "./aws-claude";
|
||||
import { awsMistral } from "./aws-mistral";
|
||||
import { AwsBedrockKey, keyPool } from "../shared/key-management";
|
||||
import { claudeModels, findByAwsId } from "../shared/claude-models";
|
||||
|
||||
const awsRouter = Router();
|
||||
awsRouter.get(["/:vendor?/v1/models", "/:vendor?/models"], handleModelsRequest);
|
||||
awsRouter.use("/claude", addV1, awsClaude);
|
||||
awsRouter.use("/mistral", addV1, awsMistral);
|
||||
|
||||
const MODELS_CACHE_TTL = 10000;
|
||||
let modelsCache: Record<string, any> = {};
|
||||
let modelsCacheTime: Record<string, number> = {};
|
||||
function handleModelsRequest(req: Request, res: Response) {
|
||||
if (!config.awsCredentials) return { object: "list", data: [] };
|
||||
|
||||
const vendor = req.params.vendor?.length
|
||||
? req.params.vendor === "claude"
|
||||
? "anthropic"
|
||||
: req.params.vendor
|
||||
: "all";
|
||||
|
||||
const cacheTime = modelsCacheTime[vendor] || 0;
|
||||
if (new Date().getTime() - cacheTime < MODELS_CACHE_TTL) {
|
||||
return res.json(modelsCache[vendor]);
|
||||
}
|
||||
|
||||
const availableAwsModelIds = new Set<string>();
|
||||
for (const key of keyPool.list()) {
|
||||
if (key.isDisabled || key.service !== "aws") continue;
|
||||
(key as AwsBedrockKey).modelIds.forEach((id) => availableAwsModelIds.add(id));
|
||||
}
|
||||
|
||||
const mistralMappings = new Map([
|
||||
["mistral.mistral-7b-instruct-v0:2", "Mistral 7B Instruct"],
|
||||
["mistral.mixtral-8x7b-instruct-v0:1", "Mixtral 8x7B Instruct"],
|
||||
["mistral.mistral-large-2402-v1:0", "Mistral Large 2402"],
|
||||
["mistral.mistral-large-2407-v1:0", "Mistral Large 2407"],
|
||||
["mistral.mistral-small-2402-v1:0", "Mistral Small 2402"],
|
||||
]);
|
||||
|
||||
const date = new Date();
|
||||
|
||||
const claudeModelsList = claudeModels
|
||||
.filter(model => availableAwsModelIds.has(model.awsId))
|
||||
.map(model => ({
|
||||
id: model.anthropicId,
|
||||
owned_by: "anthropic",
|
||||
type: "model",
|
||||
display_name: model.displayName,
|
||||
created_at: date.toISOString(),
|
||||
object: "model",
|
||||
created: date.getTime(),
|
||||
permission: [],
|
||||
root: "anthropic",
|
||||
parent: null,
|
||||
}));
|
||||
|
||||
const mistralModelsList = Array.from(mistralMappings.keys())
|
||||
.filter(id => availableAwsModelIds.has(id))
|
||||
.map(id => {
|
||||
return {
|
||||
id,
|
||||
owned_by: "mistral",
|
||||
type: "model",
|
||||
display_name: mistralMappings.get(id) || id.split('.')[1],
|
||||
created_at: date.toISOString(),
|
||||
object: "model",
|
||||
created: date.getTime(),
|
||||
permission: [],
|
||||
root: "mistral",
|
||||
parent: null,
|
||||
};
|
||||
});
|
||||
|
||||
const allModels = [...claudeModelsList, ...mistralModelsList];
|
||||
const filteredModels = vendor === "all"
|
||||
? allModels
|
||||
: allModels.filter(m => m.root === vendor);
|
||||
|
||||
modelsCache[vendor] = {
|
||||
object: "list",
|
||||
data: filteredModels,
|
||||
has_more: false,
|
||||
first_id: filteredModels[0]?.id,
|
||||
last_id: filteredModels[filteredModels.length - 1]?.id,
|
||||
};
|
||||
modelsCacheTime[vendor] = date.getTime();
|
||||
|
||||
return res.json(modelsCache[vendor]);
|
||||
}
|
||||
|
||||
export const aws = awsRouter;
|
||||
@@ -0,0 +1,77 @@
|
||||
import { RequestHandler, Router } from "express";
|
||||
import { config } from "../config";
|
||||
import { generateModelList } from "./openai";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import {
|
||||
addAzureKey,
|
||||
createPreprocessorMiddleware,
|
||||
finalizeSignedRequest,
|
||||
} from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
const handleModelRequest: RequestHandler = (_req, res) => {
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return res.status(200).json(modelsCache);
|
||||
}
|
||||
|
||||
if (!config.azureCredentials) return { object: "list", data: [] };
|
||||
|
||||
const result = generateModelList("azure");
|
||||
|
||||
modelsCache = { object: "list", data: result };
|
||||
modelsCacheTime = new Date().getTime();
|
||||
res.status(200).json(modelsCache);
|
||||
};
|
||||
|
||||
const azureOpenaiResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
res.status(200).json({ ...body, proxy: body.proxy });
|
||||
};
|
||||
|
||||
const azureOpenAIProxy = createQueuedProxyMiddleware({
|
||||
target: ({ signedRequest }) => {
|
||||
if (!signedRequest) throw new Error("Must sign request before proxying");
|
||||
const { hostname, protocol } = signedRequest;
|
||||
return `${protocol}//${hostname}`;
|
||||
},
|
||||
mutations: [addAzureKey, finalizeSignedRequest],
|
||||
blockingResponseHandler: azureOpenaiResponseHandler,
|
||||
});
|
||||
|
||||
|
||||
const azureOpenAIRouter = Router();
|
||||
azureOpenAIRouter.get("/v1/models", handleModelRequest);
|
||||
azureOpenAIRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware({
|
||||
inApi: "openai",
|
||||
outApi: "openai",
|
||||
service: "azure",
|
||||
}),
|
||||
azureOpenAIProxy
|
||||
);
|
||||
azureOpenAIRouter.post(
|
||||
"/v1/images/generations",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware({
|
||||
inApi: "openai-image",
|
||||
outApi: "openai-image",
|
||||
service: "azure",
|
||||
}),
|
||||
azureOpenAIProxy
|
||||
);
|
||||
|
||||
export const azure = azureOpenAIRouter;
|
||||
@@ -0,0 +1,45 @@
|
||||
import { config } from "../config";
|
||||
import { RequestHandler } from "express";
|
||||
|
||||
const BLOCKED_REFERERS = config.blockedOrigins?.split(",") || [];
|
||||
|
||||
/** Disallow requests from blocked origins and referers. */
|
||||
export const checkOrigin: RequestHandler = (req, res, next) => {
|
||||
const blocks = BLOCKED_REFERERS || [];
|
||||
for (const block of blocks) {
|
||||
if (
|
||||
req.headers.origin?.includes(block) ||
|
||||
req.headers.referer?.includes(block)
|
||||
) {
|
||||
req.log.warn(
|
||||
{ origin: req.headers.origin, referer: req.headers.referer },
|
||||
"Blocked request from origin or referer"
|
||||
);
|
||||
|
||||
// VenusAI requests incorrectly say they accept HTML despite immediately
|
||||
// trying to parse the response as JSON, so we check the body type instead
|
||||
const hasJsonBody =
|
||||
req.headers["content-type"]?.includes("application/json");
|
||||
if (!req.accepts("html") || hasJsonBody) {
|
||||
return res.status(403).json({
|
||||
error: { type: "blocked_origin", message: config.blockMessage },
|
||||
});
|
||||
} else {
|
||||
const destination = config.blockRedirect || "https://openai.com";
|
||||
return res.status(403).send(
|
||||
`<html>
|
||||
<head>
|
||||
<title>Redirecting</title>
|
||||
<meta http-equiv="refresh" content="3; url=${destination}" />
|
||||
</head>
|
||||
<body style="font-family: sans-serif; height: 100vh; display: flex; flex-direction: column; justify-content: center; text-align: center;">
|
||||
<h2>${config.blockMessage}</h3>
|
||||
<p><strong>Please hold while you are redirected to a more suitable service.</strong></p>
|
||||
</body>
|
||||
</html>`
|
||||
);
|
||||
}
|
||||
}
|
||||
}
|
||||
next();
|
||||
};
|
||||
@@ -0,0 +1,106 @@
|
||||
/**
|
||||
* Authenticates RisuAI.xyz users using a special x-risu-tk header provided by
|
||||
* RisuAI.xyz. This lets us rate limit and limit queue concurrency properly,
|
||||
* since otherwise RisuAI.xyz users share the same IP address and can't be
|
||||
* distinguished.
|
||||
* Contributors: @kwaroran
|
||||
*/
|
||||
import crypto from "crypto";
|
||||
import { Request, Response, NextFunction } from "express";
|
||||
import { logger } from "../logger";
|
||||
|
||||
const log = logger.child({ module: "check-risu-token" });
|
||||
|
||||
const RISUAI_PUBLIC_KEY = `
|
||||
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArEXBmHQfy/YdNIu9lfNC
|
||||
xHbVwb2aYx07pBEmqQJtvVEOISj80fASxg+cMJH+/0a/Z4gQgzUJl0HszRpMXAfu
|
||||
wmRoetedyC/6CLraHke0Qad/AEHAKwG9A+NwsHRv/cDfP8euAr20cnOyVa79bZsl
|
||||
1wlHYQQGo+ve+P/FXtjLGJ/KZYr479F5jkIRKZxPE8mRmkhAVS/u+18QM94BzfoI
|
||||
0LlbwvvCHe18QSX6viDK+HsqhhyYDh+0FgGNJw6xKYLdExbQt77FSukH7NaJmVAs
|
||||
kYuIJbnAGw5Oq0L6dXFW2DFwlcLz51kPVOmDc159FsQjyuPnta7NiZAANS8KM1CJ
|
||||
pwIDAQAB`;
|
||||
let IMPORTED_RISU_KEY: CryptoKey | null = null;
|
||||
|
||||
type RisuToken = { id: string; expiresIn: number };
|
||||
type SignedToken = { data: RisuToken; sig: string };
|
||||
|
||||
(async () => {
|
||||
try {
|
||||
log.debug("Importing Risu public key");
|
||||
IMPORTED_RISU_KEY = await crypto.subtle.importKey(
|
||||
"spki",
|
||||
Buffer.from(RISUAI_PUBLIC_KEY.replace(/\s/g, ""), "base64"),
|
||||
{ name: "RSASSA-PKCS1-v1_5", hash: "SHA-256" },
|
||||
true,
|
||||
["verify"]
|
||||
);
|
||||
log.debug("Imported Risu public key");
|
||||
} catch (err) {
|
||||
log.warn({ error: err.message }, "Error importing Risu public key");
|
||||
IMPORTED_RISU_KEY = null;
|
||||
}
|
||||
})();
|
||||
|
||||
export async function checkRisuToken(
|
||||
req: Request,
|
||||
_res: Response,
|
||||
next: NextFunction
|
||||
) {
|
||||
let header = req.header("x-risu-tk") || null;
|
||||
if (!header || !IMPORTED_RISU_KEY) {
|
||||
return next();
|
||||
}
|
||||
|
||||
try {
|
||||
const { valid, data } = await validCheck(header);
|
||||
|
||||
if (!valid || !data) {
|
||||
req.log.warn(
|
||||
{ token: header, data },
|
||||
"Invalid RisuAI token; using IP instead"
|
||||
);
|
||||
} else {
|
||||
req.log.info("RisuAI token validated");
|
||||
req.risuToken = String(data.id);
|
||||
}
|
||||
} catch (err) {
|
||||
req.log.warn(
|
||||
{ error: err.message },
|
||||
"Error validating RisuAI token; using IP instead"
|
||||
);
|
||||
}
|
||||
|
||||
next();
|
||||
}
|
||||
|
||||
async function validCheck(header: string) {
|
||||
let tk: SignedToken;
|
||||
try {
|
||||
tk = JSON.parse(
|
||||
Buffer.from(decodeURIComponent(header), "base64").toString("utf-8")
|
||||
);
|
||||
} catch (err) {
|
||||
log.warn({ error: err.message }, "Provided unparseable RisuAI token");
|
||||
return { valid: false };
|
||||
}
|
||||
const data: RisuToken = tk.data;
|
||||
const sig = Buffer.from(tk.sig, "base64");
|
||||
|
||||
if (data.expiresIn < Math.floor(Date.now() / 1000)) {
|
||||
log.warn({ token: header }, "Provided expired RisuAI token");
|
||||
return { valid: false };
|
||||
}
|
||||
|
||||
const valid = await crypto.subtle.verify(
|
||||
{ name: "RSASSA-PKCS1-v1_5" },
|
||||
IMPORTED_RISU_KEY!,
|
||||
sig,
|
||||
Buffer.from(JSON.stringify(data))
|
||||
);
|
||||
|
||||
if (!valid) {
|
||||
log.warn({ token: header }, "RisuAI token failed signature check");
|
||||
}
|
||||
|
||||
return { valid, data };
|
||||
}
|
||||
@@ -0,0 +1,222 @@
|
||||
import { Request, RequestHandler, Router } from "express";
|
||||
import { createPreprocessorMiddleware } from "./middleware/request";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import { addKey, finalizeBody } from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import axios from "axios";
|
||||
import { CohereKey, keyPool } from "../shared/key-management";
|
||||
import { isCohereModel, normalizeMessages } from "../shared/api-schemas/cohere";
|
||||
import { logger } from "../logger";
|
||||
|
||||
const log = logger.child({ module: "proxy", service: "cohere" });
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
const cohereResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
res.status(200).json({ ...body, proxy: body.proxy });
|
||||
};
|
||||
|
||||
const getModelsResponse = async () => {
|
||||
// Return cache if less than 1 minute old
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
try {
|
||||
// Get a Cohere key directly
|
||||
const modelToUse = "command"; // Use any Cohere model here - just for key selection
|
||||
const cohereKey = keyPool.get(modelToUse, "cohere") as CohereKey;
|
||||
|
||||
if (!cohereKey || !cohereKey.key) {
|
||||
log.warn("No valid Cohere key available for model listing");
|
||||
throw new Error("No valid Cohere API key available");
|
||||
}
|
||||
|
||||
// Fetch models directly from Cohere API
|
||||
const response = await axios.get("https://api.cohere.com/v1/models", {
|
||||
headers: {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": `Bearer ${cohereKey.key}`,
|
||||
"Cohere-Version": "2022-12-06"
|
||||
},
|
||||
});
|
||||
|
||||
if (!response.data || !response.data.models) {
|
||||
throw new Error("Unexpected response format from Cohere API");
|
||||
}
|
||||
|
||||
// Extract models and filter by those that support the chat endpoint
|
||||
const filteredModels = response.data.models
|
||||
.filter((model: any) => {
|
||||
return model.endpoints && model.endpoints.includes("chat");
|
||||
})
|
||||
.map((model: any) => ({
|
||||
id: model.name,
|
||||
name: model.name,
|
||||
// Adding additional OpenAI-compatible fields
|
||||
context_window: model.context_window_size || 4096,
|
||||
max_tokens: model.max_tokens || 4096
|
||||
}));
|
||||
|
||||
log.debug({ modelCount: filteredModels.length, models: filteredModels.map((m: any) => m.id) }, "Filtered models from Cohere API");
|
||||
|
||||
// Format response to ensure OpenAI compatibility
|
||||
const models = {
|
||||
object: "list",
|
||||
data: filteredModels.map((model: any) => ({
|
||||
id: model.id,
|
||||
object: "model",
|
||||
created: Math.floor(Date.now() / 1000),
|
||||
owned_by: "cohere",
|
||||
permission: [],
|
||||
root: model.id,
|
||||
parent: null,
|
||||
context_length: model.context_window,
|
||||
})),
|
||||
};
|
||||
|
||||
log.debug({ modelCount: filteredModels.length }, "Retrieved models from Cohere API");
|
||||
|
||||
// Cache the response
|
||||
modelsCache = models;
|
||||
modelsCacheTime = new Date().getTime();
|
||||
return models;
|
||||
} catch (error) {
|
||||
// Provide detailed logging for better troubleshooting
|
||||
if (error instanceof Error) {
|
||||
log.error(
|
||||
{ errorMessage: error.message, stack: error.stack },
|
||||
"Error fetching Cohere models"
|
||||
);
|
||||
} else {
|
||||
log.error({ error }, "Unknown error fetching Cohere models");
|
||||
}
|
||||
|
||||
// Return empty list as fallback
|
||||
return {
|
||||
object: "list",
|
||||
data: [],
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
const handleModelRequest: RequestHandler = async (_req, res) => {
|
||||
try {
|
||||
const models = await getModelsResponse();
|
||||
res.status(200).json(models);
|
||||
} catch (error) {
|
||||
if (error instanceof Error) {
|
||||
log.error(
|
||||
{ errorMessage: error.message, stack: error.stack },
|
||||
"Error handling model request"
|
||||
);
|
||||
} else {
|
||||
log.error({ error }, "Unknown error handling model request");
|
||||
}
|
||||
res.status(500).json({ error: "Failed to fetch models" });
|
||||
}
|
||||
};
|
||||
|
||||
// Function to prepare messages for Cohere API
|
||||
function prepareMessages(req: Request) {
|
||||
if (req.body.messages && Array.isArray(req.body.messages)) {
|
||||
req.body.messages = normalizeMessages(req.body.messages);
|
||||
}
|
||||
}
|
||||
|
||||
// Function to remove parameters not supported by Cohere models
|
||||
function removeUnsupportedParameters(req: Request) {
|
||||
const model = req.body.model;
|
||||
|
||||
// Remove parameters that Cohere doesn't support
|
||||
if (req.body.logit_bias !== undefined) {
|
||||
delete req.body.logit_bias;
|
||||
}
|
||||
|
||||
if (req.body.top_logprobs !== undefined) {
|
||||
delete req.body.top_logprobs;
|
||||
}
|
||||
|
||||
if (req.body.max_completion_tokens !== undefined) {
|
||||
delete req.body.max_completion_tokens;
|
||||
}
|
||||
|
||||
// Handle structured output format
|
||||
if (req.body.response_format && req.body.response_format.schema) {
|
||||
// Transform to Cohere's format if needed
|
||||
const jsonSchema = req.body.response_format.schema;
|
||||
req.body.response_format = {
|
||||
type: "json_object",
|
||||
schema: jsonSchema
|
||||
};
|
||||
}
|
||||
|
||||
// Logging for debugging
|
||||
if (process.env.NODE_ENV !== 'production') {
|
||||
log.debug({ body: req.body }, "Request after parameter cleanup");
|
||||
}
|
||||
}
|
||||
|
||||
// Set up count token functionality for Cohere models
|
||||
function countCohereTokens(req: Request) {
|
||||
const model = req.body.model;
|
||||
|
||||
if (isCohereModel(model)) {
|
||||
// Count tokens using prompt tokens (simplified)
|
||||
if (req.promptTokens) {
|
||||
req.log.debug(
|
||||
{ tokens: req.promptTokens },
|
||||
"Estimated token count for Cohere prompt"
|
||||
);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const cohereProxy = createQueuedProxyMiddleware({
|
||||
mutations: [
|
||||
addKey,
|
||||
// Add Cohere-Version header to every request
|
||||
(manager) => {
|
||||
manager.setHeader("Cohere-Version", "2022-12-06");
|
||||
},
|
||||
finalizeBody
|
||||
],
|
||||
target: "https://api.cohere.ai/compatibility",
|
||||
blockingResponseHandler: cohereResponseHandler,
|
||||
});
|
||||
|
||||
const cohereRouter = Router();
|
||||
|
||||
cohereRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "openai", service: "cohere" },
|
||||
{ afterTransform: [ prepareMessages, removeUnsupportedParameters, countCohereTokens ] }
|
||||
),
|
||||
cohereProxy
|
||||
);
|
||||
|
||||
cohereRouter.post(
|
||||
"/v1/embeddings",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "openai", service: "cohere" },
|
||||
{ afterTransform: [] }
|
||||
),
|
||||
cohereProxy
|
||||
);
|
||||
|
||||
cohereRouter.get("/v1/models", handleModelRequest);
|
||||
|
||||
export const cohere = cohereRouter;
|
||||
@@ -0,0 +1,123 @@
|
||||
import { Request, RequestHandler, Router } from "express";
|
||||
import { createPreprocessorMiddleware } from "./middleware/request";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import { addKey, finalizeBody } from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import axios from "axios";
|
||||
import { DeepseekKey, keyPool } from "../shared/key-management";
|
||||
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
const deepseekResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
const getModelsResponse = async () => {
|
||||
// Return cache if less than 1 minute old
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
try {
|
||||
// Get a Deepseek key directly using keyPool.get()
|
||||
const modelToUse = "deepseek-chat"; // Use any Deepseek model here - just for key selection
|
||||
const deepseekKey = keyPool.get(modelToUse, "deepseek") as DeepseekKey;
|
||||
|
||||
if (!deepseekKey || !deepseekKey.key) {
|
||||
throw new Error("Failed to get valid Deepseek key");
|
||||
}
|
||||
|
||||
// Fetch models from Deepseek API with authorization
|
||||
const response = await axios.get("https://api.deepseek.com/models", {
|
||||
headers: {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": `Bearer ${deepseekKey.key}`
|
||||
},
|
||||
});
|
||||
|
||||
// If successful, update the cache
|
||||
if (response.data && response.data.data) {
|
||||
modelsCache = {
|
||||
object: "list",
|
||||
data: response.data.data.map((model: any) => ({
|
||||
id: model.id,
|
||||
object: "model",
|
||||
owned_by: "deepseek",
|
||||
})),
|
||||
};
|
||||
} else {
|
||||
throw new Error("Unexpected response format from Deepseek API");
|
||||
}
|
||||
} catch (error) {
|
||||
console.error("Error fetching Deepseek models:", error);
|
||||
throw error; // No fallback - error will be passed to caller
|
||||
}
|
||||
|
||||
modelsCacheTime = new Date().getTime();
|
||||
return modelsCache;
|
||||
};
|
||||
|
||||
const handleModelRequest: RequestHandler = async (_req, res) => {
|
||||
try {
|
||||
const modelsResponse = await getModelsResponse();
|
||||
res.status(200).json(modelsResponse);
|
||||
} catch (error) {
|
||||
console.error("Error in handleModelRequest:", error);
|
||||
res.status(500).json({ error: "Failed to fetch models" });
|
||||
}
|
||||
};
|
||||
|
||||
const deepseekProxy = createQueuedProxyMiddleware({
|
||||
mutations: [addKey, finalizeBody],
|
||||
target: "https://api.deepseek.com/beta",
|
||||
blockingResponseHandler: deepseekResponseHandler,
|
||||
});
|
||||
|
||||
const deepseekRouter = Router();
|
||||
|
||||
// combines all the assistant messages at the end of the context and adds the
|
||||
// beta 'prefix' option, makes prefills work the same way they work for Claude
|
||||
function enablePrefill(req: Request) {
|
||||
// If you want to disable
|
||||
if (process.env.NO_DEEPSEEK_PREFILL) return
|
||||
|
||||
const msgs = req.body.messages;
|
||||
if (msgs.at(-1)?.role !== 'assistant') return;
|
||||
|
||||
let i = msgs.length - 1;
|
||||
let content = '';
|
||||
|
||||
while (i >= 0 && msgs[i].role === 'assistant') {
|
||||
// maybe we should also add a newline between messages? no for now.
|
||||
content = msgs[i--].content + content;
|
||||
}
|
||||
|
||||
msgs.splice(i + 1, msgs.length, { role: 'assistant', content, prefix: true });
|
||||
}
|
||||
|
||||
deepseekRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "openai", service: "deepseek" },
|
||||
{ afterTransform: [ enablePrefill ] }
|
||||
),
|
||||
deepseekProxy
|
||||
);
|
||||
|
||||
deepseekRouter.get("/v1/models", handleModelRequest);
|
||||
|
||||
export const deepseek = deepseekRouter;
|
||||
@@ -0,0 +1,124 @@
|
||||
import type { Request, Response, RequestHandler } from "express";
|
||||
import { config } from "../config";
|
||||
import { authenticate, getUser } from "../shared/users/user-store";
|
||||
import { sendErrorToClient } from "./middleware/response/error-generator";
|
||||
|
||||
const GATEKEEPER = config.gatekeeper;
|
||||
const PROXY_KEY = config.proxyKey;
|
||||
const ADMIN_KEY = config.adminKey;
|
||||
|
||||
function getProxyAuthorizationFromRequest(req: Request): string | undefined {
|
||||
// Anthropic's API uses x-api-key instead of Authorization. Some clients will
|
||||
// pass the _proxy_ key in this header too, instead of providing it as a
|
||||
// Bearer token in the Authorization header. So we need to check both.
|
||||
// Prefer the Authorization header if both are present.
|
||||
// Google AI uses a key querystring parameter.
|
||||
|
||||
if (req.headers.authorization) {
|
||||
const token = req.headers.authorization?.slice("Bearer ".length);
|
||||
delete req.headers.authorization;
|
||||
return token;
|
||||
}
|
||||
|
||||
if (req.headers["x-api-key"]) {
|
||||
const token = req.headers["x-api-key"]?.toString();
|
||||
delete req.headers["x-api-key"];
|
||||
return token;
|
||||
}
|
||||
|
||||
if (req.headers["x-goog-api-key"]) {
|
||||
const token = req.headers["x-goog-api-key"]?.toString();
|
||||
delete req.headers["x-goog-api-key"];
|
||||
return token;
|
||||
}
|
||||
|
||||
if (req.query.key) {
|
||||
const token = req.query.key?.toString();
|
||||
delete req.query.key;
|
||||
return token;
|
||||
}
|
||||
|
||||
return undefined;
|
||||
}
|
||||
|
||||
export const gatekeeper: RequestHandler = (req, res, next) => {
|
||||
const token = getProxyAuthorizationFromRequest(req);
|
||||
|
||||
// TODO: Generate anonymous users based on IP address for public or proxy_key
|
||||
// modes so that all middleware can assume a user of some sort is present.
|
||||
|
||||
if (ADMIN_KEY && token === ADMIN_KEY) {
|
||||
return next();
|
||||
}
|
||||
|
||||
if (GATEKEEPER === "none") {
|
||||
return next();
|
||||
}
|
||||
|
||||
if (GATEKEEPER === "proxy_key" && token === PROXY_KEY) {
|
||||
return next();
|
||||
}
|
||||
|
||||
if (GATEKEEPER === "user_token" && token) {
|
||||
// RisuAI users all come from a handful of aws lambda IPs so we cannot use
|
||||
// IP alone to distinguish between them and prevent usertoken sharing.
|
||||
// Risu sends a signed token in the request headers with an anonymous user
|
||||
// ID that we can instead use to associate requests with an individual.
|
||||
const ip = req.risuToken?.length
|
||||
? `risu${req.risuToken}-${req.ip}`
|
||||
: req.ip;
|
||||
|
||||
const { user, result } = authenticate(token, ip);
|
||||
|
||||
switch (result) {
|
||||
case "success":
|
||||
req.user = user;
|
||||
return next();
|
||||
case "limited":
|
||||
return sendError(
|
||||
req,
|
||||
res,
|
||||
403,
|
||||
`Forbidden: no more IP addresses allowed for this user token`,
|
||||
{ currentIp: ip, maxIps: user?.maxIps }
|
||||
);
|
||||
case "disabled":
|
||||
const bannedUser = getUser(token);
|
||||
if (bannedUser?.disabledAt) {
|
||||
const reason = bannedUser.disabledReason || "User token disabled";
|
||||
return sendError(req, res, 403, `Forbidden: ${reason}`);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
sendError(req, res, 401, "Unauthorized");
|
||||
};
|
||||
|
||||
function sendError(
|
||||
req: Request,
|
||||
res: Response,
|
||||
status: number,
|
||||
message: string,
|
||||
data: any = {}
|
||||
) {
|
||||
const isPost = req.method === "POST";
|
||||
const hasBody = isPost && req.body;
|
||||
const hasModel = hasBody && req.body.model;
|
||||
|
||||
if (!hasModel) {
|
||||
return res.status(status).json({ error: message });
|
||||
}
|
||||
|
||||
sendErrorToClient({
|
||||
req,
|
||||
res,
|
||||
options: {
|
||||
title: `Proxy gatekeeper error (HTTP ${status})`,
|
||||
message,
|
||||
format: "unknown",
|
||||
statusCode: status,
|
||||
reqId: req.id,
|
||||
obj: data,
|
||||
},
|
||||
});
|
||||
}
|
||||
@@ -0,0 +1,257 @@
|
||||
import { Request, RequestHandler, Router } from "express";
|
||||
import { config } from "../config";
|
||||
import { transformAnthropicChatResponseToOpenAI } from "./anthropic";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import {
|
||||
createPreprocessorMiddleware,
|
||||
finalizeSignedRequest,
|
||||
signGcpRequest,
|
||||
} from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import { validateClaude41OpusParameters } from "../shared/claude-4-1-validation";
|
||||
|
||||
const LATEST_GCP_SONNET_MINOR_VERSION = "20240229";
|
||||
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
const getModelsResponse = () => {
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
if (!config.gcpCredentials) return { object: "list", data: [] };
|
||||
|
||||
// https://docs.anthropic.com/en/docs/about-claude/models
|
||||
const variants = [
|
||||
"claude-3-haiku@20240307",
|
||||
"claude-3-5-haiku@20241022",
|
||||
"claude-3-5-sonnet@20240620",
|
||||
"claude-3-5-sonnet-v2@20241022",
|
||||
"claude-3-7-sonnet@20250219",
|
||||
"claude-sonnet-4@20250514",
|
||||
"claude-opus-4@20250514",
|
||||
"claude-opus-4-1@20250805",
|
||||
];
|
||||
|
||||
const models = variants.map((id) => ({
|
||||
id,
|
||||
object: "model",
|
||||
created: new Date().getTime(),
|
||||
owned_by: "anthropic",
|
||||
permission: [],
|
||||
root: "claude",
|
||||
parent: null,
|
||||
}));
|
||||
|
||||
modelsCache = { object: "list", data: models };
|
||||
modelsCacheTime = new Date().getTime();
|
||||
|
||||
return modelsCache;
|
||||
};
|
||||
|
||||
const handleModelRequest: RequestHandler = (_req, res) => {
|
||||
res.status(200).json(getModelsResponse());
|
||||
};
|
||||
|
||||
const gcpBlockingResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
switch (`${req.inboundApi}<-${req.outboundApi}`) {
|
||||
case "openai<-anthropic-chat":
|
||||
req.log.info("Transforming Anthropic Chat back to OpenAI format");
|
||||
newBody = transformAnthropicChatResponseToOpenAI(body);
|
||||
break;
|
||||
}
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
const gcpProxy = createQueuedProxyMiddleware({
|
||||
target: ({ signedRequest }) => {
|
||||
if (!signedRequest) throw new Error("Must sign request before proxying");
|
||||
return `${signedRequest.protocol}//${signedRequest.hostname}`;
|
||||
},
|
||||
mutations: [signGcpRequest, finalizeSignedRequest],
|
||||
blockingResponseHandler: gcpBlockingResponseHandler,
|
||||
});
|
||||
|
||||
const oaiToChatPreprocessor = createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "anthropic-chat", service: "gcp" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
);
|
||||
|
||||
/**
|
||||
* Routes an OpenAI prompt to either the legacy Claude text completion endpoint
|
||||
* or the new Claude chat completion endpoint, based on the requested model.
|
||||
*/
|
||||
const preprocessOpenAICompatRequest: RequestHandler = (req, res, next) => {
|
||||
oaiToChatPreprocessor(req, res, next);
|
||||
};
|
||||
|
||||
const gcpRouter = Router();
|
||||
gcpRouter.get("/v1/models", handleModelRequest);
|
||||
// Native Anthropic chat completion endpoint.
|
||||
gcpRouter.post(
|
||||
"/v1/messages",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "anthropic-chat", outApi: "anthropic-chat", service: "gcp" },
|
||||
{ afterTransform: [maybeReassignModel] }
|
||||
),
|
||||
gcpProxy
|
||||
);
|
||||
|
||||
// OpenAI-to-GCP Anthropic compatibility endpoint.
|
||||
gcpRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
preprocessOpenAICompatRequest,
|
||||
gcpProxy
|
||||
);
|
||||
|
||||
/**
|
||||
* Tries to deal with:
|
||||
* - frontends sending GCP model names even when they want to use the OpenAI-
|
||||
* compatible endpoint
|
||||
* - frontends sending Anthropic model names that GCP doesn't recognize
|
||||
* - frontends sending OpenAI model names because they expect the proxy to
|
||||
* translate them
|
||||
*
|
||||
* If client sends GCP model ID it will be used verbatim. Otherwise, various
|
||||
* strategies are used to try to map a non-GCP model name to GCP model ID.
|
||||
*/
|
||||
function maybeReassignModel(req: Request) {
|
||||
// Validate Claude 4.1 Opus parameters before processing
|
||||
validateClaude41OpusParameters(req);
|
||||
|
||||
const model = req.body.model;
|
||||
const DEFAULT_MODEL = "claude-3-5-sonnet-v2@20241022";
|
||||
|
||||
// If it looks like an GCP model, use it as-is
|
||||
if (model.startsWith("claude-") && model.includes("@")) {
|
||||
return;
|
||||
}
|
||||
|
||||
// Anthropic model names can look like:
|
||||
// - claude-3-sonnet
|
||||
// - claude-3.5-sonnet
|
||||
// - claude-3-5-haiku
|
||||
// - claude-3-5-haiku-latest
|
||||
// - claude-3-5-sonnet-20240620
|
||||
// - claude-opus-4-1 (new format)
|
||||
// - claude-4.1-opus (alternative format)
|
||||
const pattern = /^claude-(?:(\d+)[.-]?(\d)?-(sonnet|opus|haiku)(?:-(latest|\d+))?|(opus|sonnet|haiku)-(\d+)[.-]?(\d)?(?:-(latest|\d+))?)/i;
|
||||
const match = model.match(pattern);
|
||||
if (!match) {
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
return;
|
||||
}
|
||||
|
||||
// Handle both formats: claude-3-5-sonnet and claude-opus-4-1
|
||||
const [_, major1, minor1, flavor1, rev1, flavor2, major2, minor2, rev2] = match;
|
||||
|
||||
let major, minor, flavor, rev;
|
||||
if (major1) {
|
||||
// Old format: claude-3-5-sonnet
|
||||
major = major1;
|
||||
minor = minor1;
|
||||
flavor = flavor1;
|
||||
rev = rev1;
|
||||
} else {
|
||||
// New format: claude-opus-4-1
|
||||
major = major2;
|
||||
minor = minor2;
|
||||
flavor = flavor2;
|
||||
rev = rev2;
|
||||
}
|
||||
|
||||
const ver = minor ? `${major}.${minor}` : major;
|
||||
|
||||
switch (ver) {
|
||||
case "3":
|
||||
case "3.0":
|
||||
switch (flavor) {
|
||||
case "haiku":
|
||||
req.body.model = "claude-3-haiku@20240307";
|
||||
break;
|
||||
case "opus":
|
||||
req.body.model = "claude-3-opus@20240229";
|
||||
break;
|
||||
case "sonnet":
|
||||
req.body.model = "claude-3-sonnet@20240229";
|
||||
break;
|
||||
default:
|
||||
req.body.model = "claude-3-sonnet@20240229";
|
||||
}
|
||||
return;
|
||||
|
||||
case "3.5":
|
||||
switch (flavor) {
|
||||
case "haiku":
|
||||
req.body.model = "claude-3-5-haiku@20241022";
|
||||
return;
|
||||
case "opus":
|
||||
// no 3.5 opus yet
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
return;
|
||||
case "sonnet":
|
||||
if (rev === "20240620") {
|
||||
req.body.model = "claude-3-5-sonnet@20240620";
|
||||
} else {
|
||||
// includes -latest, edit if anthropic actually releases 3.5 sonnet v3
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
}
|
||||
return;
|
||||
default:
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
}
|
||||
return;
|
||||
|
||||
case "3.7":
|
||||
switch (flavor) {
|
||||
case "sonnet":
|
||||
req.body.model = "claude-3-7-sonnet@20250219";
|
||||
return;
|
||||
}
|
||||
break;
|
||||
|
||||
case "4":
|
||||
case "4.0":
|
||||
switch (flavor) {
|
||||
case "opus":
|
||||
req.body.model = "claude-opus-4@20250514";
|
||||
return;
|
||||
case "sonnet":
|
||||
req.body.model = "claude-sonnet-4@20250514";
|
||||
return;
|
||||
default:
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
}
|
||||
break;
|
||||
|
||||
case "4.1":
|
||||
switch (flavor) {
|
||||
case "opus":
|
||||
req.body.model = "claude-opus-4-1@20250805";
|
||||
return;
|
||||
default:
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
}
|
||||
break;
|
||||
|
||||
default:
|
||||
req.body.model = DEFAULT_MODEL;
|
||||
}
|
||||
}
|
||||
|
||||
export const gcp = gcpRouter;
|
||||
@@ -0,0 +1,265 @@
|
||||
import { Request, RequestHandler, Router } from "express";
|
||||
import { createPreprocessorMiddleware } from "./middleware/request";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import { addKey, finalizeBody } from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import { ProxyReqMutator } from "./middleware/request";
|
||||
import axios from "axios";
|
||||
import { GlmKey, keyPool } from "../shared/key-management";
|
||||
import { isGlmModel, isGlmThinkingModel, isGlmVisionModel } from "../shared/api-schemas/glm";
|
||||
import { logger } from "../logger";
|
||||
|
||||
const log = logger.child({ module: "proxy", service: "glm" });
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
const glmResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
const getModelsResponse = async () => {
|
||||
// Return cache if less than 1 minute old
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
try {
|
||||
// Get a GLM key directly using keyPool.get()
|
||||
const modelToUse = "glm-4.5"; // Use any GLM model here - just for key selection
|
||||
const glmKey = keyPool.get(modelToUse, "glm") as GlmKey;
|
||||
|
||||
if (!glmKey || !glmKey.key) {
|
||||
log.warn("No valid GLM key available for model listing");
|
||||
throw new Error("No valid GLM API key available");
|
||||
}
|
||||
|
||||
// Fetch models from GLM API with authorization
|
||||
const response = await axios.get("https://open.bigmodel.cn/api/paas/v4/models", {
|
||||
headers: {
|
||||
"Content-Type": "application/json",
|
||||
"Authorization": `Bearer ${glmKey.key}`
|
||||
},
|
||||
});
|
||||
|
||||
if (!response.data || !response.data.data) {
|
||||
throw new Error("Unexpected response format from GLM API");
|
||||
}
|
||||
|
||||
// Extract models
|
||||
const models = response.data;
|
||||
|
||||
// Known GLM models from documentation
|
||||
const knownGlmModels = [
|
||||
"glm-4.5",
|
||||
"glm-4.5-air",
|
||||
"glm-4.5-x",
|
||||
"glm-4.5-airx",
|
||||
"glm-4.5-flash",
|
||||
"glm-4-plus",
|
||||
"glm-4-air-250414",
|
||||
"glm-4-airx",
|
||||
"glm-4-flashx",
|
||||
"glm-4-flashx-250414",
|
||||
"glm-z1-air",
|
||||
"glm-z1-airx",
|
||||
"glm-z1-flash",
|
||||
"glm-z1-flashx",
|
||||
"glm-4v", // Vision model
|
||||
];
|
||||
|
||||
// Add any missing models from our known list
|
||||
if (models.data && Array.isArray(models.data)) {
|
||||
// Create a set of existing model IDs for quick lookup
|
||||
const existingModelIds = new Set(models.data.map((model: any) => model.id));
|
||||
|
||||
// Add any missing models from our known list
|
||||
knownGlmModels.forEach(modelId => {
|
||||
if (!existingModelIds.has(modelId)) {
|
||||
models.data.push({
|
||||
id: modelId,
|
||||
object: "model",
|
||||
created: Date.now(),
|
||||
owned_by: "glm",
|
||||
});
|
||||
}
|
||||
});
|
||||
} else {
|
||||
// If the API response didn't include models, create our own list
|
||||
models.data = knownGlmModels.map(modelId => ({
|
||||
id: modelId,
|
||||
object: "model",
|
||||
created: Date.now(),
|
||||
owned_by: "glm",
|
||||
}));
|
||||
}
|
||||
|
||||
log.debug({ modelCount: models.data?.length }, "Retrieved models from GLM API");
|
||||
|
||||
// Cache the response
|
||||
modelsCache = models;
|
||||
modelsCacheTime = new Date().getTime();
|
||||
return models;
|
||||
} catch (error) {
|
||||
// Provide detailed logging for better troubleshooting
|
||||
if (error instanceof Error) {
|
||||
log.error(
|
||||
{ errorMessage: error.message, stack: error.stack },
|
||||
"Error fetching GLM models"
|
||||
);
|
||||
} else {
|
||||
log.error({ error }, "Unknown error fetching GLM models");
|
||||
}
|
||||
|
||||
// Return empty list as fallback
|
||||
return {
|
||||
object: "list",
|
||||
data: [],
|
||||
};
|
||||
}
|
||||
};
|
||||
|
||||
const handleModelRequest: RequestHandler = async (_req, res) => {
|
||||
try {
|
||||
const models = await getModelsResponse();
|
||||
res.status(200).json(models);
|
||||
} catch (error) {
|
||||
if (error instanceof Error) {
|
||||
log.error(
|
||||
{ errorMessage: error.message, stack: error.stack },
|
||||
"Error handling model request"
|
||||
);
|
||||
} else {
|
||||
log.error({ error }, "Unknown error handling model request");
|
||||
}
|
||||
res.status(500).json({ error: "Failed to fetch models" });
|
||||
}
|
||||
};
|
||||
|
||||
// Function to handle GLM-specific request processing
|
||||
function processGlmRequest(req: Request) {
|
||||
const model = req.body.model;
|
||||
|
||||
// Validate that this is actually a GLM model
|
||||
if (!isGlmModel(model)) {
|
||||
log.warn({ model }, "Non-GLM model passed to GLM processor");
|
||||
return;
|
||||
}
|
||||
|
||||
// Handle GLM-specific parameters
|
||||
if (req.body.thinking && typeof req.body.thinking === "object") {
|
||||
// GLM supports thinking mode for certain models
|
||||
if (isGlmThinkingModel(model)) {
|
||||
log.debug({ model, thinking: req.body.thinking }, "GLM thinking mode enabled");
|
||||
} else {
|
||||
delete req.body.thinking;
|
||||
log.debug({ model }, "Removed thinking parameter for non-thinking model");
|
||||
}
|
||||
}
|
||||
|
||||
// Validate and handle other GLM-specific parameters
|
||||
if (req.body.tools && req.body.tools.length > 0) {
|
||||
log.debug({ model, toolCount: req.body.tools.length }, "GLM function calling enabled");
|
||||
}
|
||||
|
||||
// Handle multimodal requests for GLM-4V
|
||||
if (isGlmVisionModel(model) && req.body.messages) {
|
||||
const hasImages = req.body.messages.some((msg: any) =>
|
||||
msg.content && Array.isArray(msg.content) &&
|
||||
msg.content.some((content: any) => content.type === "image_url")
|
||||
);
|
||||
if (hasImages) {
|
||||
log.debug({ model }, "GLM vision model request detected");
|
||||
}
|
||||
}
|
||||
|
||||
// Remove any unsupported parameters
|
||||
if (req.body.logit_bias !== undefined) {
|
||||
delete req.body.logit_bias;
|
||||
log.debug({ model }, "Removed unsupported logit_bias parameter");
|
||||
}
|
||||
|
||||
// Validate temperature and top_p ranges for GLM
|
||||
if (req.body.temperature !== undefined) {
|
||||
if (req.body.temperature < 0 || req.body.temperature > 1) {
|
||||
req.body.temperature = Math.max(0, Math.min(1, req.body.temperature));
|
||||
log.debug({ model }, "Clamped temperature to valid range [0,1]");
|
||||
}
|
||||
}
|
||||
|
||||
if (req.body.top_p !== undefined) {
|
||||
if (req.body.top_p < 0 || req.body.top_p > 1) {
|
||||
req.body.top_p = Math.max(0, Math.min(1, req.body.top_p));
|
||||
log.debug({ model }, "Clamped top_p to valid range [0,1]");
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Custom mutator to rewrite path for GLM v4 API
|
||||
const rewritePathForGlm: ProxyReqMutator = (manager) => {
|
||||
const req = manager.request;
|
||||
let newPath = req.path;
|
||||
|
||||
log.debug({ currentPath: req.path, currentUrl: req.url }, "GLM path before rewrite");
|
||||
|
||||
// Always ensure we're targeting the v4 API
|
||||
if (req.path === "/chat/completions") {
|
||||
newPath = "/v4/chat/completions";
|
||||
} else if (req.path === "/models") {
|
||||
newPath = "/v4/models";
|
||||
} else if (req.path.startsWith("/v1/")) {
|
||||
newPath = req.path.replace("/v1/", "/v4/");
|
||||
} else if (!req.path.startsWith("/v4/")) {
|
||||
newPath = `/v4${req.path}`;
|
||||
}
|
||||
|
||||
if (newPath !== req.path) {
|
||||
manager.setPath(newPath);
|
||||
log.debug({ originalPath: req.path, newPath }, "Rewrote GLM path for v4 API");
|
||||
}
|
||||
};
|
||||
|
||||
const glmProxy = createQueuedProxyMiddleware({
|
||||
mutations: [addKey, rewritePathForGlm, finalizeBody],
|
||||
target: "https://open.bigmodel.cn/api/paas",
|
||||
blockingResponseHandler: glmResponseHandler,
|
||||
});
|
||||
|
||||
const glmRouter = Router();
|
||||
|
||||
// Handle both v1 and direct paths
|
||||
glmRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "openai", service: "glm" },
|
||||
{ afterTransform: [processGlmRequest] }
|
||||
),
|
||||
glmProxy
|
||||
);
|
||||
|
||||
glmRouter.post(
|
||||
"/chat/completions",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "openai", service: "glm" },
|
||||
{ afterTransform: [processGlmRequest] }
|
||||
),
|
||||
glmProxy
|
||||
);
|
||||
|
||||
glmRouter.get("/v1/models", handleModelRequest);
|
||||
glmRouter.get("/models", handleModelRequest);
|
||||
|
||||
export const glm = glmRouter;
|
||||
@@ -0,0 +1,413 @@
|
||||
import { Request, RequestHandler, Router, Response, NextFunction } from "express";
|
||||
import { v4 } from "uuid";
|
||||
import { GoogleAIKey, keyPool } from "../shared/key-management";
|
||||
import { config } from "../config";
|
||||
import { ipLimiter } from "./rate-limit";
|
||||
import {
|
||||
createPreprocessorMiddleware,
|
||||
finalizeSignedRequest,
|
||||
} from "./middleware/request";
|
||||
import { ProxyResHandlerWithBody } from "./middleware/response";
|
||||
import { addGoogleAIKey } from "./middleware/request/mutators/add-google-ai-key";
|
||||
import { createQueuedProxyMiddleware } from "./middleware/request/proxy-middleware-factory";
|
||||
import axios from "axios";
|
||||
|
||||
let modelsCache: any = null;
|
||||
let modelsCacheTime = 0;
|
||||
|
||||
// Cache for native Google AI models
|
||||
let nativeModelsCache: any = null;
|
||||
let nativeModelsCacheTime = 0;
|
||||
|
||||
// https://ai.google.dev/models/gemini
|
||||
// TODO: list models https://ai.google.dev/tutorials/rest_quickstart#list_models
|
||||
|
||||
/**
|
||||
* Detects if a Google AI model is an image generation model
|
||||
*/
|
||||
function isGoogleAIImageModel(model: string): boolean {
|
||||
// Only specific models are image generation models, not all flash models
|
||||
return model.includes("-image") ||
|
||||
model.includes("imagen");
|
||||
}
|
||||
|
||||
const getModelsResponse = () => {
|
||||
if (new Date().getTime() - modelsCacheTime < 1000 * 60) {
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
if (!config.googleAIKey) return { object: "list", data: [] };
|
||||
|
||||
const keys = keyPool
|
||||
.list()
|
||||
.filter((k) => k.service === "google-ai") as GoogleAIKey[];
|
||||
if (keys.length === 0) {
|
||||
modelsCache = { object: "list", data: [] };
|
||||
modelsCacheTime = new Date().getTime();
|
||||
return modelsCache;
|
||||
}
|
||||
|
||||
// Get all model IDs from keys, excluding any with "bard" in the name
|
||||
const modelIds = Array.from(
|
||||
new Set(keys.map((k) => k.modelIds).flat())
|
||||
).filter((id) => id.startsWith("models/") && !id.includes("bard"));
|
||||
|
||||
// Strip "models/" prefix from IDs before creating model objects
|
||||
const models = modelIds.map((id) => ({
|
||||
// Strip "models/" prefix from ID for consistency with request processing
|
||||
id: id.startsWith("models/") ? id.slice("models/".length) : id,
|
||||
object: "model",
|
||||
created: new Date().getTime(),
|
||||
owned_by: "google",
|
||||
permission: [],
|
||||
root: "google",
|
||||
parent: null,
|
||||
}));
|
||||
|
||||
modelsCache = { object: "list", data: models };
|
||||
modelsCacheTime = new Date().getTime();
|
||||
|
||||
return modelsCache;
|
||||
};
|
||||
|
||||
// Function to fetch native models from Google AI API
|
||||
const getNativeModelsResponse = async () => {
|
||||
// Return cached value if it was refreshed in the last minute
|
||||
if (new Date().getTime() - nativeModelsCacheTime < 1000 * 60) {
|
||||
return nativeModelsCache;
|
||||
}
|
||||
|
||||
/*
|
||||
* The official Google API requires an API key. However SillyTavern only needs
|
||||
* a list of model IDs and does not care about any other model metadata. We
|
||||
* can therefore generate a **synthetic** response from the keys already
|
||||
* loaded into the proxy (same source we use for the OpenAI-compatible
|
||||
* endpoint) and completely avoid the outbound request. This removes the
|
||||
* need for the frontend to supply the proxy password as an API key and
|
||||
* prevents 4xx/5xx errors when the real Google API is unreachable or the key
|
||||
* is missing.
|
||||
*/
|
||||
const openaiStyle = getModelsResponse();
|
||||
const models = (openaiStyle.data || []).map((m: any) => ({
|
||||
// Google AI Studio returns names in the format "models/<id>"
|
||||
name: `models/${m.id}`,
|
||||
supportedGenerationMethods: ["generateContent"],
|
||||
}));
|
||||
|
||||
nativeModelsCache = { models };
|
||||
nativeModelsCacheTime = new Date().getTime();
|
||||
return nativeModelsCache;
|
||||
};
|
||||
|
||||
const handleModelRequest: RequestHandler = (_req: Request, res: any) => {
|
||||
res.status(200).json(getModelsResponse());
|
||||
};
|
||||
|
||||
// Native Gemini API model list request
|
||||
const handleNativeModelRequest: RequestHandler = async (_req: Request, res: any) => {
|
||||
try {
|
||||
const modelsResponse = await getNativeModelsResponse();
|
||||
res.status(200).json(modelsResponse);
|
||||
} catch (error) {
|
||||
console.error("Error in handleNativeModelRequest:", error);
|
||||
res.status(500).json({ error: "Failed to fetch models" });
|
||||
}
|
||||
};
|
||||
|
||||
const googleAIBlockingResponseHandler: ProxyResHandlerWithBody = async (
|
||||
_proxyRes,
|
||||
req,
|
||||
res,
|
||||
body
|
||||
) => {
|
||||
if (typeof body !== "object") {
|
||||
throw new Error("Expected body to be an object");
|
||||
}
|
||||
|
||||
let newBody = body;
|
||||
if (req.inboundApi === "openai") {
|
||||
req.log.info("Transforming Google AI response to OpenAI format");
|
||||
newBody = transformGoogleAIResponse(body, req);
|
||||
}
|
||||
|
||||
res.status(200).json({ ...newBody, proxy: body.proxy });
|
||||
};
|
||||
|
||||
function transformGoogleAIResponse(
|
||||
resBody: Record<string, any>,
|
||||
req: Request
|
||||
): Record<string, any> {
|
||||
const totalTokens = (req.promptTokens ?? 0) + (req.outputTokens ?? 0);
|
||||
const model = req.body.model;
|
||||
|
||||
// Check if this is an image generation model
|
||||
if (isGoogleAIImageModel(model)) {
|
||||
return transformGoogleAIImageResponse(resBody, req);
|
||||
}
|
||||
|
||||
// Handle the case where content might have different structures
|
||||
let content = "";
|
||||
|
||||
// Check if the response has the expected structure
|
||||
if (resBody.candidates && resBody.candidates[0]) {
|
||||
const candidate = resBody.candidates[0];
|
||||
|
||||
// Extract content text with multiple fallbacks
|
||||
if (candidate.content?.parts && candidate.content.parts[0]?.text) {
|
||||
// Regular format with parts array containing text
|
||||
content = candidate.content.parts[0].text;
|
||||
} else if (candidate.content?.text) {
|
||||
// Alternate format with direct text property
|
||||
content = candidate.content.text;
|
||||
} else if (typeof candidate.content?.parts?.[0] === 'string') {
|
||||
// Some formats might have string parts
|
||||
content = candidate.content.parts[0];
|
||||
}
|
||||
|
||||
// Apply cleanup to the content if needed
|
||||
content = content.replace(/^(.{0,50}?): /, () => "");
|
||||
}
|
||||
|
||||
return {
|
||||
id: "goo-" + v4(),
|
||||
object: "chat.completion",
|
||||
created: Date.now(),
|
||||
model: req.body.model,
|
||||
usage: {
|
||||
prompt_tokens: req.promptTokens,
|
||||
completion_tokens: req.outputTokens,
|
||||
total_tokens: totalTokens,
|
||||
},
|
||||
choices: [
|
||||
{
|
||||
message: { role: "assistant", content },
|
||||
finish_reason: resBody.candidates?.[0]?.finishReason || "STOP",
|
||||
index: 0,
|
||||
},
|
||||
],
|
||||
};
|
||||
}
|
||||
|
||||
/**
|
||||
* Transforms Google AI image generation response to OpenAI chat completion format
|
||||
*/
|
||||
function transformGoogleAIImageResponse(
|
||||
resBody: Record<string, any>,
|
||||
req: Request
|
||||
): Record<string, any> {
|
||||
const totalTokens = (req.promptTokens ?? 0) + (req.outputTokens ?? 0);
|
||||
const model = req.body.model;
|
||||
|
||||
// Extract the prompt from the request
|
||||
const prompt = req.body.contents?.[0]?.parts?.find((part: any) => part.text)?.text || "Generated image";
|
||||
|
||||
let content = "";
|
||||
|
||||
// Check if the response has image data
|
||||
if (resBody.candidates && resBody.candidates[0]) {
|
||||
const candidate = resBody.candidates[0];
|
||||
|
||||
// Look for image data in the response
|
||||
if (candidate.content?.parts) {
|
||||
const imageParts = candidate.content.parts.filter((part: any) => part.inline_data || part.data);
|
||||
|
||||
if (imageParts.length > 0) {
|
||||
content = imageParts.map((part: any, index: number) => {
|
||||
const imageData = part.inline_data?.data || part.data;
|
||||
const mimeType = part.inline_data?.mime_type || "image/png";
|
||||
|
||||
if (imageData) {
|
||||
// Convert mime type to file extension for data URL
|
||||
const format = mimeType.split('/')[1] || 'png';
|
||||
return ``;
|
||||
}
|
||||
return "";
|
||||
}).filter(Boolean).join("\n\n");
|
||||
}
|
||||
}
|
||||
|
||||
// Fallback: check for direct data field (as shown in Google's examples)
|
||||
if (!content && resBody.data) {
|
||||
content = ``;
|
||||
}
|
||||
}
|
||||
|
||||
// If no image content found, return error
|
||||
if (!content) {
|
||||
content = "Error: No image data found in response";
|
||||
}
|
||||
|
||||
return {
|
||||
id: "goo-img-" + v4(),
|
||||
object: "chat.completion",
|
||||
created: Date.now(),
|
||||
model: model,
|
||||
usage: {
|
||||
prompt_tokens: req.promptTokens || 0,
|
||||
completion_tokens: req.outputTokens || 0,
|
||||
total_tokens: totalTokens,
|
||||
},
|
||||
choices: [
|
||||
{
|
||||
message: { role: "assistant", content },
|
||||
finish_reason: resBody.candidates?.[0]?.finishReason || "stop",
|
||||
index: 0,
|
||||
},
|
||||
],
|
||||
};
|
||||
}
|
||||
|
||||
const googleAIProxy = createQueuedProxyMiddleware({
|
||||
target: ({ signedRequest }: { signedRequest: any }) => {
|
||||
if (!signedRequest) throw new Error("Must sign request before proxying");
|
||||
const { protocol, hostname} = signedRequest;
|
||||
return `${protocol}//${hostname}`;
|
||||
},
|
||||
mutations: [addGoogleAIKey, finalizeSignedRequest],
|
||||
blockingResponseHandler: googleAIBlockingResponseHandler,
|
||||
});
|
||||
|
||||
const googleAIRouter = Router();
|
||||
googleAIRouter.get("/v1/models", handleModelRequest);
|
||||
googleAIRouter.get("/:apiVersion(v1alpha|v1beta)/models", handleNativeModelRequest);
|
||||
|
||||
/**
|
||||
* Removes incompatible generationConfig parameters for image generation models
|
||||
*/
|
||||
function removeSafetySettingsForImageModels(req: Request) {
|
||||
const model = req.body.model;
|
||||
req.log.info({ model, isImageModel: isGoogleAIImageModel(model), hasGenerationConfig: !!req.body.generationConfig }, "Checking generationConfig for image models");
|
||||
|
||||
if (model && isGoogleAIImageModel(model)) {
|
||||
// Only modify generationConfig parameters - let frontend handle safety settings
|
||||
if (req.body.generationConfig) {
|
||||
const originalConfig = { ...req.body.generationConfig };
|
||||
|
||||
// Remove parameters that are incompatible with image models
|
||||
const disallowedParams = ['frequencyPenalty','presencePenalty'];
|
||||
const newConfig = { ...originalConfig };
|
||||
|
||||
for (const param of disallowedParams) {
|
||||
if (newConfig[param] !== undefined) {
|
||||
delete newConfig[param];
|
||||
}
|
||||
}
|
||||
|
||||
req.body.generationConfig = Object.keys(newConfig).length > 0 ? newConfig : undefined;
|
||||
|
||||
req.log.info({
|
||||
model,
|
||||
originalConfig,
|
||||
newConfig: req.body.generationConfig
|
||||
}, "Modified generationConfig for image generation model");
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Processes the thinking budget for Gemini 2.5 Flash model.
|
||||
* Validation has been disabled - budget is passed through without limits.
|
||||
*/
|
||||
function processThinkingBudget(req: Request) {
|
||||
// Validation disabled - budget is passed through without any range limits
|
||||
// Previously enforced 0-24576 token limit
|
||||
}
|
||||
|
||||
function setStreamFlag(req: Request) {
|
||||
const isStreaming = req.url.includes("streamGenerateContent");
|
||||
if (isStreaming) {
|
||||
req.body.stream = true;
|
||||
req.isStreaming = true;
|
||||
} else {
|
||||
req.body.stream = false;
|
||||
req.isStreaming = false;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Strips 'models/' prefix from the beginning of model IDs if present.
|
||||
* No longer forces redirection to gemini-1.5-pro-latest for non-Gemini models.
|
||||
**/
|
||||
function maybeReassignModel(req: Request) {
|
||||
// Ensure model is on body as a lot of middleware will expect it.
|
||||
const model = req.body.model || req.url.split("/").pop()?.split(":").shift();
|
||||
if (!model) {
|
||||
throw new Error("You must specify a model with your request.");
|
||||
}
|
||||
req.body.model = model;
|
||||
|
||||
// Only strip the 'models/' prefix if present
|
||||
if (model.startsWith("models/")) {
|
||||
req.body.model = model.slice("models/".length);
|
||||
req.log.info({ originalModel: model, updatedModel: req.body.model }, "Stripped 'models/' prefix from model ID");
|
||||
}
|
||||
|
||||
// No longer redirecting non-Gemini models to gemini-1.5-pro-latest
|
||||
// This allows the original model to be passed through to the API
|
||||
// If it's an invalid model, the Google AI API will return the appropriate error
|
||||
}
|
||||
|
||||
/**
|
||||
* Middleware to check for and block requests to experimental models.
|
||||
* This function is intended to be used as a RequestPreprocessor.
|
||||
* It throws an error if an experimental model is detected, which should be
|
||||
* caught by the proxy's onError handler.
|
||||
*
|
||||
* Models can be allowed through the ALLOWED_EXP_MODELS environment variable.
|
||||
*/
|
||||
function checkAndBlockExperimentalModels(req: Request) { // Changed signature
|
||||
const modelId = req.body.model as string | undefined;
|
||||
|
||||
// Check if the model ID contains "exp" (case-insensitive)
|
||||
if (modelId && modelId.toLowerCase().includes("exp")) {
|
||||
// Check if this specific model is in the allowlist
|
||||
const allowedModels = config.allowedExpModels
|
||||
?.split(",")
|
||||
.map(model => model.trim())
|
||||
.filter(model => model.length > 0) || [];
|
||||
|
||||
const isAllowed = allowedModels.some(allowedModel =>
|
||||
modelId.toLowerCase() === allowedModel.toLowerCase()
|
||||
);
|
||||
|
||||
if (isAllowed) {
|
||||
req.log.info({ modelId }, "Allowing experimental Google AI model via allowlist.");
|
||||
return; // Allow the request to proceed
|
||||
}
|
||||
|
||||
req.log.warn({ modelId }, "Blocking request to experimental Google AI model.");
|
||||
const err: any = new Error("Experimental models are too unstable to be supported in proxy code. Please use preview models instead.");
|
||||
err.statusCode = 400;
|
||||
throw err;
|
||||
}
|
||||
// If no experimental model, do nothing, allowing request to proceed.
|
||||
}
|
||||
|
||||
// Native Google AI chat completion endpoint
|
||||
googleAIRouter.post(
|
||||
"/:apiVersion(v1alpha|v1beta)/models/:modelId:(generateContent|streamGenerateContent)",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "google-ai", outApi: "google-ai", service: "google-ai" },
|
||||
{
|
||||
beforeTransform: [maybeReassignModel],
|
||||
afterTransform: [checkAndBlockExperimentalModels, setStreamFlag, processThinkingBudget, removeSafetySettingsForImageModels]
|
||||
}
|
||||
),
|
||||
googleAIProxy
|
||||
);
|
||||
|
||||
// OpenAI-to-Google AI compatibility endpoint.
|
||||
googleAIRouter.post(
|
||||
"/v1/chat/completions",
|
||||
ipLimiter,
|
||||
createPreprocessorMiddleware(
|
||||
{ inApi: "openai", outApi: "google-ai", service: "google-ai" },
|
||||
{
|
||||
afterTransform: [maybeReassignModel, checkAndBlockExperimentalModels, processThinkingBudget, removeSafetySettingsForImageModels]
|
||||
}
|
||||
),
|
||||
googleAIProxy
|
||||
);
|
||||
|
||||
export const googleAI = googleAIRouter;
|
||||
@@ -0,0 +1,323 @@
|
||||
import { Request, Response } from "express";
|
||||
import http from "http";
|
||||
import { Socket } from "net";
|
||||
import { ZodError } from "zod";
|
||||
import { generateErrorMessage } from "zod-error";
|
||||
import { HttpError } from "../../shared/errors";
|
||||
import { assertNever } from "../../shared/utils";
|
||||
import { QuotaExceededError } from "./request/preprocessors/apply-quota-limits";
|
||||
import { sendErrorToClient } from "./response/error-generator";
|
||||
|
||||
const OPENAI_CHAT_COMPLETION_ENDPOINT = "/v1/chat/completions";
|
||||
const OPENAI_TEXT_COMPLETION_ENDPOINT = "/v1/completions";
|
||||
const OPENAI_EMBEDDINGS_ENDPOINT = "/v1/embeddings";
|
||||
const OPENAI_IMAGE_COMPLETION_ENDPOINT = "/v1/images/generations";
|
||||
const OPENAI_RESPONSES_ENDPOINT = "/v1/responses";
|
||||
const ANTHROPIC_COMPLETION_ENDPOINT = "/v1/complete";
|
||||
const ANTHROPIC_MESSAGES_ENDPOINT = "/v1/messages";
|
||||
const ANTHROPIC_SONNET_COMPAT_ENDPOINT = "/v1/sonnet";
|
||||
const ANTHROPIC_OPUS_COMPAT_ENDPOINT = "/v1/opus";
|
||||
const GOOGLE_AI_ALPHA_COMPLETION_ENDPOINT = "/v1alpha/models";
|
||||
const GOOGLE_AI_BETA_COMPLETION_ENDPOINT = "/v1beta/models";
|
||||
|
||||
export function isTextGenerationRequest(req: Request) {
|
||||
return (
|
||||
req.method === "POST" &&
|
||||
[
|
||||
OPENAI_CHAT_COMPLETION_ENDPOINT,
|
||||
OPENAI_TEXT_COMPLETION_ENDPOINT,
|
||||
OPENAI_RESPONSES_ENDPOINT,
|
||||
ANTHROPIC_COMPLETION_ENDPOINT,
|
||||
ANTHROPIC_MESSAGES_ENDPOINT,
|
||||
ANTHROPIC_SONNET_COMPAT_ENDPOINT,
|
||||
ANTHROPIC_OPUS_COMPAT_ENDPOINT,
|
||||
GOOGLE_AI_ALPHA_COMPLETION_ENDPOINT,
|
||||
GOOGLE_AI_BETA_COMPLETION_ENDPOINT,
|
||||
].some((endpoint) => req.path.startsWith(endpoint))
|
||||
);
|
||||
}
|
||||
|
||||
export function isImageGenerationRequest(req: Request) {
|
||||
return (
|
||||
req.method === "POST" &&
|
||||
req.path.startsWith(OPENAI_IMAGE_COMPLETION_ENDPOINT)
|
||||
);
|
||||
}
|
||||
|
||||
export function isEmbeddingsRequest(req: Request) {
|
||||
return (
|
||||
req.method === "POST" && req.path.startsWith(OPENAI_EMBEDDINGS_ENDPOINT)
|
||||
);
|
||||
}
|
||||
|
||||
export function sendProxyError(
|
||||
req: Request,
|
||||
res: Response,
|
||||
statusCode: number,
|
||||
statusMessage: string,
|
||||
errorPayload: Record<string, any>
|
||||
) {
|
||||
const msg =
|
||||
statusCode === 500
|
||||
? `The proxy encountered an error while trying to process your prompt.`
|
||||
: `The proxy encountered an error while trying to send your prompt to the API.`;
|
||||
|
||||
sendErrorToClient({
|
||||
options: {
|
||||
format: req.inboundApi,
|
||||
title: `Proxy error (HTTP ${statusCode} ${statusMessage})`,
|
||||
message: `${msg} Further details are provided below.`,
|
||||
obj: errorPayload,
|
||||
reqId: req.id,
|
||||
model: req.body?.model,
|
||||
},
|
||||
req,
|
||||
res,
|
||||
});
|
||||
}
|
||||
|
||||
/**
|
||||
* Handles errors thrown during preparation of a proxy request (before it is
|
||||
* sent to the upstream API), typically due to validation, quota, or other
|
||||
* pre-flight checks. Depending on the error class, this function will send an
|
||||
* appropriate error response to the client, streaming it if necessary.
|
||||
*/
|
||||
export const classifyErrorAndSend = (
|
||||
err: Error,
|
||||
req: Request,
|
||||
res: Response | Socket
|
||||
) => {
|
||||
if (res instanceof Socket) {
|
||||
// We should always have an Express response object here, but http-proxy's
|
||||
// ErrorCallback type says it could be just a Socket.
|
||||
req.log.error(err, "Caught error while proxying request to target but cannot send error response to client.");
|
||||
return res.destroy();
|
||||
}
|
||||
try {
|
||||
const { statusCode, statusMessage, userMessage, ...errorDetails } =
|
||||
classifyError(err);
|
||||
sendProxyError(req, res, statusCode, statusMessage, {
|
||||
error: { message: userMessage, ...errorDetails },
|
||||
});
|
||||
} catch (error) {
|
||||
req.log.error(error, `Error writing error response headers, giving up.`);
|
||||
res.end();
|
||||
}
|
||||
};
|
||||
|
||||
function classifyError(err: Error): {
|
||||
/** HTTP status code returned to the client. */
|
||||
statusCode: number;
|
||||
/** HTTP status message returned to the client. */
|
||||
statusMessage: string;
|
||||
/** Message displayed to the user. */
|
||||
userMessage: string;
|
||||
/** Short error type, e.g. "proxy_validation_error". */
|
||||
type: string;
|
||||
} & Record<string, any> {
|
||||
const defaultError = {
|
||||
statusCode: 500,
|
||||
statusMessage: "Internal Server Error",
|
||||
userMessage: `Reverse proxy error: ${err.message}`,
|
||||
type: "proxy_internal_error",
|
||||
stack: err.stack,
|
||||
};
|
||||
|
||||
switch (err.constructor.name) {
|
||||
case "HttpError":
|
||||
const statusCode = (err as HttpError).status;
|
||||
return {
|
||||
statusCode,
|
||||
statusMessage: `HTTP ${statusCode} ${http.STATUS_CODES[statusCode]}`,
|
||||
userMessage: `Reverse proxy error: ${err.message}`,
|
||||
type: "proxy_http_error",
|
||||
};
|
||||
case "BadRequestError":
|
||||
return {
|
||||
statusCode: 400,
|
||||
statusMessage: "Bad Request",
|
||||
userMessage: `Request is not valid. (${err.message})`,
|
||||
type: "proxy_bad_request",
|
||||
};
|
||||
case "NotFoundError":
|
||||
return {
|
||||
statusCode: 404,
|
||||
statusMessage: "Not Found",
|
||||
userMessage: `Requested resource not found. (${err.message})`,
|
||||
type: "proxy_not_found",
|
||||
};
|
||||
case "PaymentRequiredError":
|
||||
return {
|
||||
statusCode: 402,
|
||||
statusMessage: "No Keys Available",
|
||||
userMessage: err.message,
|
||||
type: "proxy_no_keys_available",
|
||||
};
|
||||
case "ZodError":
|
||||
const userMessage = generateErrorMessage((err as ZodError).issues, {
|
||||
prefix: "Request validation failed. ",
|
||||
path: { enabled: true, label: null, type: "breadcrumbs" },
|
||||
code: { enabled: false },
|
||||
maxErrors: 3,
|
||||
transform: ({ issue, ...rest }) => {
|
||||
return `At '${rest.pathComponent}': ${issue.message}`;
|
||||
},
|
||||
});
|
||||
return {
|
||||
statusCode: 400,
|
||||
statusMessage: "Bad Request",
|
||||
userMessage,
|
||||
type: "proxy_validation_error",
|
||||
};
|
||||
case "ZoomerForbiddenError":
|
||||
// Mimics a ban notice from OpenAI, thrown when blockZoomerOrigins blocks
|
||||
// a request.
|
||||
return {
|
||||
statusCode: 403,
|
||||
statusMessage: "Forbidden",
|
||||
userMessage: `Your account has been disabled for violating our terms of service.`,
|
||||
type: "organization_account_disabled",
|
||||
code: "policy_violation",
|
||||
};
|
||||
case "ForbiddenError":
|
||||
return {
|
||||
statusCode: 403,
|
||||
statusMessage: "Forbidden",
|
||||
userMessage: `Request is not allowed. (${err.message})`,
|
||||
type: "proxy_forbidden",
|
||||
};
|
||||
case "QuotaExceededError":
|
||||
return {
|
||||
statusCode: 429,
|
||||
statusMessage: "Too Many Requests",
|
||||
userMessage: `You've exceeded your token quota for this model type.`,
|
||||
type: "proxy_quota_exceeded",
|
||||
info: (err as QuotaExceededError).quotaInfo,
|
||||
};
|
||||
case "Error":
|
||||
if ("code" in err) {
|
||||
switch (err.code) {
|
||||
case "ENOTFOUND":
|
||||
return {
|
||||
statusCode: 502,
|
||||
statusMessage: "Bad Gateway",
|
||||
userMessage: `Reverse proxy encountered a DNS error while trying to connect to the upstream service.`,
|
||||
type: "proxy_network_error",
|
||||
code: err.code,
|
||||
};
|
||||
case "ECONNREFUSED":
|
||||
return {
|
||||
statusCode: 502,
|
||||
statusMessage: "Bad Gateway",
|
||||
userMessage: `Reverse proxy couldn't connect to the upstream service.`,
|
||||
type: "proxy_network_error",
|
||||
code: err.code,
|
||||
};
|
||||
case "ECONNRESET":
|
||||
return {
|
||||
statusCode: 504,
|
||||
statusMessage: "Gateway Timeout",
|
||||
userMessage: `Reverse proxy timed out while waiting for the upstream service to respond.`,
|
||||
type: "proxy_network_error",
|
||||
code: err.code,
|
||||
};
|
||||
}
|
||||
}
|
||||
return defaultError;
|
||||
default:
|
||||
return defaultError;
|
||||
}
|
||||
}
|
||||
|
||||
export function getCompletionFromBody(req: Request, body: Record<string, any>) {
|
||||
const format = req.outboundApi;
|
||||
switch (format) {
|
||||
case "openai":
|
||||
case "mistral-ai":
|
||||
// Few possible values:
|
||||
// - choices[0].message.content
|
||||
// - choices[0].message with no content if model is invoking a tool
|
||||
return body.choices?.[0]?.message?.content || "";
|
||||
case "openai-responses":
|
||||
// Handle the original Responses API format
|
||||
if (body.output && Array.isArray(body.output)) {
|
||||
// Look for a message type in the output array
|
||||
for (const item of body.output) {
|
||||
if (item.type === "message" && item.content && Array.isArray(item.content)) {
|
||||
// Extract text content from each content item
|
||||
return item.content
|
||||
.filter((contentItem: any) => contentItem.type === "output_text")
|
||||
.map((contentItem: any) => contentItem.text)
|
||||
.join("");
|
||||
}
|
||||
}
|
||||
}
|
||||
// If we've been transformed to chat completion format already
|
||||
return body.choices?.[0]?.message?.content || "";
|
||||
case "mistral-text":
|
||||
return body.outputs?.[0]?.text || "";
|
||||
case "openai-text":
|
||||
return body.choices[0].text;
|
||||
case "anthropic-chat":
|
||||
if (!body.content) {
|
||||
req.log.error(
|
||||
{ body: JSON.stringify(body) },
|
||||
"Received empty Anthropic chat completion"
|
||||
);
|
||||
return "";
|
||||
}
|
||||
return body.content
|
||||
.map(({ text, type }: { type: string; text: string }) =>
|
||||
type === "text" ? text : `[Unsupported content type: ${type}]`
|
||||
)
|
||||
.join("\n");
|
||||
case "anthropic-text":
|
||||
if (!body.completion) {
|
||||
req.log.error(
|
||||
{ body: JSON.stringify(body) },
|
||||
"Received empty Anthropic text completion"
|
||||
);
|
||||
return "";
|
||||
}
|
||||
return body.completion.trim();
|
||||
case "google-ai":
|
||||
if ("choices" in body) {
|
||||
return body.choices[0].message.content;
|
||||
}
|
||||
const text = body.candidates[0].content?.parts?.[0]?.text;
|
||||
if (!text) {
|
||||
req.log.warn(
|
||||
{ body: JSON.stringify(body) },
|
||||
"Received empty Google AI text completion"
|
||||
);
|
||||
return "";
|
||||
}
|
||||
return text;
|
||||
case "openai-image":
|
||||
return body.data?.map((item: any) => item.url).join("\n");
|
||||
default:
|
||||
assertNever(format);
|
||||
}
|
||||
}
|
||||
|
||||
export function getModelFromBody(req: Request, resBody: Record<string, any>) {
|
||||
const format = req.outboundApi;
|
||||
switch (format) {
|
||||
case "openai":
|
||||
case "openai-text":
|
||||
case "openai-responses":
|
||||
return resBody.model;
|
||||
case "mistral-ai":
|
||||
case "mistral-text":
|
||||
case "openai-image":
|
||||
case "google-ai":
|
||||
// These formats don't have a model in the response body.
|
||||
return req.body.model;
|
||||
case "anthropic-chat":
|
||||
case "anthropic-text":
|
||||
// Anthropic confirms the model in the response, but AWS Claude doesn't.
|
||||
return resBody.model || req.body.model;
|
||||
default:
|
||||
assertNever(format);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,54 @@
|
||||
import type { Request } from "express";
|
||||
|
||||
import { ProxyReqManager } from "./proxy-req-manager";
|
||||
export {
|
||||
createPreprocessorMiddleware,
|
||||
createEmbeddingsPreprocessorMiddleware,
|
||||
} from "./preprocessor-factory";
|
||||
|
||||
// Preprocessors (runs before request is queued, usually body transformation/validation)
|
||||
export { applyQuotaLimits } from "./preprocessors/apply-quota-limits";
|
||||
export { blockZoomerOrigins } from "./preprocessors/block-zoomer-origins";
|
||||
export { countPromptTokens } from "./preprocessors/count-prompt-tokens";
|
||||
export { languageFilter } from "./preprocessors/language-filter";
|
||||
export { setApiFormat } from "./preprocessors/set-api-format";
|
||||
export { transformOutboundPayload } from "./preprocessors/transform-outbound-payload";
|
||||
export { validateContextSize } from "./preprocessors/validate-context-size";
|
||||
export { validateModelFamily } from "./preprocessors/validate-model-family";
|
||||
export { validateVision } from "./preprocessors/validate-vision";
|
||||
export { extractQwenExtraBody } from "./preprocessors/extract-qwen-extra-body";
|
||||
|
||||
// Proxy request mutators (runs every time request is dequeued, before proxying, usually for auth/signing)
|
||||
export { addKey, addKeyForEmbeddingsRequest } from "./mutators/add-key";
|
||||
export { addAzureKey } from "./mutators/add-azure-key";
|
||||
export { finalizeBody } from "./mutators/finalize-body";
|
||||
export { finalizeSignedRequest } from "./mutators/finalize-signed-request";
|
||||
export { signAwsRequest } from "./mutators/sign-aws-request";
|
||||
export { signGcpRequest } from "./mutators/sign-vertex-ai-request";
|
||||
export { stripHeaders } from "./mutators/strip-headers";
|
||||
|
||||
/**
|
||||
* Middleware that runs prior to the request being queued or handled by
|
||||
* http-proxy-middleware. You will not have access to the proxied
|
||||
* request/response objects since they have not yet been sent to the API.
|
||||
*
|
||||
* User will have been authenticated by the proxy's gatekeeper, but the request
|
||||
* won't have been assigned an upstream API key yet.
|
||||
*
|
||||
* Note that these functions only run once ever per request, even if the request
|
||||
* is automatically retried by the request queue middleware.
|
||||
*/
|
||||
export type RequestPreprocessor = (req: Request) => void | Promise<void>;
|
||||
|
||||
/**
|
||||
* Middleware that runs immediately before the request is proxied to the
|
||||
* upstream API, after dequeueing the request from the request queue.
|
||||
*
|
||||
* Because these middleware may be run multiple times per request if a retryable
|
||||
* error occurs and the request put back in the queue, they must be idempotent.
|
||||
* A change manager is provided to allow the middleware to make changes to the
|
||||
* request which can be automatically reverted.
|
||||
*/
|
||||
export type ProxyReqMutator = (
|
||||
changeManager: ProxyReqManager
|
||||
) => void | Promise<void>;
|
||||
@@ -0,0 +1,84 @@
|
||||
import {
|
||||
APIFormat,
|
||||
AzureOpenAIKey,
|
||||
keyPool,
|
||||
} from "../../../../shared/key-management";
|
||||
import { ProxyReqMutator } from "../index";
|
||||
|
||||
export const addAzureKey: ProxyReqMutator = async (manager) => {
|
||||
const req = manager.request;
|
||||
const validAPIs: APIFormat[] = ["openai", "openai-image"];
|
||||
const apisValid = [req.outboundApi, req.inboundApi].every((api) =>
|
||||
validAPIs.includes(api)
|
||||
);
|
||||
const serviceValid = req.service === "azure";
|
||||
|
||||
if (!apisValid || !serviceValid) {
|
||||
throw new Error("addAzureKey called on invalid request");
|
||||
}
|
||||
|
||||
if (!req.body?.model) {
|
||||
throw new Error("You must specify a model with your request.");
|
||||
}
|
||||
|
||||
const model = req.body.model.startsWith("azure-")
|
||||
? req.body.model
|
||||
: `azure-${req.body.model}`;
|
||||
// TODO: untracked mutation to body, I think this should just be a
|
||||
// RequestPreprocessor because we don't need to do it every dequeue.
|
||||
req.body.model = model;
|
||||
|
||||
const key = keyPool.get(model, "azure");
|
||||
manager.setKey(key);
|
||||
|
||||
// Handles the sole Azure API deviation from the OpenAI spec (that I know of)
|
||||
// TODO: this should also probably be a RequestPreprocessor
|
||||
const notNullOrUndefined = (x: any) => x !== null && x !== undefined;
|
||||
if ([req.body.logprobs, req.body.top_logprobs].some(notNullOrUndefined)) {
|
||||
// OpenAI wants logprobs: true/false and top_logprobs: number
|
||||
// Azure seems to just want to combine them into logprobs: number
|
||||
// if (typeof req.body.logprobs === "boolean") {
|
||||
// req.body.logprobs = req.body.top_logprobs || undefined;
|
||||
// delete req.body.top_logprobs
|
||||
// }
|
||||
|
||||
// Temporarily just disabling logprobs for Azure because their model support
|
||||
// is random: `This model does not support the 'logprobs' parameter.`
|
||||
delete req.body.logprobs;
|
||||
delete req.body.top_logprobs;
|
||||
}
|
||||
|
||||
req.log.info(
|
||||
{ key: key.hash, model },
|
||||
"Assigned Azure OpenAI key to request"
|
||||
);
|
||||
|
||||
const cred = req.key as AzureOpenAIKey;
|
||||
const { resourceName, deploymentId, apiKey } = getCredentialsFromKey(cred);
|
||||
|
||||
const operation =
|
||||
req.outboundApi === "openai" ? "/chat/completions" : "/images/generations";
|
||||
const apiVersion =
|
||||
req.outboundApi === "openai" ? "2023-09-01-preview" : "2024-02-15-preview";
|
||||
|
||||
manager.setSignedRequest({
|
||||
method: "POST",
|
||||
protocol: "https:",
|
||||
hostname: `${resourceName}.openai.azure.com`,
|
||||
path: `/openai/deployments/${deploymentId}${operation}?api-version=${apiVersion}`,
|
||||
headers: {
|
||||
["host"]: `${resourceName}.openai.azure.com`,
|
||||
["content-type"]: "application/json",
|
||||
["api-key"]: apiKey,
|
||||
},
|
||||
body: JSON.stringify(req.body),
|
||||
});
|
||||
};
|
||||
|
||||
function getCredentialsFromKey(key: AzureOpenAIKey) {
|
||||
const [resourceName, deploymentId, apiKey] = key.key.split(":");
|
||||
if (!resourceName || !deploymentId || !apiKey) {
|
||||
throw new Error("Assigned Azure OpenAI key is not in the correct format.");
|
||||
}
|
||||
return { resourceName, deploymentId, apiKey };
|
||||
}
|
||||
@@ -0,0 +1,47 @@
|
||||
import { keyPool } from "../../../../shared/key-management";
|
||||
import { ProxyReqMutator } from "../index";
|
||||
|
||||
export const addGoogleAIKey: ProxyReqMutator = (manager) => {
|
||||
const req = manager.request;
|
||||
const inboundValid =
|
||||
req.inboundApi === "openai" || req.inboundApi === "google-ai";
|
||||
const outboundValid = req.outboundApi === "google-ai";
|
||||
|
||||
const serviceValid = req.service === "google-ai";
|
||||
if (!inboundValid || !outboundValid || !serviceValid) {
|
||||
throw new Error("addGoogleAIKey called on invalid request");
|
||||
}
|
||||
|
||||
const model = req.body.model;
|
||||
const key = keyPool.get(model, "google-ai");
|
||||
manager.setKey(key);
|
||||
|
||||
req.log.info(
|
||||
{ key: key.hash, model, stream: req.isStreaming },
|
||||
"Assigned Google AI API key to request"
|
||||
);
|
||||
|
||||
// https://generativelanguage.googleapis.com/v1beta/models/$MODEL_ID:generateContent?key=$API_KEY
|
||||
// https://generativelanguage.googleapis.com/v1beta/models/$MODEL_ID:streamGenerateContent?key=${API_KEY}
|
||||
const payload = { ...req.body, stream: undefined, model: undefined };
|
||||
|
||||
// For OpenAI -> Google conversion we don't actually have the API version
|
||||
const apiVersion = req.params.apiVersion || "v1beta"
|
||||
|
||||
// TODO: this isn't actually signed, so the manager api is a little unclear
|
||||
// with the ProxyReqManager refactor, it's probably no longer necesasry to
|
||||
// do this because we can modify the path using Manager.setPath.
|
||||
manager.setSignedRequest({
|
||||
method: "POST",
|
||||
protocol: "https:",
|
||||
hostname: "generativelanguage.googleapis.com",
|
||||
path: `/${apiVersion}/models/${model}:${
|
||||
req.isStreaming ? "streamGenerateContent?alt=sse&" : "generateContent?"
|
||||
}key=${key.key}`,
|
||||
headers: {
|
||||
["host"]: `generativelanguage.googleapis.com`,
|
||||
["content-type"]: "application/json",
|
||||
},
|
||||
body: JSON.stringify(payload),
|
||||
});
|
||||
};
|
||||
@@ -0,0 +1,155 @@
|
||||
import { AnthropicChatMessage } from "../../../../shared/api-schemas";
|
||||
import { containsImageContent } from "../../../../shared/api-schemas/anthropic";
|
||||
import { Key, OpenAIKey, keyPool } from "../../../../shared/key-management";
|
||||
import { isEmbeddingsRequest } from "../../common";
|
||||
import { assertNever } from "../../../../shared/utils";
|
||||
import { ProxyReqMutator } from "../index";
|
||||
|
||||
export const addKey: ProxyReqMutator = (manager) => {
|
||||
const req = manager.request;
|
||||
|
||||
let assignedKey: Key;
|
||||
const { service, inboundApi, outboundApi, body } = req;
|
||||
|
||||
if (!inboundApi || !outboundApi) {
|
||||
const err = new Error(
|
||||
"Request API format missing. Did you forget to add the request preprocessor to your router?"
|
||||
);
|
||||
req.log.error({ inboundApi, outboundApi, path: req.path }, err.message);
|
||||
throw err;
|
||||
}
|
||||
|
||||
if (!body?.model) {
|
||||
throw new Error("You must specify a model with your request.");
|
||||
}
|
||||
|
||||
let needsMultimodal = false;
|
||||
if (outboundApi === "anthropic-chat") {
|
||||
needsMultimodal = containsImageContent(
|
||||
body.messages as AnthropicChatMessage[]
|
||||
);
|
||||
}
|
||||
|
||||
if (inboundApi === outboundApi) {
|
||||
// Pass streaming information for GPT-5 models that require verified keys for streaming
|
||||
const isStreaming = body.stream === true;
|
||||
assignedKey = keyPool.get(body.model, service, needsMultimodal, isStreaming);
|
||||
} else {
|
||||
switch (outboundApi) {
|
||||
// If we are translating between API formats we may need to select a model
|
||||
// for the user, because the provided model is for the inbound API.
|
||||
// TODO: This whole else condition is probably no longer needed since API
|
||||
// translation now reassigns the model earlier in the request pipeline.
|
||||
case "anthropic-text":
|
||||
case "anthropic-chat":
|
||||
case "mistral-ai":
|
||||
case "mistral-text":
|
||||
case "google-ai":
|
||||
assignedKey = keyPool.get(body.model, service);
|
||||
break;
|
||||
case "openai-text":
|
||||
assignedKey = keyPool.get("gpt-3.5-turbo-instruct", service);
|
||||
break;
|
||||
case "openai-image":
|
||||
// Use the actual model from the request body instead of defaulting to dall-e-3
|
||||
// This ensures that gpt-image-1 requests get keys that are verified for gpt-image-1
|
||||
assignedKey = keyPool.get(body.model, service);
|
||||
break;
|
||||
case "openai-responses":
|
||||
assignedKey = keyPool.get(body.model, service);
|
||||
break;
|
||||
case "openai":
|
||||
throw new Error(
|
||||
`Outbound API ${outboundApi} is not supported for ${inboundApi}`
|
||||
);
|
||||
default:
|
||||
assertNever(outboundApi);
|
||||
}
|
||||
}
|
||||
|
||||
manager.setKey(assignedKey);
|
||||
req.log.info(
|
||||
{ key: assignedKey.hash, model: body.model, inboundApi, outboundApi },
|
||||
"Assigned key to request"
|
||||
);
|
||||
|
||||
// TODO: KeyProvider should assemble all necessary headers
|
||||
switch (assignedKey.service) {
|
||||
case "anthropic":
|
||||
manager.setHeader("X-API-Key", assignedKey.key);
|
||||
if (!manager.request.headers["anthropic-version"]) {
|
||||
manager.setHeader("anthropic-version", "2023-06-01");
|
||||
}
|
||||
break;
|
||||
case "openai":
|
||||
const key: OpenAIKey = assignedKey as OpenAIKey;
|
||||
if (key.organizationId && !key.key.includes("svcacct")) {
|
||||
manager.setHeader("OpenAI-Organization", key.organizationId);
|
||||
}
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "mistral-ai":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "azure":
|
||||
const azureKey = assignedKey.key;
|
||||
manager.setHeader("api-key", azureKey);
|
||||
break;
|
||||
case "deepseek":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "xai":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "cohere":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "qwen":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "glm":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "moonshot":
|
||||
manager.setHeader("Authorization", `Bearer ${assignedKey.key}`);
|
||||
break;
|
||||
case "aws":
|
||||
case "gcp":
|
||||
case "google-ai":
|
||||
throw new Error("add-key should not be used for this service.");
|
||||
default:
|
||||
assertNever(assignedKey.service);
|
||||
}
|
||||
};
|
||||
|
||||
/**
|
||||
* Special case for embeddings requests which don't go through the normal
|
||||
* request pipeline.
|
||||
*/
|
||||
export const addKeyForEmbeddingsRequest: ProxyReqMutator = (manager) => {
|
||||
const req = manager.request;
|
||||
if (!isEmbeddingsRequest(req)) {
|
||||
throw new Error(
|
||||
"addKeyForEmbeddingsRequest called on non-embeddings request"
|
||||
);
|
||||
}
|
||||
|
||||
if (req.inboundApi !== "openai") {
|
||||
throw new Error("Embeddings requests must be from OpenAI");
|
||||
}
|
||||
|
||||
manager.setBody({ input: req.body.input, model: "text-embedding-ada-002" });
|
||||
|
||||
const key = keyPool.get("text-embedding-ada-002", "openai") as OpenAIKey;
|
||||
|
||||
manager.setKey(key);
|
||||
req.log.info(
|
||||
{ key: key.hash, toApi: req.outboundApi },
|
||||
"Assigned Turbo key to embeddings request"
|
||||
);
|
||||
|
||||
manager.setHeader("Authorization", `Bearer ${key.key}`);
|
||||
if (key.organizationId) {
|
||||
manager.setHeader("OpenAI-Organization", key.organizationId);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,67 @@
|
||||
import type { ProxyReqMutator } from "../index";
|
||||
|
||||
/** Finalize the rewritten request body. Must be the last mutator. */
|
||||
export const finalizeBody: ProxyReqMutator = (manager) => {
|
||||
const req = manager.request;
|
||||
|
||||
if (["POST", "PUT", "PATCH"].includes(req.method ?? "") && req.body) {
|
||||
// For image generation requests, remove stream flag.
|
||||
if (req.outboundApi === "openai-image") {
|
||||
delete req.body.stream;
|
||||
}
|
||||
// For anthropic text to chat requests, remove undefined prompt.
|
||||
if (req.outboundApi === "anthropic-chat") {
|
||||
delete req.body.prompt;
|
||||
}
|
||||
// For OpenAI Responses API, ensure messages is in the correct format
|
||||
if (req.outboundApi === "openai-responses") {
|
||||
// Format messages for the Responses API
|
||||
if (req.body.messages) {
|
||||
req.log.info("Formatting messages for Responses API in finalizeBody");
|
||||
// The Responses API expects input to be an array, not an object
|
||||
req.body.input = req.body.messages;
|
||||
delete req.body.messages;
|
||||
} else if (req.body.input && req.body.input.messages) {
|
||||
req.log.info("Reformatting input.messages for Responses API in finalizeBody");
|
||||
// If input already exists but contains a messages object, replace input with the messages array
|
||||
req.body.input = req.body.input.messages;
|
||||
}
|
||||
|
||||
// Final check to ensure max_completion_tokens is converted to max_output_tokens
|
||||
if (req.body.max_completion_tokens) {
|
||||
req.log.info("Converting max_completion_tokens to max_output_tokens in finalizeBody");
|
||||
if (!req.body.max_output_tokens) {
|
||||
req.body.max_output_tokens = req.body.max_completion_tokens;
|
||||
}
|
||||
delete req.body.max_completion_tokens;
|
||||
}
|
||||
|
||||
// Final check to ensure max_tokens is converted to max_output_tokens
|
||||
if (req.body.max_tokens) {
|
||||
req.log.info("Converting max_tokens to max_output_tokens in finalizeBody");
|
||||
if (!req.body.max_output_tokens) {
|
||||
req.body.max_output_tokens = req.body.max_tokens;
|
||||
}
|
||||
delete req.body.max_tokens;
|
||||
}
|
||||
|
||||
// Remove all parameters not supported by Responses API
|
||||
const unsupportedParams = [
|
||||
'frequency_penalty',
|
||||
'presence_penalty',
|
||||
];
|
||||
|
||||
for (const param of unsupportedParams) {
|
||||
if (req.body[param] !== undefined) {
|
||||
req.log.info(`Removing unsupported parameter for Responses API: ${param}`);
|
||||
delete req.body[param];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const serialized =
|
||||
typeof req.body === "string" ? req.body : JSON.stringify(req.body);
|
||||
manager.setHeader("Content-Length", String(Buffer.byteLength(serialized)));
|
||||
manager.setBody(serialized);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,32 @@
|
||||
import { ProxyReqMutator } from "../index";
|
||||
|
||||
/**
|
||||
* For AWS/GCP/Azure/Google requests, the body is signed earlier in the request
|
||||
* pipeline, before the proxy middleware. This function just assigns the path
|
||||
* and headers to the proxy request.
|
||||
*/
|
||||
export const finalizeSignedRequest: ProxyReqMutator = (manager) => {
|
||||
const req = manager.request;
|
||||
if (!req.signedRequest) {
|
||||
throw new Error("Expected req.signedRequest to be set");
|
||||
}
|
||||
|
||||
// The path depends on the selected model and the assigned key's region.
|
||||
manager.setPath(req.signedRequest.path);
|
||||
|
||||
// Amazon doesn't want extra headers, so we need to remove all of them and
|
||||
// reassign only the ones specified in the signed request.
|
||||
const headers = req.signedRequest.headers;
|
||||
Object.keys(headers).forEach((key) => {
|
||||
manager.removeHeader(key);
|
||||
});
|
||||
Object.entries(req.signedRequest.headers).forEach(([key, value]) => {
|
||||
manager.setHeader(key, value);
|
||||
});
|
||||
const serialized =
|
||||
typeof req.signedRequest.body === "string"
|
||||
? req.signedRequest.body
|
||||
: JSON.stringify(req.signedRequest.body);
|
||||
manager.setHeader("Content-Length", String(Buffer.byteLength(serialized)));
|
||||
manager.setBody(serialized);
|
||||
};
|
||||
@@ -0,0 +1,159 @@
|
||||
import express, { Request } from "express";
|
||||
import { Sha256 } from "@aws-crypto/sha256-js";
|
||||
import { SignatureV4 } from "@smithy/signature-v4";
|
||||
import { HttpRequest } from "@smithy/protocol-http";
|
||||
import {
|
||||
AnthropicV1TextSchema,
|
||||
AnthropicV1MessagesSchema,
|
||||
} from "../../../../shared/api-schemas";
|
||||
import { AwsBedrockKey, keyPool } from "../../../../shared/key-management";
|
||||
import {
|
||||
AWSMistralV1ChatCompletionsSchema,
|
||||
AWSMistralV1TextCompletionsSchema,
|
||||
} from "../../../../shared/api-schemas/mistral-ai";
|
||||
import { ProxyReqMutator } from "../index";
|
||||
|
||||
const AMZ_HOST =
|
||||
process.env.AMZ_HOST || "bedrock-runtime.%REGION%.amazonaws.com";
|
||||
|
||||
/**
|
||||
* Signs an outgoing AWS request with the appropriate headers modifies the
|
||||
* request object in place to fix the path.
|
||||
* This happens AFTER request transformation.
|
||||
*/
|
||||
export const signAwsRequest: ProxyReqMutator = async (manager) => {
|
||||
const req = manager.request;
|
||||
const { model, stream } = req.body;
|
||||
const key = keyPool.get(model, "aws") as AwsBedrockKey;
|
||||
manager.setKey(key);
|
||||
|
||||
let system = req.body.system ?? "";
|
||||
if (Array.isArray(system)) {
|
||||
system = system
|
||||
.map((m: { type: string; text: string }) => m.text)
|
||||
.join("\n");
|
||||
req.body.system = system;
|
||||
}
|
||||
|
||||
const credential = getCredentialParts(req);
|
||||
const host = AMZ_HOST.replace("%REGION%", credential.region);
|
||||
|
||||
// AWS only uses 2023-06-01 and does not actually check this header, but we
|
||||
// set it so that the stream adapter always selects the correct transformer.
|
||||
manager.setHeader("anthropic-version", "2023-06-01");
|
||||
|
||||
// If our key has an inference profile compatible with the requested model,
|
||||
// we want to use the inference profile instead of the model ID when calling
|
||||
// InvokeModel as that will give us higher rate limits.
|
||||
const profile =
|
||||
key.inferenceProfileIds.find((p) => p.includes(model)) || model;
|
||||
|
||||
// Uses the AWS SDK to sign a request, then modifies our HPM proxy request
|
||||
// with the headers generated by the SDK.
|
||||
const newRequest = new HttpRequest({
|
||||
method: "POST",
|
||||
protocol: "https:",
|
||||
hostname: host,
|
||||
path: `/model/${profile}/invoke${stream ? "-with-response-stream" : ""}`,
|
||||
headers: {
|
||||
["Host"]: host,
|
||||
["content-type"]: "application/json",
|
||||
},
|
||||
body: JSON.stringify(getStrictlyValidatedBodyForAws(req)),
|
||||
});
|
||||
|
||||
if (stream) {
|
||||
newRequest.headers["x-amzn-bedrock-accept"] = "application/json";
|
||||
} else {
|
||||
newRequest.headers["accept"] = "*/*";
|
||||
}
|
||||
|
||||
const { body, inboundApi, outboundApi } = req;
|
||||
req.log.info(
|
||||
{ key: key.hash, model: body.model, profile, inboundApi, outboundApi },
|
||||
"Assigned AWS credentials to request"
|
||||
);
|
||||
|
||||
manager.setSignedRequest(await sign(newRequest, getCredentialParts(req)));
|
||||
};
|
||||
|
||||
type Credential = {
|
||||
accessKeyId: string;
|
||||
secretAccessKey: string;
|
||||
region: string;
|
||||
};
|
||||
|
||||
function getCredentialParts(req: express.Request): Credential {
|
||||
const [accessKeyId, secretAccessKey, region] = req.key!.key.split(":");
|
||||
|
||||
if (!accessKeyId || !secretAccessKey || !region) {
|
||||
req.log.error(
|
||||
{ key: req.key!.hash },
|
||||
"AWS_CREDENTIALS isn't correctly formatted; refer to the docs"
|
||||
);
|
||||
throw new Error("The key assigned to this request is invalid.");
|
||||
}
|
||||
|
||||
return { accessKeyId, secretAccessKey, region };
|
||||
}
|
||||
|
||||
async function sign(request: HttpRequest, credential: Credential) {
|
||||
const { accessKeyId, secretAccessKey, region } = credential;
|
||||
|
||||
const signer = new SignatureV4({
|
||||
sha256: Sha256,
|
||||
credentials: { accessKeyId, secretAccessKey },
|
||||
region,
|
||||
service: "bedrock",
|
||||
});
|
||||
|
||||
return signer.sign(request);
|
||||
}
|
||||
|
||||
function getStrictlyValidatedBodyForAws(req: Readonly<Request>): unknown {
|
||||
// AWS uses vendor API formats but imposes additional (more strict) validation
|
||||
// rules, namely that extraneous parameters are not allowed. We will validate
|
||||
// using the vendor's zod schema but apply `.strip` to ensure that any
|
||||
// extraneous parameters are removed.
|
||||
let strippedParams: Record<string, unknown> = {};
|
||||
switch (req.outboundApi) {
|
||||
case "anthropic-text":
|
||||
strippedParams = AnthropicV1TextSchema.pick({
|
||||
prompt: true,
|
||||
max_tokens_to_sample: true,
|
||||
stop_sequences: true,
|
||||
temperature: true,
|
||||
top_k: true,
|
||||
top_p: true,
|
||||
})
|
||||
.strip()
|
||||
.parse(req.body);
|
||||
break;
|
||||
case "anthropic-chat":
|
||||
strippedParams = AnthropicV1MessagesSchema.pick({
|
||||
messages: true,
|
||||
system: true,
|
||||
max_tokens: true,
|
||||
stop_sequences: true,
|
||||
temperature: true,
|
||||
top_k: true,
|
||||
top_p: true,
|
||||
tools: true,
|
||||
tool_choice: true,
|
||||
thinking: true
|
||||
})
|
||||
.strip()
|
||||
.parse(req.body);
|
||||
strippedParams.anthropic_version = "bedrock-2023-05-31";
|
||||
break;
|
||||
case "mistral-ai":
|
||||
strippedParams = AWSMistralV1ChatCompletionsSchema.parse(req.body);
|
||||
break;
|
||||
case "mistral-text":
|
||||
strippedParams = AWSMistralV1TextCompletionsSchema.parse(req.body);
|
||||
break;
|
||||
default:
|
||||
throw new Error("Unexpected outbound API for AWS.");
|
||||
}
|
||||
return strippedParams;
|
||||
}
|
||||
@@ -0,0 +1,78 @@
|
||||
import { AnthropicV1MessagesSchema } from "../../../../shared/api-schemas";
|
||||
import { GcpKey, keyPool } from "../../../../shared/key-management";
|
||||
import { ProxyReqMutator } from "../index";
|
||||
import {
|
||||
getCredentialsFromGcpKey,
|
||||
refreshGcpAccessToken,
|
||||
} from "../../../../shared/key-management/gcp/oauth";
|
||||
|
||||
const GCP_HOST = process.env.GCP_HOST || "%REGION%-aiplatform.googleapis.com";
|
||||
|
||||
export const signGcpRequest: ProxyReqMutator = async (manager) => {
|
||||
const req = manager.request;
|
||||
const serviceValid = req.service === "gcp";
|
||||
if (!serviceValid) {
|
||||
throw new Error("addVertexAIKey called on invalid request");
|
||||
}
|
||||
|
||||
if (!req.body?.model) {
|
||||
throw new Error("You must specify a model with your request.");
|
||||
}
|
||||
|
||||
const { model } = req.body;
|
||||
const key: GcpKey = keyPool.get(model, "gcp") as GcpKey;
|
||||
|
||||
if (!key.accessToken || Date.now() > key.accessTokenExpiresAt) {
|
||||
const [token, durationSec] = await refreshGcpAccessToken(key);
|
||||
keyPool.update(key, {
|
||||
accessToken: token,
|
||||
accessTokenExpiresAt: Date.now() + durationSec * 1000 * 0.95,
|
||||
} as GcpKey);
|
||||
// nb: key received by `get` is a clone and will not have the new access
|
||||
// token we just set, so it must be manually updated.
|
||||
key.accessToken = token;
|
||||
}
|
||||
|
||||
manager.setKey(key);
|
||||
req.log.info({ key: key.hash, model }, "Assigned GCP key to request");
|
||||
|
||||
// TODO: This should happen in transform-outbound-payload.ts
|
||||
// TODO: Support tools
|
||||
let strippedParams: Record<string, unknown>;
|
||||
strippedParams = AnthropicV1MessagesSchema.pick({
|
||||
messages: true,
|
||||
system: true,
|
||||
max_tokens: true,
|
||||
stop_sequences: true,
|
||||
temperature: true,
|
||||
top_k: true,
|
||||
top_p: true,
|
||||
stream: true,
|
||||
tools: true,
|
||||
tool_choice: true,
|
||||
thinking: true
|
||||
})
|
||||
.strip()
|
||||
.parse(req.body);
|
||||
strippedParams.anthropic_version = "vertex-2023-10-16";
|
||||
|
||||
const credential = await getCredentialsFromGcpKey(key);
|
||||
|
||||
const host = GCP_HOST.replace("%REGION%", credential.region);
|
||||
// GCP doesn't use the anthropic-version header, but we set it to ensure the
|
||||
// stream adapter selects the correct transformer.
|
||||
manager.setHeader("anthropic-version", "2023-06-01");
|
||||
|
||||
manager.setSignedRequest({
|
||||
method: "POST",
|
||||
protocol: "https:",
|
||||
hostname: host,
|
||||
path: `/v1/projects/${credential.projectId}/locations/${credential.region}/publishers/anthropic/models/${model}:streamRawPredict`,
|
||||
headers: {
|
||||
["host"]: host,
|
||||
["content-type"]: "application/json",
|
||||
["authorization"]: `Bearer ${key.accessToken}`,
|
||||
},
|
||||
body: JSON.stringify(strippedParams),
|
||||
});
|
||||
};
|
||||
@@ -0,0 +1,33 @@
|
||||
import { ProxyReqMutator } from "../index";
|
||||
|
||||
/**
|
||||
* Removes origin and referer headers before sending the request to the API for
|
||||
* privacy reasons.
|
||||
*/
|
||||
export const stripHeaders: ProxyReqMutator = (manager) => {
|
||||
manager.removeHeader("origin");
|
||||
manager.removeHeader("referer");
|
||||
|
||||
// Some APIs refuse requests coming from browsers to discourage embedding
|
||||
// API keys in client-side code, so we must remove all CORS/fetch headers.
|
||||
Object.keys(manager.request.headers).forEach((key) => {
|
||||
if (key.startsWith("sec-")) {
|
||||
manager.removeHeader(key);
|
||||
}
|
||||
});
|
||||
|
||||
manager.removeHeader("tailscale-user-login");
|
||||
manager.removeHeader("tailscale-user-name");
|
||||
manager.removeHeader("tailscale-headers-info");
|
||||
manager.removeHeader("tailscale-user-profile-pic");
|
||||
manager.removeHeader("cf-connecting-ip");
|
||||
manager.removeHeader("cf-ray");
|
||||
manager.removeHeader("cf-visitor");
|
||||
manager.removeHeader("cf-warp-tag-id");
|
||||
manager.removeHeader("forwarded");
|
||||
manager.removeHeader("true-client-ip");
|
||||
manager.removeHeader("x-forwarded-for");
|
||||
manager.removeHeader("x-forwarded-host");
|
||||
manager.removeHeader("x-forwarded-proto");
|
||||
manager.removeHeader("x-real-ip");
|
||||
};
|
||||
@@ -0,0 +1,176 @@
|
||||
import { RequestHandler } from "express";
|
||||
import { ZodIssue } from "zod";
|
||||
import { initializeSseStream } from "../../../shared/streaming";
|
||||
import { classifyErrorAndSend } from "../common";
|
||||
import {
|
||||
RequestPreprocessor,
|
||||
blockZoomerOrigins,
|
||||
countPromptTokens,
|
||||
languageFilter,
|
||||
setApiFormat,
|
||||
transformOutboundPayload,
|
||||
validateContextSize,
|
||||
validateModelFamily,
|
||||
validateVision,
|
||||
applyQuotaLimits,
|
||||
} from ".";
|
||||
|
||||
type RequestPreprocessorOptions = {
|
||||
/**
|
||||
* Functions to run before the request body is transformed between API
|
||||
* formats. Use this to change the behavior of the transformation, such as for
|
||||
* endpoints which can accept multiple API formats.
|
||||
*/
|
||||
beforeTransform?: RequestPreprocessor[];
|
||||
/**
|
||||
* Functions to run after the request body is transformed and token counts are
|
||||
* assigned. Use this to perform validation or other actions that depend on
|
||||
* the request body being in the final API format.
|
||||
*/
|
||||
afterTransform?: RequestPreprocessor[];
|
||||
};
|
||||
|
||||
/**
|
||||
* Returns a middleware function that processes the request body into the given
|
||||
* API format, and then sequentially runs the given additional preprocessors.
|
||||
* These should be used for validation and transformations that only need to
|
||||
* happen once per request.
|
||||
*
|
||||
* These run first in the request lifecycle, a single time per request before it
|
||||
* is added to the request queue. They aren't run again if the request is
|
||||
* re-attempted after a rate limit.
|
||||
*
|
||||
* To run functions against requests every time they are re-attempted, write a
|
||||
* ProxyReqMutator and pass it to createQueuedProxyMiddleware instead.
|
||||
*/
|
||||
export const createPreprocessorMiddleware = (
|
||||
apiFormat: Parameters<typeof setApiFormat>[0],
|
||||
{ beforeTransform, afterTransform }: RequestPreprocessorOptions = {}
|
||||
): RequestHandler => {
|
||||
const preprocessors: RequestPreprocessor[] = [
|
||||
setApiFormat(apiFormat),
|
||||
blockZoomerOrigins,
|
||||
...(beforeTransform ?? []),
|
||||
transformOutboundPayload,
|
||||
countPromptTokens,
|
||||
languageFilter,
|
||||
...(afterTransform ?? []),
|
||||
validateContextSize,
|
||||
validateVision,
|
||||
validateModelFamily,
|
||||
applyQuotaLimits,
|
||||
];
|
||||
return async (...args) => executePreprocessors(preprocessors, args);
|
||||
};
|
||||
|
||||
/**
|
||||
* Returns a middleware function that specifically prepares requests for
|
||||
* OpenAI's embeddings API. Tokens are not counted because embeddings requests
|
||||
* are basically free.
|
||||
*/
|
||||
export const createEmbeddingsPreprocessorMiddleware = (): RequestHandler => {
|
||||
const preprocessors: RequestPreprocessor[] = [
|
||||
setApiFormat({ inApi: "openai", outApi: "openai", service: "openai" }),
|
||||
(req) => void (req.promptTokens = req.outputTokens = 0),
|
||||
];
|
||||
return async (...args) => executePreprocessors(preprocessors, args);
|
||||
};
|
||||
|
||||
async function executePreprocessors(
|
||||
preprocessors: RequestPreprocessor[],
|
||||
[req, res, next]: Parameters<RequestHandler>
|
||||
) {
|
||||
handleTestMessage(req, res, next);
|
||||
if (res.headersSent) return;
|
||||
|
||||
try {
|
||||
for (const preprocessor of preprocessors) {
|
||||
await preprocessor(req);
|
||||
}
|
||||
next();
|
||||
} catch (error) {
|
||||
if (error.constructor.name === "ZodError") {
|
||||
const issues = error?.issues
|
||||
?.map((issue: ZodIssue) => `${issue.path.join(".")}: ${issue.message}`)
|
||||
.join("; ");
|
||||
req.log.warn({ issues }, "Prompt failed preprocessor validation.");
|
||||
} else {
|
||||
req.log.error(error, "Error while executing request preprocessor");
|
||||
}
|
||||
|
||||
// If the requested has opted into streaming, the client probably won't
|
||||
// handle a non-eventstream response, but we haven't initialized the SSE
|
||||
// stream yet as that is typically done later by the request queue. We'll
|
||||
// do that here and then call classifyErrorAndSend to use the streaming
|
||||
// error handler.
|
||||
const { stream } = req.body;
|
||||
const isStreaming = stream === "true" || stream === true;
|
||||
if (isStreaming && !res.headersSent) {
|
||||
initializeSseStream(res);
|
||||
}
|
||||
classifyErrorAndSend(error as Error, req, res);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Bypasses the API call and returns a test message response if the request body
|
||||
* is a known test message from SillyTavern. Otherwise these messages just waste
|
||||
* API request quota and confuse users when the proxy is busy, because ST always
|
||||
* makes them with `stream: false` (which is not allowed when the proxy is busy)
|
||||
*/
|
||||
const handleTestMessage: RequestHandler = (req, res) => {
|
||||
const { method, body } = req;
|
||||
if (method !== "POST") {
|
||||
return;
|
||||
}
|
||||
|
||||
if (isTestMessage(body)) {
|
||||
req.log.info({ body }, "Received test message. Skipping API call.");
|
||||
res.json({
|
||||
id: "test-message",
|
||||
object: "chat.completion",
|
||||
created: Date.now(),
|
||||
model: body.model,
|
||||
// openai chat
|
||||
choices: [
|
||||
{
|
||||
message: { role: "assistant", content: "Hello!" },
|
||||
finish_reason: "stop",
|
||||
index: 0,
|
||||
},
|
||||
],
|
||||
// anthropic text
|
||||
completion: "Hello!",
|
||||
// anthropic chat
|
||||
content: [{ type: "text", text: "Hello!" }],
|
||||
// gemini
|
||||
candidates: [
|
||||
{
|
||||
content: { parts: [{ text: "Hello!" }] },
|
||||
finishReason: "stop",
|
||||
},
|
||||
],
|
||||
proxy_note:
|
||||
"SillyTavern connection test detected. Your prompt was not sent to the actual model and this response was generated by the proxy.",
|
||||
});
|
||||
}
|
||||
};
|
||||
|
||||
function isTestMessage(body: any) {
|
||||
const { messages, prompt, contents } = body;
|
||||
|
||||
if (messages) {
|
||||
return (
|
||||
messages.length === 1 &&
|
||||
messages[0].role === "user" &&
|
||||
messages[0].content === "Hi"
|
||||
);
|
||||
} else if (contents) {
|
||||
return contents.length === 1 && contents[0].parts[0]?.text === "Hi";
|
||||
} else {
|
||||
return (
|
||||
prompt?.trim() === "Human: Hi\n\nAssistant:" ||
|
||||
prompt?.startsWith("Hi\n\n")
|
||||
);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,37 @@
|
||||
import { hasAvailableQuota } from "../../../../shared/users/user-store";
|
||||
import { isImageGenerationRequest, isTextGenerationRequest } from "../../common";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
export class QuotaExceededError extends Error {
|
||||
public quotaInfo: any;
|
||||
constructor(message: string, quotaInfo: any) {
|
||||
super(message);
|
||||
this.name = "QuotaExceededError";
|
||||
this.quotaInfo = quotaInfo;
|
||||
}
|
||||
}
|
||||
|
||||
export const applyQuotaLimits: RequestPreprocessor = (req) => {
|
||||
const subjectToQuota =
|
||||
isTextGenerationRequest(req) || isImageGenerationRequest(req);
|
||||
if (!subjectToQuota || !req.user) return;
|
||||
|
||||
const requestedTokens = (req.promptTokens ?? 0) + (req.outputTokens ?? 0);
|
||||
if (
|
||||
!hasAvailableQuota({
|
||||
userToken: req.user.token,
|
||||
model: req.body.model,
|
||||
api: req.outboundApi,
|
||||
requested: requestedTokens,
|
||||
})
|
||||
) {
|
||||
throw new QuotaExceededError(
|
||||
"You have exceeded your proxy token quota for this model.",
|
||||
{
|
||||
quota: req.user.tokenLimits,
|
||||
used: req.user.tokenCounts,
|
||||
requested: requestedTokens,
|
||||
}
|
||||
);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,29 @@
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
const DISALLOWED_ORIGIN_SUBSTRINGS = "janitorai.com,janitor.ai,vip.jewproxy.tech,jewproxy.tech".split(",");
|
||||
|
||||
class ZoomerForbiddenError extends Error {
|
||||
constructor(message: string) {
|
||||
super(message);
|
||||
this.name = "ZoomerForbiddenError";
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Blocks requests from Janitor AI users with a fake, scary error message so I
|
||||
* stop getting emails asking for tech support.
|
||||
*/
|
||||
export const blockZoomerOrigins: RequestPreprocessor = (req) => {
|
||||
const origin = req.headers.origin || req.headers.referer || req.headers.host;
|
||||
if (origin && DISALLOWED_ORIGIN_SUBSTRINGS.some((s) => origin.includes(s))) {
|
||||
// Venus-derivatives send a test prompt to check if the proxy is working.
|
||||
// We don't want to block that just yet.
|
||||
if (req.body.messages[0]?.content === "Just say TEST") {
|
||||
return;
|
||||
}
|
||||
|
||||
throw new ZoomerForbiddenError(
|
||||
`Your access was terminated due to violation of our policies, please check your email for more information. If you believe this is in error and would like to appeal, please contact us through our help center at help.openai.com.`
|
||||
);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,132 @@
|
||||
import { RequestPreprocessor } from "../index";
|
||||
import { countTokens } from "../../../../shared/tokenization";
|
||||
import { assertNever } from "../../../../shared/utils";
|
||||
import { OpenAIChatMessage } from "../../../../shared/api-schemas";
|
||||
import { GoogleAIChatMessage } from "../../../../shared/api-schemas/google-ai";
|
||||
import {
|
||||
AnthropicChatMessage,
|
||||
flattenAnthropicMessages,
|
||||
} from "../../../../shared/api-schemas/anthropic";
|
||||
import {
|
||||
MistralAIChatMessage,
|
||||
ContentItem,
|
||||
isMistralVisionModel
|
||||
} from "../../../../shared/api-schemas/mistral-ai";
|
||||
import { isGrokVisionModel } from "../../../../shared/api-schemas/xai";
|
||||
|
||||
/**
|
||||
* Given a request with an already-transformed body, counts the number of
|
||||
* tokens and assigns the count to the request.
|
||||
*/
|
||||
export const countPromptTokens: RequestPreprocessor = async (req) => {
|
||||
const service = req.outboundApi;
|
||||
let result;
|
||||
|
||||
switch (service) {
|
||||
case "openai": {
|
||||
req.outputTokens = req.body.max_completion_tokens || req.body.max_tokens;
|
||||
const prompt: OpenAIChatMessage[] = req.body.messages;
|
||||
result = await countTokens({ req, prompt, service });
|
||||
break;
|
||||
}
|
||||
case "openai-responses": {
|
||||
req.outputTokens = req.body.max_completion_tokens || req.body.max_tokens;
|
||||
const prompt: OpenAIChatMessage[] = req.body.messages;
|
||||
result = await countTokens({ req, prompt, service });
|
||||
break;
|
||||
}
|
||||
case "openai-text": {
|
||||
req.outputTokens = req.body.max_tokens;
|
||||
const prompt: string = req.body.prompt;
|
||||
result = await countTokens({ req, prompt, service });
|
||||
break;
|
||||
}
|
||||
case "anthropic-chat": {
|
||||
req.outputTokens = req.body.max_tokens;
|
||||
let system = req.body.system ?? "";
|
||||
if (Array.isArray(system)) {
|
||||
system = system
|
||||
.map((m: { type: string; text: string }) => m.text)
|
||||
.join("\n");
|
||||
}
|
||||
const prompt = { system, messages: req.body.messages };
|
||||
result = await countTokens({ req, prompt, service });
|
||||
break;
|
||||
}
|
||||
case "anthropic-text": {
|
||||
req.outputTokens = req.body.max_tokens_to_sample;
|
||||
const prompt: string = req.body.prompt;
|
||||
result = await countTokens({ req, prompt, service });
|
||||
break;
|
||||
}
|
||||
case "google-ai": {
|
||||
req.outputTokens = req.body.generationConfig.maxOutputTokens;
|
||||
const prompt: GoogleAIChatMessage[] = req.body.contents;
|
||||
result = await countTokens({ req, prompt, service });
|
||||
break;
|
||||
}
|
||||
case "mistral-ai":
|
||||
case "mistral-text": {
|
||||
req.outputTokens = req.body.max_tokens;
|
||||
|
||||
// Handle multimodal content (vision) in Mistral models
|
||||
const isVisionModel = isMistralVisionModel(req.body.model);
|
||||
const messages = req.body.messages;
|
||||
|
||||
// Check if this is a vision request with images
|
||||
const hasImageContent = Array.isArray(messages) && messages.some(
|
||||
(msg: MistralAIChatMessage) => Array.isArray(msg.content) &&
|
||||
msg.content.some((item: ContentItem) => item.type === "image_url")
|
||||
);
|
||||
|
||||
// For vision content, we add a fixed token count per image
|
||||
// This is an estimate as the actual token count depends on image size and complexity
|
||||
const TOKENS_PER_IMAGE = 1200; // Conservative estimate
|
||||
let imageTokens = 0;
|
||||
|
||||
if (hasImageContent && Array.isArray(messages)) {
|
||||
// Count images in the request
|
||||
for (const msg of messages) {
|
||||
if (Array.isArray(msg.content)) {
|
||||
const imageCount = msg.content.filter(
|
||||
(item: ContentItem) => item.type === "image_url"
|
||||
).length;
|
||||
imageTokens += imageCount * TOKENS_PER_IMAGE;
|
||||
}
|
||||
}
|
||||
|
||||
req.log.debug(
|
||||
{ imageCount: imageTokens / TOKENS_PER_IMAGE, tokenEstimate: imageTokens },
|
||||
"Estimated token count for Mistral vision images"
|
||||
);
|
||||
}
|
||||
|
||||
const prompt: string | MistralAIChatMessage[] = messages ?? req.body.prompt;
|
||||
result = await countTokens({ req, prompt, service });
|
||||
|
||||
// Add the image tokens to the total count
|
||||
if (imageTokens > 0) {
|
||||
result.token_count += imageTokens;
|
||||
}
|
||||
|
||||
break;
|
||||
}
|
||||
case "openai-image": {
|
||||
req.outputTokens = 1;
|
||||
result = await countTokens({ req, service });
|
||||
break;
|
||||
}
|
||||
|
||||
// Handle XAI (Grok) vision models
|
||||
// Since it uses the OpenAI API format, it's caught in the "openai" case,
|
||||
// but we need to add additional handling for image tokens after that
|
||||
default:
|
||||
assertNever(service);
|
||||
}
|
||||
|
||||
req.promptTokens = result.token_count;
|
||||
|
||||
req.log.debug({ result: result }, "Counted prompt tokens.");
|
||||
req.tokenizerInfo = req.tokenizerInfo ?? {};
|
||||
req.tokenizerInfo = { ...req.tokenizerInfo, ...result };
|
||||
};
|
||||
@@ -0,0 +1,81 @@
|
||||
import { Request } from "express";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
/**
|
||||
* Extracts Qwen-specific parameters from `extra_body` and merges them into the main request body.
|
||||
* This enables compatibility with OpenAI SDK users who pass Qwen parameters via `extra_body`.
|
||||
*
|
||||
* For example:
|
||||
* ```
|
||||
* {
|
||||
* "model": "qwen-plus",
|
||||
* "messages": [...],
|
||||
* "extra_body": {
|
||||
* "enable_thinking": true,
|
||||
* "thinking_budget": 10000
|
||||
* }
|
||||
* }
|
||||
* ```
|
||||
*
|
||||
* Becomes:
|
||||
* ```
|
||||
* {
|
||||
* "model": "qwen-plus",
|
||||
* "messages": [...],
|
||||
* "enable_thinking": true,
|
||||
* "thinking_budget": 10000
|
||||
* }
|
||||
* ```
|
||||
*/
|
||||
export const extractQwenExtraBody: RequestPreprocessor = async (req: Request) => {
|
||||
// Only process requests for Qwen service
|
||||
if (req.service !== "qwen") {
|
||||
return;
|
||||
}
|
||||
|
||||
// Check if extra_body exists and is an object
|
||||
if (!req.body.extra_body || typeof req.body.extra_body !== "object") {
|
||||
return;
|
||||
}
|
||||
|
||||
const extraBody = req.body.extra_body;
|
||||
let extractedParams: string[] = [];
|
||||
|
||||
// Define Qwen-specific parameters that can be extracted from extra_body
|
||||
const qwenParameters = [
|
||||
"enable_thinking",
|
||||
"thinking_budget",
|
||||
"modalities",
|
||||
"audio",
|
||||
"translation_options",
|
||||
] as const;
|
||||
|
||||
// Extract Qwen-specific parameters from extra_body
|
||||
for (const param of qwenParameters) {
|
||||
if (param in extraBody) {
|
||||
// Always merge parameters from extra_body, but log if there's a conflict
|
||||
if (param in req.body) {
|
||||
req.log.debug(
|
||||
{ param, mainValue: req.body[param], extraValue: extraBody[param] },
|
||||
"Parameter exists in both main body and extra_body, prioritizing extra_body value"
|
||||
);
|
||||
}
|
||||
req.body[param] = extraBody[param];
|
||||
extractedParams.push(param);
|
||||
}
|
||||
}
|
||||
|
||||
// Remove extra_body to avoid passing it to the API
|
||||
delete req.body.extra_body;
|
||||
|
||||
// Log the extraction for debugging
|
||||
if (extractedParams.length > 0) {
|
||||
req.log.info(
|
||||
{
|
||||
extractedParams,
|
||||
model: req.body.model
|
||||
},
|
||||
"Extracted Qwen parameters from extra_body"
|
||||
);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,95 @@
|
||||
import { Request } from "express";
|
||||
import { z } from "zod";
|
||||
import { config } from "../../../../config";
|
||||
import { assertNever } from "../../../../shared/utils";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
import { BadRequestError } from "../../../../shared/errors";
|
||||
import {
|
||||
MistralAIChatMessage,
|
||||
OpenAIChatMessage,
|
||||
flattenAnthropicMessages,
|
||||
} from "../../../../shared/api-schemas";
|
||||
import { GoogleAIV1GenerateContentSchema } from "../../../../shared/api-schemas/google-ai";
|
||||
|
||||
const rejectedClients = new Map<string, number>();
|
||||
|
||||
setInterval(() => {
|
||||
rejectedClients.forEach((count, ip) => {
|
||||
if (count > 0) {
|
||||
rejectedClients.set(ip, Math.floor(count / 2));
|
||||
} else {
|
||||
rejectedClients.delete(ip);
|
||||
}
|
||||
});
|
||||
}, 30000);
|
||||
|
||||
/**
|
||||
* Block requests containing blacklisted phrases. Repeated rejections from the
|
||||
* same IP address will be throttled.
|
||||
*/
|
||||
export const languageFilter: RequestPreprocessor = async (req) => {
|
||||
if (!config.rejectPhrases.length) return;
|
||||
|
||||
const prompt = getPromptFromRequest(req);
|
||||
const match = config.rejectPhrases.find((phrase) =>
|
||||
prompt.match(new RegExp(phrase, "i"))
|
||||
);
|
||||
|
||||
if (match) {
|
||||
const ip = req.ip;
|
||||
const rejections = (rejectedClients.get(req.ip) || 0) + 1;
|
||||
const delay = Math.min(60000, Math.pow(2, rejections - 1) * 1000);
|
||||
rejectedClients.set(ip, rejections);
|
||||
req.log.warn(
|
||||
{ match, ip, rejections, delay },
|
||||
"Prompt contains rejected phrase"
|
||||
);
|
||||
await new Promise((resolve) => {
|
||||
req.res!.once("close", resolve);
|
||||
setTimeout(resolve, delay);
|
||||
});
|
||||
throw new BadRequestError(config.rejectMessage);
|
||||
}
|
||||
};
|
||||
|
||||
/*
|
||||
TODO: this is not type safe and does not raise errors if request body zod schema
|
||||
is changed.
|
||||
*/
|
||||
function getPromptFromRequest(req: Request) {
|
||||
const service = req.outboundApi;
|
||||
const body = req.body;
|
||||
switch (service) {
|
||||
case "anthropic-chat":
|
||||
return flattenAnthropicMessages(body.messages);
|
||||
case "openai":
|
||||
case "mistral-ai":
|
||||
return body.messages
|
||||
.map((msg: OpenAIChatMessage | MistralAIChatMessage) => {
|
||||
const text = Array.isArray(msg.content)
|
||||
? msg.content
|
||||
.map((c) => {
|
||||
if ("text" in c) return c.text;
|
||||
})
|
||||
.join()
|
||||
: msg.content;
|
||||
return `${msg.role}: ${text}`;
|
||||
})
|
||||
.join("\n\n");
|
||||
case "anthropic-text":
|
||||
case "openai-text":
|
||||
case "openai-responses":
|
||||
case "openai-image":
|
||||
case "mistral-text":
|
||||
return body.prompt;
|
||||
case "google-ai": {
|
||||
const b = body as z.infer<typeof GoogleAIV1GenerateContentSchema>;
|
||||
return [
|
||||
b.systemInstruction?.parts.filter(p => 'text' in p).map((p) => (p as { text: string }).text),
|
||||
...b.contents.flatMap((c) => c.parts.filter(p => 'text' in p).map((p) => (p as { text: string }).text)),
|
||||
].join("\n");
|
||||
}
|
||||
default:
|
||||
assertNever(service);
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,30 @@
|
||||
import { Request } from "express";
|
||||
import { APIFormat } from "../../../../shared/key-management";
|
||||
import { LLMService } from "../../../../shared/models";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
export const setApiFormat = (api: {
|
||||
/**
|
||||
* The API format the user made the request in and expects the response to be
|
||||
* in.
|
||||
*/
|
||||
inApi: Request["inboundApi"];
|
||||
/**
|
||||
* The API format the proxy will make the request in and expects the response
|
||||
* to be in. If different from `inApi`, the proxy will transform the user's
|
||||
* request body to this format, and will transform the response body or stream
|
||||
* events from this format.
|
||||
*/
|
||||
outApi: APIFormat;
|
||||
/**
|
||||
* The service the request will be sent to, which determines authentication
|
||||
* and possibly the streaming transport.
|
||||
*/
|
||||
service: LLMService;
|
||||
}): RequestPreprocessor => {
|
||||
return function configureRequestApiFormat(req) {
|
||||
req.inboundApi = api.inApi;
|
||||
req.outboundApi = api.outApi;
|
||||
req.service = api.service;
|
||||
};
|
||||
};
|
||||
@@ -0,0 +1,237 @@
|
||||
import { Request } from "express";
|
||||
import {
|
||||
API_REQUEST_VALIDATORS,
|
||||
API_REQUEST_TRANSFORMERS,
|
||||
} from "../../../../shared/api-schemas";
|
||||
import { BadRequestError } from "../../../../shared/errors";
|
||||
import { fixMistralPrompt, isMistralVisionModel } from "../../../../shared/api-schemas/mistral-ai";
|
||||
import {
|
||||
isImageGenerationRequest,
|
||||
isTextGenerationRequest,
|
||||
} from "../../common";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
/** Transforms an incoming request body to one that matches the target API. */
|
||||
export const transformOutboundPayload: RequestPreprocessor = async (req) => {
|
||||
const alreadyTransformed = req.retryCount > 0;
|
||||
const notTransformable =
|
||||
!isTextGenerationRequest(req) && !isImageGenerationRequest(req);
|
||||
|
||||
if (alreadyTransformed) {
|
||||
return;
|
||||
} else if (notTransformable) {
|
||||
// This is probably an indication of a bug in the proxy.
|
||||
const { inboundApi, outboundApi, method, path } = req;
|
||||
req.log.warn(
|
||||
{ inboundApi, outboundApi, method, path },
|
||||
"`transformOutboundPayload` called on a non-transformable request."
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
applyMistralPromptFixes(req);
|
||||
applyGoogleAIKeyTransforms(req);
|
||||
applyOpenAIResponsesTransform(req);
|
||||
|
||||
// Native prompts are those which were already provided by the client in the
|
||||
// target API format. We don't need to transform them.
|
||||
const isNativePrompt = req.inboundApi === req.outboundApi;
|
||||
if (isNativePrompt) {
|
||||
const result = API_REQUEST_VALIDATORS[req.inboundApi].parse(req.body);
|
||||
req.body = result;
|
||||
return;
|
||||
}
|
||||
|
||||
// Prompt requires translation from one API format to another.
|
||||
const transformation = `${req.inboundApi}->${req.outboundApi}` as const;
|
||||
const transFn = API_REQUEST_TRANSFORMERS[transformation];
|
||||
|
||||
if (transFn) {
|
||||
req.log.info({ transformation }, "Transforming request...");
|
||||
req.body = await transFn(req);
|
||||
return;
|
||||
}
|
||||
|
||||
throw new BadRequestError(
|
||||
`${transformation} proxying is not supported. Make sure your client is configured to send requests in the correct format and to the correct endpoint.`
|
||||
);
|
||||
};
|
||||
|
||||
// Handle OpenAI Responses API transformation
|
||||
function applyOpenAIResponsesTransform(req: Request): void {
|
||||
if (req.outboundApi === "openai-responses") {
|
||||
req.log.info("Transforming request to OpenAI Responses API format");
|
||||
|
||||
// Store the original body for reference if needed
|
||||
const originalBody = { ...req.body };
|
||||
|
||||
// Map standard OpenAI chat completions format to Responses API format
|
||||
// The main differences are:
|
||||
// 1. Endpoint is /v1/responses instead of /v1/chat/completions
|
||||
// 2. 'messages' field moves to 'input.messages'
|
||||
|
||||
// Move messages to input.messages
|
||||
if (req.body.messages && !req.body.input) {
|
||||
req.body.input = {
|
||||
messages: req.body.messages
|
||||
};
|
||||
delete req.body.messages;
|
||||
}
|
||||
|
||||
// Keep all the original properties of the request but ensure compatibility
|
||||
// with Responses API specifics
|
||||
if (!req.body.previousResponseId && req.body.conversation_id) {
|
||||
req.body.previousResponseId = req.body.conversation_id;
|
||||
delete req.body.conversation_id;
|
||||
}
|
||||
|
||||
// Convert max_tokens to max_output_tokens if present and not already set
|
||||
if (req.body.max_tokens && !req.body.max_output_tokens) {
|
||||
req.body.max_output_tokens = req.body.max_tokens;
|
||||
delete req.body.max_tokens;
|
||||
}
|
||||
|
||||
// Set the correct tools format if needed
|
||||
if (req.body.tools) {
|
||||
// Tools structure is maintained but might need conversion if non-standard
|
||||
if (!req.body.tools.some((tool: any) => tool.type === "function" || tool.type === "web_search")) {
|
||||
req.body.tools = req.body.tools.map((tool: any) => ({
|
||||
...tool,
|
||||
type: tool.type || "function"
|
||||
}));
|
||||
}
|
||||
}
|
||||
|
||||
req.log.info({
|
||||
originalModel: originalBody.model,
|
||||
newFormat: "openai-responses"
|
||||
}, "Successfully transformed request to Responses API format");
|
||||
}
|
||||
}
|
||||
|
||||
// handles weird cases that don't fit into our abstractions
|
||||
function applyMistralPromptFixes(req: Request): void {
|
||||
if (req.inboundApi === "mistral-ai") {
|
||||
// Mistral Chat is very similar to OpenAI but not identical and many clients
|
||||
// don't properly handle the differences. We will try to validate the
|
||||
// mistral prompt and try to fix it if it fails. It will be re-validated
|
||||
// after this function returns.
|
||||
const result = API_REQUEST_VALIDATORS["mistral-ai"].parse(req.body);
|
||||
|
||||
// Check if this is a vision model request
|
||||
const isVisionModel = isMistralVisionModel(req.body.model);
|
||||
|
||||
// Check if the request contains image content
|
||||
const hasImageContent = result.messages?.some((msg: {content: string | any[]}) =>
|
||||
Array.isArray(msg.content) &&
|
||||
msg.content.some((item: any) => item.type === "image_url")
|
||||
);
|
||||
|
||||
// For vision requests, normalize the image_url format
|
||||
if (hasImageContent && Array.isArray(result.messages)) {
|
||||
// Process each message with image content
|
||||
result.messages.forEach((msg: any) => {
|
||||
if (Array.isArray(msg.content)) {
|
||||
// Process each content item
|
||||
msg.content.forEach((item: any) => {
|
||||
if (item.type === "image_url") {
|
||||
// Normalize the image_url field to a string format that Mistral expects
|
||||
if (typeof item.image_url === "object") {
|
||||
// If it's an object, extract the URL or base64 data
|
||||
if (item.image_url.url) {
|
||||
item.image_url = item.image_url.url;
|
||||
} else if (item.image_url.data) {
|
||||
item.image_url = item.image_url.data;
|
||||
}
|
||||
|
||||
req.log.info(
|
||||
{ model: req.body.model },
|
||||
"Normalized object-format image_url to string format"
|
||||
);
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
// Apply Mistral prompt fixes while preserving multimodal content
|
||||
req.body.messages = fixMistralPrompt(result.messages);
|
||||
req.log.info(
|
||||
{
|
||||
n: req.body.messages.length,
|
||||
prev: result.messages.length,
|
||||
isVisionModel,
|
||||
hasImageContent
|
||||
},
|
||||
"Applied Mistral chat prompt fixes."
|
||||
);
|
||||
|
||||
// If this is a vision model with image content, it MUST use the chat API
|
||||
// and cannot be converted to text completions
|
||||
if (hasImageContent) {
|
||||
req.log.info(
|
||||
{ model: req.body.model },
|
||||
"Detected Mistral vision request with image content. Keeping as chat format."
|
||||
);
|
||||
return;
|
||||
}
|
||||
|
||||
// If the prompt relies on `prefix: true` for the last message, we need to
|
||||
// convert it to a text completions request because AWS Mistral support for
|
||||
// this feature is broken.
|
||||
// On Mistral La Plateforme, we can't do this because they don't expose
|
||||
// a text completions endpoint.
|
||||
const { messages } = req.body;
|
||||
const lastMessage = messages && messages[messages.length - 1];
|
||||
if (lastMessage?.role === "assistant" && req.service === "aws") {
|
||||
// enable prefix if client forgot, otherwise the template will insert an
|
||||
// eos token which is very unlikely to be what the client wants.
|
||||
lastMessage.prefix = true;
|
||||
req.outboundApi = "mistral-text";
|
||||
req.log.info(
|
||||
"Native Mistral chat prompt relies on assistant message prefix. Converting to text completions request."
|
||||
);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function toCamelCase(str: string): string {
|
||||
return str.replace(/_([a-z])/g, (_, letter) => letter.toUpperCase());
|
||||
}
|
||||
|
||||
function transformKeysToCamelCase(obj: any, hasTransformed = { value: false }): any {
|
||||
if (Array.isArray(obj)) {
|
||||
return obj.map(item => transformKeysToCamelCase(item, hasTransformed));
|
||||
}
|
||||
|
||||
if (obj !== null && typeof obj === 'object') {
|
||||
return Object.fromEntries(
|
||||
Object.entries(obj).map(([key, value]) => {
|
||||
const camelKey = toCamelCase(key);
|
||||
if (camelKey !== key) {
|
||||
hasTransformed.value = true;
|
||||
}
|
||||
return [
|
||||
camelKey,
|
||||
transformKeysToCamelCase(value, hasTransformed)
|
||||
];
|
||||
})
|
||||
);
|
||||
}
|
||||
|
||||
return obj;
|
||||
}
|
||||
|
||||
function applyGoogleAIKeyTransforms(req: Request): void {
|
||||
// Google (Gemini) API in their infinite wisdom accepts both snake_case and camelCase
|
||||
// for some params even though in the docs they use snake_case.
|
||||
// Some frontends (e.g. ST) use snake_case and camelCase so we normalize all keys to camelCase
|
||||
if (req.outboundApi === "google-ai") {
|
||||
const hasTransformed = { value: false };
|
||||
req.body = transformKeysToCamelCase(req.body, hasTransformed);
|
||||
if (hasTransformed.value) {
|
||||
req.log.info("Applied Gemini camelCase -> snake_case transform");
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,202 @@
|
||||
import { Request } from "express";
|
||||
import { z } from "zod";
|
||||
import { config } from "../../../../config";
|
||||
import { assertNever } from "../../../../shared/utils";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
const CLAUDE_MAX_CONTEXT = config.maxContextTokensAnthropic;
|
||||
const OPENAI_MAX_CONTEXT = config.maxContextTokensOpenAI;
|
||||
// todo: make configurable
|
||||
const GOOGLE_AI_MAX_CONTEXT = 2048000;
|
||||
const MISTRAL_AI_MAX_CONTENT = 131072;
|
||||
|
||||
/**
|
||||
* Assigns `req.promptTokens` and `req.outputTokens` based on the request body
|
||||
* and outbound API format, which combined determine the size of the context.
|
||||
* If the context is too large, an error is thrown.
|
||||
* This preprocessor should run after any preprocessor that transforms the
|
||||
* request body.
|
||||
*/
|
||||
export const validateContextSize: RequestPreprocessor = async (req) => {
|
||||
assertRequestHasTokenCounts(req);
|
||||
const promptTokens = req.promptTokens;
|
||||
const outputTokens = req.outputTokens;
|
||||
const contextTokens = promptTokens + outputTokens;
|
||||
const model = req.body.model;
|
||||
|
||||
let proxyMax: number;
|
||||
switch (req.outboundApi) {
|
||||
case "openai":
|
||||
case "openai-text":
|
||||
case "openai-responses":
|
||||
proxyMax = OPENAI_MAX_CONTEXT;
|
||||
break;
|
||||
case "anthropic-chat":
|
||||
case "anthropic-text":
|
||||
proxyMax = CLAUDE_MAX_CONTEXT;
|
||||
break;
|
||||
case "google-ai":
|
||||
proxyMax = GOOGLE_AI_MAX_CONTEXT;
|
||||
break;
|
||||
case "mistral-ai":
|
||||
case "mistral-text":
|
||||
proxyMax = MISTRAL_AI_MAX_CONTENT;
|
||||
break;
|
||||
case "openai-image":
|
||||
return;
|
||||
default:
|
||||
assertNever(req.outboundApi);
|
||||
}
|
||||
proxyMax ||= Number.MAX_SAFE_INTEGER;
|
||||
|
||||
if (req.user?.type === "special") {
|
||||
req.log.debug("Special user, not enforcing proxy context limit.");
|
||||
proxyMax = Number.MAX_SAFE_INTEGER;
|
||||
}
|
||||
|
||||
let modelMax: number;
|
||||
if (model.match(/gpt-3.5-turbo-16k/)) {
|
||||
modelMax = 16384;
|
||||
} else if (model.match(/^gpt-4o/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/^gpt-4.5/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/^gpt-4\.1(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 1000000;
|
||||
} else if (model.match(/^gpt-4\.1-mini(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 1000000;
|
||||
} else if (model.match(/^gpt-4\.1-nano(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 1000000;
|
||||
} else if (model.match(/^gpt-5(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 400000;
|
||||
} else if (model.match(/^gpt-5-mini(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 400000;
|
||||
} else if (model.match(/^gpt-5-nano(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 400000;
|
||||
} else if (model.match(/^gpt-5-chat-latest$/)) {
|
||||
modelMax = 400000;
|
||||
} else if (model.match(/^chatgpt-4o/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/gpt-4-turbo(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 131072;
|
||||
} else if (model.match(/gpt-4-turbo(-preview)?$/)) {
|
||||
modelMax = 131072;
|
||||
} else if (model.match(/gpt-4-(0125|1106)(-preview)?$/)) {
|
||||
modelMax = 131072;
|
||||
} else if (model.match(/^gpt-4(-\d{4})?-vision(-preview)?$/)) {
|
||||
modelMax = 131072;
|
||||
} else if (model.match(/^o3-mini(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^o3(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^o4-mini(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^codex-mini(-latest|-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000; // 200k context window for codex-mini-latest
|
||||
} else if (model.match(/^o1(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^o1-mini(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/^o1-pro(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^o3-pro(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^o1-preview(-\d{4}-\d{2}-\d{2})?$/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/gpt-3.5-turbo/)) {
|
||||
modelMax = 16384;
|
||||
} else if (model.match(/gpt-4-32k/)) {
|
||||
modelMax = 32768;
|
||||
} else if (model.match(/gpt-4/)) {
|
||||
modelMax = 8192;
|
||||
} else if (model.match(/^claude-(?:instant-)?v1(?:\.\d)?-100k/)) {
|
||||
modelMax = 100000;
|
||||
} else if (model.match(/^claude-(?:instant-)?v1(?:\.\d)?$/)) {
|
||||
modelMax = 9000;
|
||||
} else if (model.match(/^claude-2\.0/)) {
|
||||
modelMax = 100000;
|
||||
} else if (model.match(/^claude-2/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^claude-3/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^claude-(?:sonnet|opus)-4/)) {
|
||||
modelMax = 1000000;
|
||||
} else if (model.match(/^gemini-/)) {
|
||||
modelMax = 1024000;
|
||||
} else if (model.match(/^anthropic\.claude-3/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^anthropic\.claude-(?:sonnet|opus)-4/)) {
|
||||
modelMax = 1000000;
|
||||
} else if (model.match(/^anthropic\.claude-v2:\d/)) {
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/^anthropic\.claude/)) {
|
||||
modelMax = 100000;
|
||||
} else if (model.match(/^deepseek/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/^kimi-k2/)) {
|
||||
// Kimi K2 models have 245k context window
|
||||
modelMax = 245000;
|
||||
} else if (model.match(/moonshot/)) {
|
||||
// Moonshot models typically have 200k context window
|
||||
modelMax = 200000;
|
||||
} else if (model.match(/command[\w-]*-03-202[0-9]/)) {
|
||||
// Cohere's command-a-03 models have 256k context window
|
||||
modelMax = 256000;
|
||||
} else if (model.match(/command/) || model.match(/cohere/)) {
|
||||
// Default for all other Cohere models
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/^qwen/)) {
|
||||
// Qwen models have 256k context window
|
||||
modelMax = 256000;
|
||||
} else if (model.match(/^glm/)) {
|
||||
// GLM models have 131k context window
|
||||
modelMax = 131000;
|
||||
} else if (model.match(/^grok-4/)) {
|
||||
modelMax = 256000;
|
||||
} else if (model.match(/^grok-4-fast/)) {
|
||||
modelMax = 2000000;
|
||||
} else if (model.match(/^grok/)) {
|
||||
modelMax = 128000;
|
||||
} else if (model.match(/^magistral/)) {
|
||||
modelMax = 40000;
|
||||
} else if (model.match(/tral/)) {
|
||||
// catches mistral, mixtral, codestral, mathstral, etc. mistral models have
|
||||
// no name convention and wildly different context windows so this is a
|
||||
// catch-all
|
||||
modelMax = MISTRAL_AI_MAX_CONTENT;
|
||||
} else {
|
||||
req.log.warn({ model }, "Unknown model, using 200k token limit.");
|
||||
modelMax = 200000;
|
||||
}
|
||||
|
||||
const finalMax = Math.min(proxyMax, modelMax);
|
||||
z.object({
|
||||
tokens: z
|
||||
.number()
|
||||
.int()
|
||||
.max(finalMax, {
|
||||
message: `Your request exceeds the context size limit. (max: ${finalMax} tokens, requested: ${promptTokens} prompt + ${outputTokens} output = ${contextTokens} context tokens)`,
|
||||
}),
|
||||
}).parse({ tokens: contextTokens });
|
||||
|
||||
req.log.debug(
|
||||
{ promptTokens, outputTokens, contextTokens, modelMax, proxyMax },
|
||||
"Prompt size validated"
|
||||
);
|
||||
|
||||
req.tokenizerInfo.prompt_tokens = promptTokens;
|
||||
req.tokenizerInfo.completion_tokens = outputTokens;
|
||||
req.tokenizerInfo.max_model_tokens = modelMax;
|
||||
req.tokenizerInfo.max_proxy_tokens = proxyMax;
|
||||
};
|
||||
|
||||
function assertRequestHasTokenCounts(
|
||||
req: Request
|
||||
): asserts req is Request & { promptTokens: number; outputTokens: number } {
|
||||
z.object({
|
||||
promptTokens: z.number().int().min(1),
|
||||
outputTokens: z.number().int().min(1),
|
||||
})
|
||||
.nonstrict()
|
||||
.parse({ promptTokens: req.promptTokens, outputTokens: req.outputTokens });
|
||||
}
|
||||
@@ -0,0 +1,16 @@
|
||||
import { config } from "../../../../config";
|
||||
import { ForbiddenError } from "../../../../shared/errors";
|
||||
import { getModelFamilyForRequest } from "../../../../shared/models";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
|
||||
/**
|
||||
* Ensures the selected model family is enabled by the proxy configuration.
|
||||
*/
|
||||
export const validateModelFamily: RequestPreprocessor = (req) => {
|
||||
const family = getModelFamilyForRequest(req);
|
||||
if (!config.allowedModelFamilies.includes(family)) {
|
||||
throw new ForbiddenError(
|
||||
`Model family '${family}' is not enabled on this proxy`
|
||||
);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,50 @@
|
||||
import { config } from "../../../../config";
|
||||
import { assertNever } from "../../../../shared/utils";
|
||||
import { RequestPreprocessor } from "../index";
|
||||
import { containsImageContent as containsImageContentOpenAI } from "../../../../shared/api-schemas/openai";
|
||||
import { containsImageContent as containsImageContentAnthropic } from "../../../../shared/api-schemas/anthropic";
|
||||
import { containsImageContent as containsImageContentGoogleAI } from "../../../../shared/api-schemas/google-ai";
|
||||
import { ForbiddenError } from "../../../../shared/errors";
|
||||
|
||||
/**
|
||||
* Rejects prompts containing images if multimodal prompts are disabled.
|
||||
*/
|
||||
export const validateVision: RequestPreprocessor = async (req) => {
|
||||
if (req.service === undefined) {
|
||||
throw new Error("Request service must be set before validateVision");
|
||||
}
|
||||
|
||||
if (req.user?.type === "special") return;
|
||||
if (config.allowedVisionServices.includes(req.service)) return;
|
||||
|
||||
// vision not allowed for req's service, block prompts with images
|
||||
let hasImage = false;
|
||||
switch (req.outboundApi) {
|
||||
case "openai":
|
||||
hasImage = containsImageContentOpenAI(req.body.messages);
|
||||
break;
|
||||
case "openai-responses":
|
||||
hasImage = containsImageContentOpenAI(req.body.messages);
|
||||
break;
|
||||
case "anthropic-chat":
|
||||
hasImage = containsImageContentAnthropic(req.body.messages);
|
||||
break;
|
||||
case "google-ai":
|
||||
hasImage = containsImageContentGoogleAI(req.body.contents);
|
||||
break;
|
||||
case "anthropic-text":
|
||||
case "mistral-ai":
|
||||
case "mistral-text":
|
||||
case "openai-image":
|
||||
case "openai-text":
|
||||
return;
|
||||
default:
|
||||
assertNever(req.outboundApi);
|
||||
}
|
||||
|
||||
if (hasImage) {
|
||||
throw new ForbiddenError(
|
||||
"Prompts containing images are not permitted. Disable 'Send Inline Images' in your client and try again."
|
||||
);
|
||||
}
|
||||
};
|
||||
@@ -0,0 +1,135 @@
|
||||
import { Request, Response } from "express";
|
||||
import http from "http";
|
||||
import ProxyServer from "http-proxy";
|
||||
import { Readable } from "stream";
|
||||
import {
|
||||
createProxyMiddleware,
|
||||
Options,
|
||||
debugProxyErrorsPlugin,
|
||||
proxyEventsPlugin,
|
||||
} from "http-proxy-middleware";
|
||||
import { ProxyReqMutator, stripHeaders } from "./index";
|
||||
import { createOnProxyResHandler, ProxyResHandlerWithBody } from "../response";
|
||||
import { createQueueMiddleware } from "../../queue";
|
||||
import { getHttpAgents } from "../../../shared/network";
|
||||
import { classifyErrorAndSend } from "../common";
|
||||
|
||||
/**
|
||||
* Options for the `createQueuedProxyMiddleware` factory function.
|
||||
*/
|
||||
type ProxyMiddlewareFactoryOptions = {
|
||||
/**
|
||||
* Functions which receive a ProxyReqManager and can modify the request before
|
||||
* it is proxied. The modifications will be automatically reverted if the
|
||||
* request needs to be returned to the queue.
|
||||
*/
|
||||
mutations?: ProxyReqMutator[];
|
||||
/**
|
||||
* The target URL to proxy requests to. This can be a string or a function
|
||||
* which accepts the request and returns a string.
|
||||
*/
|
||||
target: string | Options<Request>["router"];
|
||||
/**
|
||||
* A function which receives the proxy response and the JSON-decoded request
|
||||
* body. Only fired for non-streaming responses; streaming responses are
|
||||
* handled in `handle-streaming-response.ts`.
|
||||
*/
|
||||
blockingResponseHandler?: ProxyResHandlerWithBody;
|
||||
};
|
||||
|
||||
/**
|
||||
* Returns a middleware function that accepts incoming requests and places them
|
||||
* into the request queue. When the request is dequeued, it is proxied to the
|
||||
* target URL using the given options and middleware. Non-streaming responses
|
||||
* are handled by the given `blockingResponseHandler`.
|
||||
*/
|
||||
export function createQueuedProxyMiddleware({
|
||||
target,
|
||||
mutations,
|
||||
blockingResponseHandler,
|
||||
}: ProxyMiddlewareFactoryOptions) {
|
||||
const hpmTarget = typeof target === "string" ? target : "https://setbyrouter";
|
||||
const hpmRouter = typeof target === "function" ? target : undefined;
|
||||
|
||||
const [httpAgent, httpsAgent] = getHttpAgents();
|
||||
const agent = hpmTarget.startsWith("http:") ? httpAgent : httpsAgent;
|
||||
|
||||
const proxyMiddleware = createProxyMiddleware<Request, Response>({
|
||||
target: hpmTarget,
|
||||
router: hpmRouter,
|
||||
agent,
|
||||
changeOrigin: true,
|
||||
toProxy: true,
|
||||
selfHandleResponse: typeof blockingResponseHandler === "function",
|
||||
// Disable HPM logger plugin (requires re-adding the other default plugins).
|
||||
// Contrary to name, debugProxyErrorsPlugin is not just for debugging and
|
||||
// fixes several error handling/connection close issues in http-proxy core.
|
||||
ejectPlugins: true,
|
||||
// Inferred (via Options<express.Request>) as Plugin<express.Request>, but
|
||||
// the default plugins only allow http.IncomingMessage for TReq. They are
|
||||
// compatible with express.Request, so we can use them. `Plugin` type is not
|
||||
// exported for some reason.
|
||||
plugins: [
|
||||
debugProxyErrorsPlugin,
|
||||
pinoLoggerPlugin,
|
||||
proxyEventsPlugin,
|
||||
] as any,
|
||||
on: {
|
||||
proxyRes: createOnProxyResHandler(
|
||||
blockingResponseHandler ? [blockingResponseHandler] : []
|
||||
),
|
||||
error: classifyErrorAndSend,
|
||||
},
|
||||
buffer: ((req: Request) => {
|
||||
// This is a hack/monkey patch and is not part of the official
|
||||
// http-proxy-middleware package. See patches/http-proxy+1.18.1.patch.
|
||||
let payload = req.body;
|
||||
if (typeof payload === "string") {
|
||||
payload = Buffer.from(payload);
|
||||
}
|
||||
const stream = new Readable();
|
||||
stream.push(payload);
|
||||
stream.push(null);
|
||||
return stream;
|
||||
}) as any,
|
||||
});
|
||||
|
||||
return createQueueMiddleware({
|
||||
mutations: [stripHeaders, ...(mutations ?? [])],
|
||||
proxyMiddleware,
|
||||
});
|
||||
}
|
||||
|
||||
type ProxiedResponse = http.IncomingMessage & Response & any;
|
||||
function pinoLoggerPlugin(proxyServer: ProxyServer<Request>) {
|
||||
proxyServer.on("error", (err, req, res, target) => {
|
||||
req.log.error(
|
||||
{ originalUrl: req.originalUrl, targetUrl: String(target), err },
|
||||
"Error occurred while proxying request to target"
|
||||
);
|
||||
});
|
||||
proxyServer.on("proxyReq", (proxyReq, req) => {
|
||||
const { protocol, host, path } = proxyReq;
|
||||
req.log.info(
|
||||
{
|
||||
from: req.originalUrl,
|
||||
to: `${protocol}//${host}${path}`,
|
||||
},
|
||||
"Sending request to upstream API..."
|
||||
);
|
||||
});
|
||||
proxyServer.on("proxyRes", (proxyRes: ProxiedResponse, req, _res) => {
|
||||
const { protocol, host, path } = proxyRes.req;
|
||||
req.log.info(
|
||||
{
|
||||
target: `${protocol}//${host}${path}`,
|
||||
status: proxyRes.statusCode,
|
||||
contentType: proxyRes.headers["content-type"],
|
||||
contentEncoding: proxyRes.headers["content-encoding"],
|
||||
contentLength: proxyRes.headers["content-length"],
|
||||
transferEncoding: proxyRes.headers["transfer-encoding"],
|
||||
},
|
||||
"Got response from upstream API."
|
||||
);
|
||||
});
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user